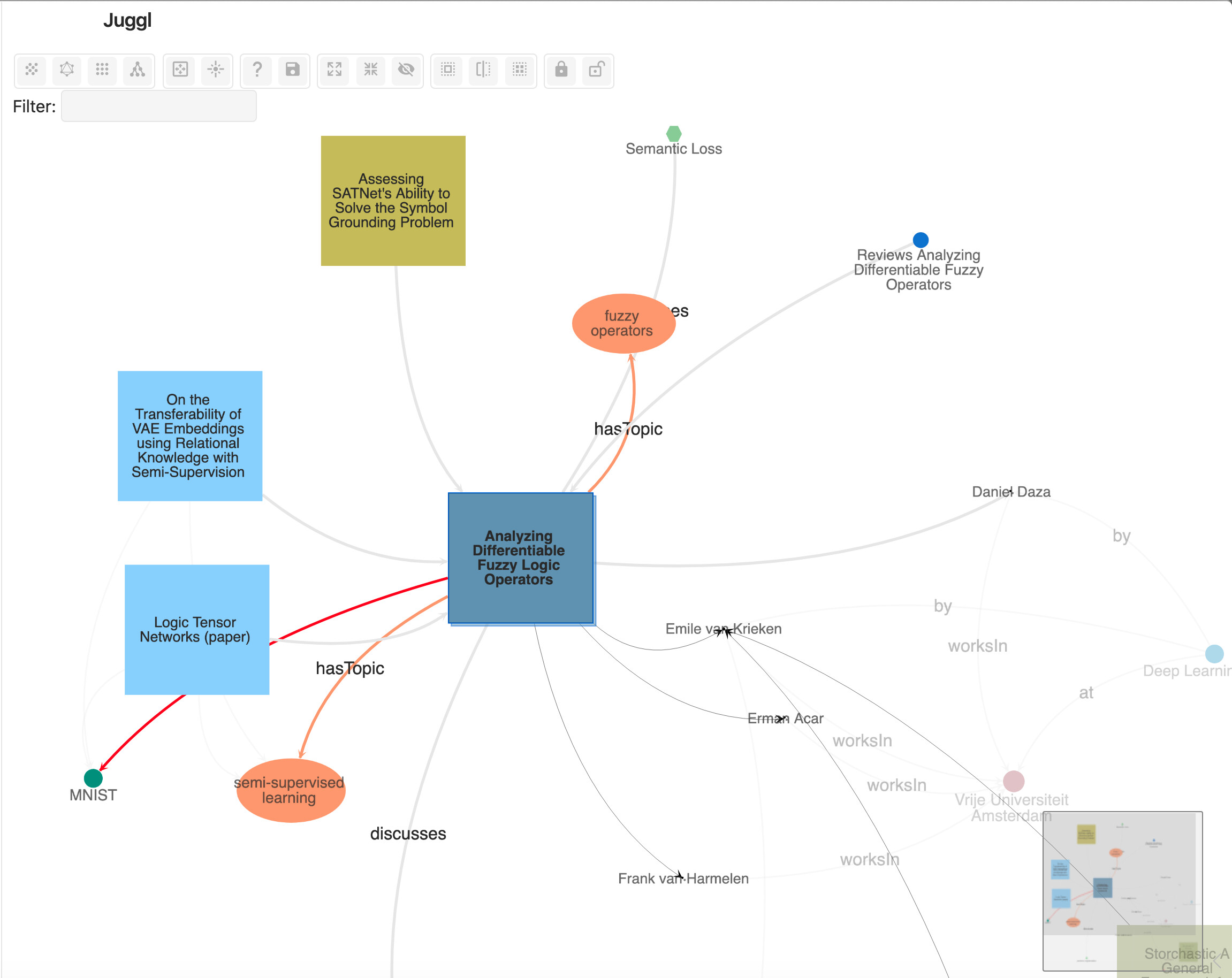
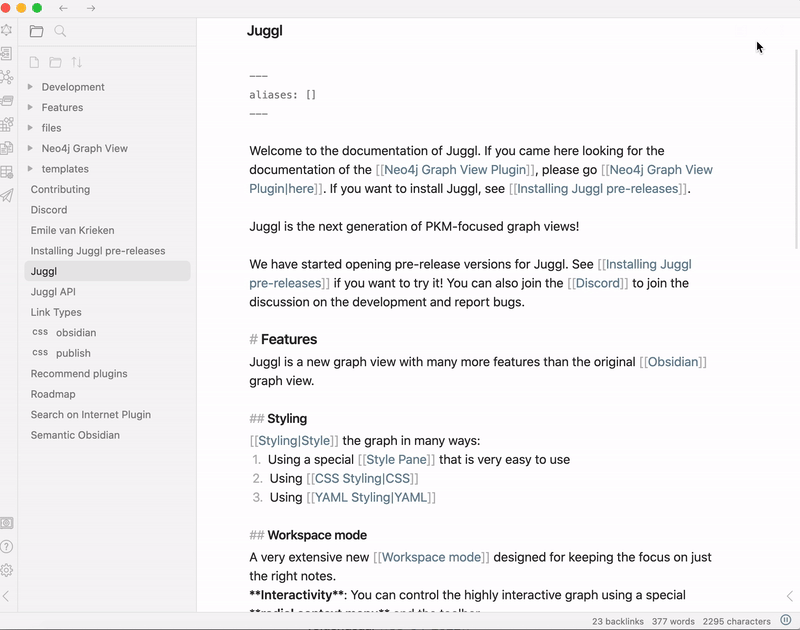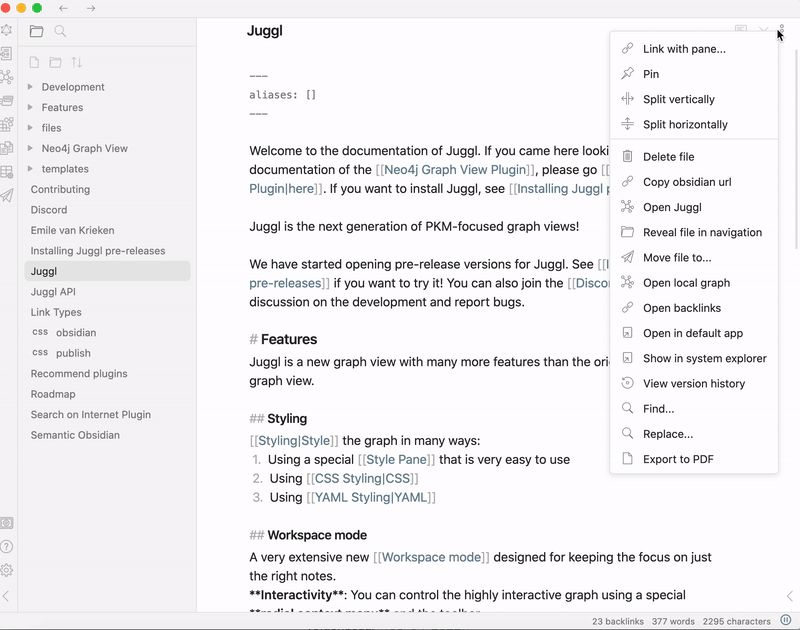