Hello everybody !
Using Obsidian for some time now, I now want to try more sophisticated tricks. In this case, it is work related and has to do with business and enterprise architecture. So I’ll have to explain a bit.
1. Data structure
I have basically put the HERM model (Higher Education Reference Model) in Obsidian. It is a tree structure, with 4 different levels. The two first are basically only containers with no interesting properties. The third has more properties, but I won’t deal with them for now. So I just focus on the fourth level items.
| 1st level | 2nd level | 3rd level | 4th level |
|---|---|---|---|
| Recherche | |||
| Réaliser | |||
| BC074 Mise en œuvre de la recherche | |||
| BC075 Création de recherche | |||
| BC077 Gestion des données de la recherche | |||
| BC097 Gestion des infrastructures de recherche | |||
| BC236 Gestion des ressources de la recherche | |||
| BC093 Gestion de la recherche | |||
| BC069 Gestion des programmes de recherche | |||
| BC073 Gestion de la recherche de fonds |
Each one of these items, extracted from the HERM, are in the form of a Note within a folder with the same name (because I use the Folder Notes component). And it is made solely for better reading purposes. Each one of the Note reflecting an item has also a property with its level.
Now, a fourth level item would look like this :
BC202 Alignement, planification et organisation (note name)
---
TypeObjetHERM: Capacité métier
NiveauObjetHERM: 4
ResponsableMétierCapacitéMétier:
- "[[TINTIN]]"
CapacitéEnUsage: true
CapacitéCritique: false
ServicesApplicatifsLiés:
tags:
- HERM
---
What I plan people in my organization to do would be to rate the business capabilities, on 4 different dimensions (organization, processes, solutions, global), with a grade scale from 1 to 4 (integer only).
But, you can have multiple evaluations for the same item, but with different roles (Direction or Responsable), on different dates. The purpose is to have a permanent evaluation on our business capabilities to drive our strategy, or at least, to help us targeting the weakest spots in this map, to target coontinuous improvement.
The proper process for one business capability evaluation would be :
- In parallel : notations from the