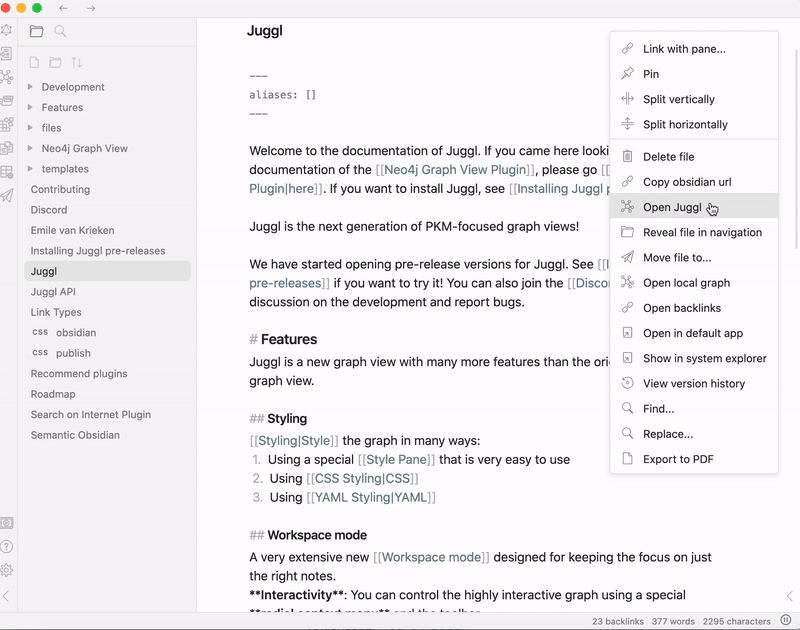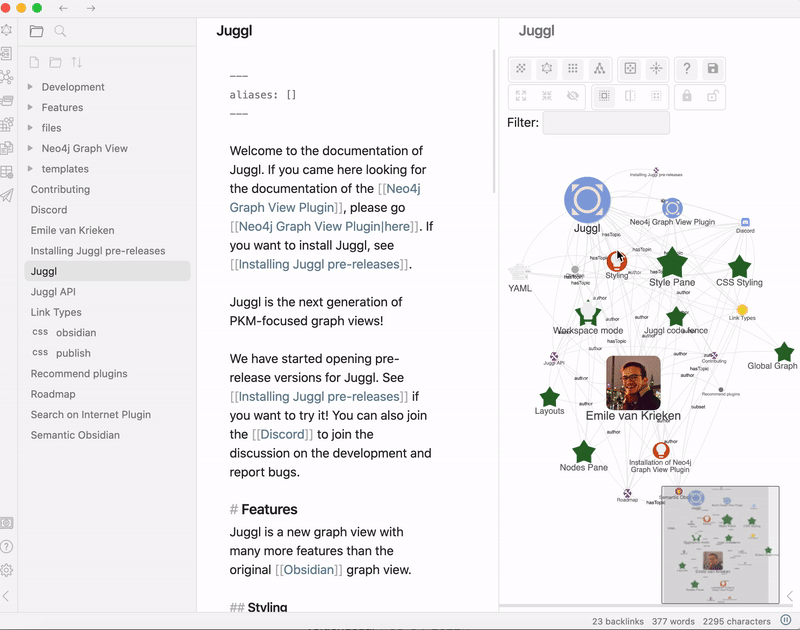
Juggl is a completely interactive, stylable and expandable graph view plugin for Obsidian.
It is designed as an advanced ‘local’ graph view called the ‘workspace’, where you can juggle all your thoughts with ease.
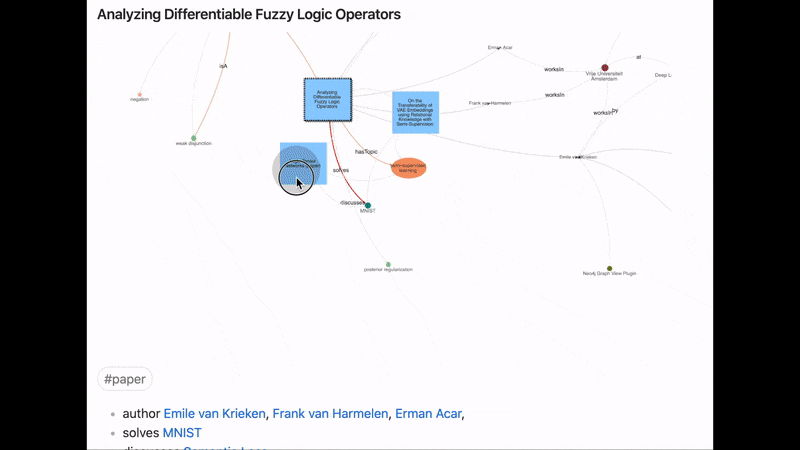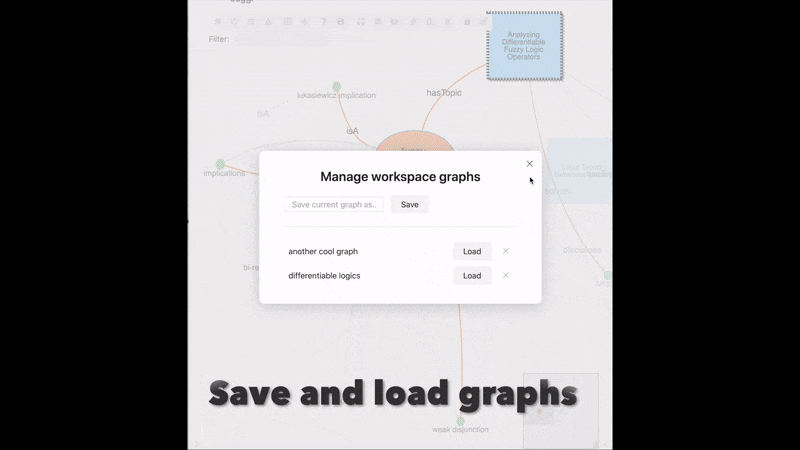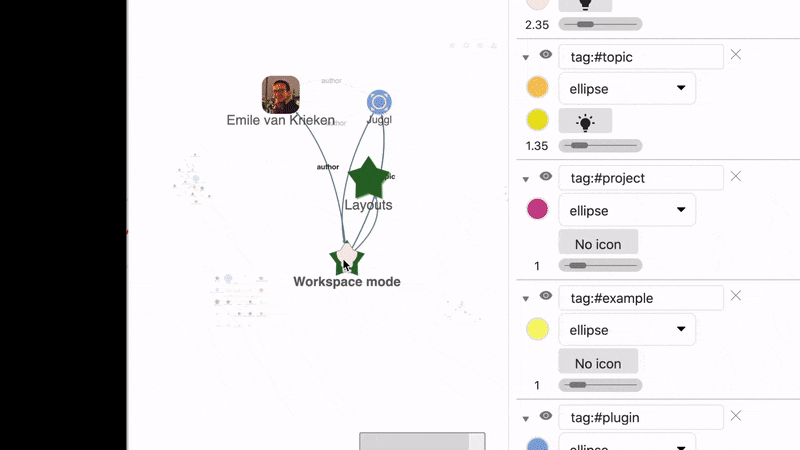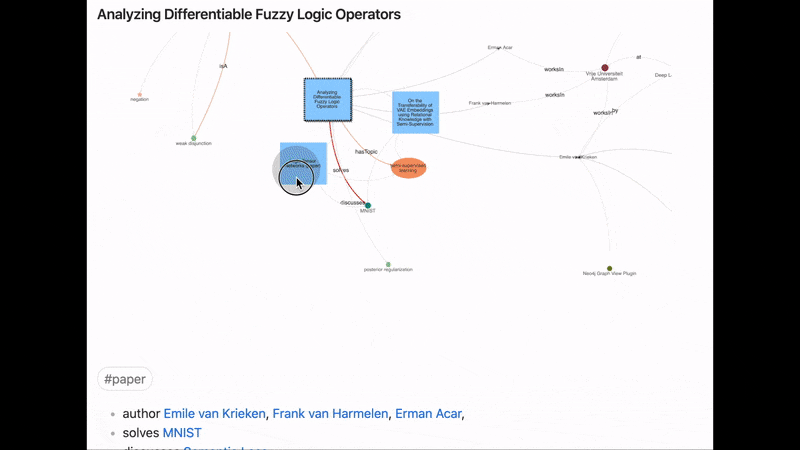
With Juggl, you can navigate Obsidian through a beautiful graph! For example, you can select what parts of the graph to expand, to make sure there is never too much information on the screen.
Juggl is also super-customizable! For starters, it has a useful styling pane nodes colors, shapes, sizes, and icons which helps you get an immediate overview over what the content of each node is.
Features
Juggl has many features unique to its graph view compared to the Obsidian graph view:
Complete control over the style of your graph using CSS, YAML and the Style Pane .
Include images!
A Workspace mode that lets you build your graph with all nodes that are relevant to your current project
Selectively browse and hide nodes, and pin their location so you never lose them
A code fence that displays the graph within Obsidian notes
Link type support to label edges
No need to install Python or Neo4j, unlike Neo4j Graph View
Extendable through other plugins
Works on mobile!
Getting started
You can open Juggl from the ‘more options’ menu on files:
You can interact with the graph with many of the same options as in Obsidian. For further documentation, check out juggl.io, where you can find information on for example styling or the syntax of the code fence.
You can also open the help vault with this button in Juggl:
Hi Emile!.. this is amazing!, well, the idea. I still cannot make it work. I’ve tried two graphs, but it seems my computer doesn’t want to load them. Do you have an example graph to look at?
Thank you Cristian!
You can download the export of the Obsidian help graph here: https://www.dropbox.com/s/5txmnik2v0g393i/out.cypher?dl=0
It seems to import well, but Neo4j Bloom seems to only show 5 nodes for me, for some reason? It works properly in Neo4j desktop though.
Can you explain what problem you’re running into? Or at what step?
Hello, i have tried to follow the instructions, i installed Python 3.9.1 (restarted the computer after) and also installed Neo4j.
But i fail already at point 2 (installing smdc command): i get the following output in python:
Python 3.9.1 (tags/v3.9.1:1e5d33e, Dec 7 2020, 17:08:21) [MSC v.1927 64 bit (AMD64)] on win32
Type “help”, “copyright”, “credits” or “license” for more information.
Second issue arised:
after installing, i used: smdc --input “folder with notes”
i got the following error:
import yaml
ModuleNotFoundError: No module named ‘yaml’
Do i need to install another package first?
EDIT: solved it… for anyone running into the same issues: i needed to install some packages first. For me it was : "pip install pyyaml AND pip install tqdm
Finished the installation, created the out.cypher file (its populated with all entrys from my zettelkasten) - after i called apoc.cypher.runFile it finishes very fast and no nodes are created. In Bloom i therefor cant see anything.
What might be missing? The out.cypher file is in the import folder (and its not empty)
Ahh… I hoped to automatically do this, but looks like that failed. I fixed it now, I think. Glad you figured it out!
Hmm, what did it say at the bottom of the ‘card’ of the result? Where it says “Started streaming 256 records after 2 ms and completed after 4992 ms.”? It could be there is some particularity in your data I haven’t accounted for.
Also, I noticed Neo4j Bloom is sometimes not displaying some data that is in the dataset. To ensure there really isn’t anything, run MATCH (n) RETURN count(n) in the browser.
Anyways, I’ve been thinking about how to make this easier to use. Luckily, it’s possible to upload data to neo4j directly from Python! So I’ll do this for the next version.
Then I’ll look into making a very simple Obsidian plugin that automates calling the command.
Looks like this might happen because the code wasn’t reading/writing in utf-8 and you used special characters. Can you do pip install --upgrade semantic-markdown-converter and try again?
Version 0.2.0 is now out! Install with pip install --upgrade semantic-markdown-converter.
This version makes it easier to get your data into neo4j. Now all you have to do is start your database and run smdc --input "folder with notes" --password "neo4j database password".
Version 0.3.0 is now out! Again, upgrade with pip install --upgrade semantic-markdown-converter
This version automatically streams all updates in your Obsidian vault to Neo4j, meaning you only have to turn it on once and have all changes automatically reflected in Neo4j.
I also fixed some missing data issues.
@Emile Thank you for offer to support other syntax, here is my use case, feel free to improve the syntax if needed. I tried to come up with natural, flexible enough to describe any bill of material which will for example allow to transitively/recursively sum up quantities of materials needed for given catering plan.
Markdown nested list, similar to Yaml but using structured text in place of leaf string as a way to add properties in “natural language way” and include wiki or markdown links.
# food 1
some
- irrelevant text
- contains:
- 1 kg of [[food 2]]
- [[food 3]]
- approximately 3 pieces of [[food 4]]
- 1 piece of [[food 5]] # optionally 2 pieces
- previously also:
- 1 piece of [[food 6]]
- another irrelevant
- text
list of relations starts by non-indented line in form - <linktype>:
indented list item expected to be in form - text <amount> <unit> <preposition> <[[linktosubject|text]]> # another text which might contain links
treat filename of the file as a “subject” of relations
ignore list items that do not contain link. (maybe treat dead links with missing target file as valid.)
ignore comment after "# " till end of line (requiring comment separator means that this can be extension of your original proposed syntax with more links (objects) on one line separated by comma, when colon after link type is optional or signifies initiation of hyphenated multi-line list. )
ignore optional prepositions before link, e.g. " of "
ignore link text after pipe
for start, ignore text before the decimal number or link
store decimal number in property “quantity” of the edge/link/relation
store string in property “unit” of the edge/link/relation
allow specification of equivalent units like piece, pieces, ks (although this could be treated by user later in graph database, but for real time interaction between markdown and graph, treating this automatically like aliases would be nice.)
similarly aliases for link-types. contains, obsahuje Could be specified as equivalent.
aliases would allow to adjust to any language.
Czech version:
# potravina 1
some
irrelevant text
- obsahuje:
- 1 kg [[potravina 2|potraviny 2]]
- [[potravina 3]]
- asi 2 ks [[potravina 4]]
- 1 ks [[potravina 5]] # mohou být i 2 kusy.
- dříve také:
- 1 ks [[potravina 6]]
Hi, that certainly looks like a useful thing to have. Adding properties in a ‘natural language’ way would be very useful, but it sounds hard to interpret. In your example, in particular, how would the interpreter know how to process it as - text <amount> <unit> <preposition> <[[linktosubject|text]]> # another text which might contain links?
Aspen offers a nice syntax to maybe allow defining such constructs. And your example reminds me a bit of Semantic Authoring Markup: https://mbakeranalecta.github.io/sam/quickstart.html Although this also seems a bit hard to interpret correctly
I will try to describe how I would approach it with my limited skills. (For example I am using AutoHotkey in Obsidian-edit-mode to open markdown-style-link which surrounds or precedes caret (cursor). When link target does not exist, then It gets created and prefilled with header based on info from the parsed link.)
Assume I have relevant indented lines available and processing them one by one, My approach in following:
Have dictionary of prepositions to ignore {“of”, …}.
Have dictionary of (measurement) units and it’s aliases {kg: kg, piece: piece, pieces: piece, ks: piece}.
L := current line to process
L := L without part starting by "# " or “//”
While there is link in L:
{
Find first link in the line and store it as object of relation (you have this already implemented likely)
B := part of L before link
A := [] # empty array
Parse part before found link by space character into array A of “word” strings
If last word from A matches item from dictionary of prepositions, pop it out from array A.
If last word starts with digits followed by letters, then split it into two ( “99units” → “99”, “units” ).
Now If last word matches item from dictionary of units (with aliases), add corresponding unit to property of relation and pop it out from array A.
If last word from A is number, then add it to property “quentity” of the relation
If relation does not have defined quantity, then set quantity = 1
// ignore rest of array A
L := part of L after the link // this allows to process list separated by commas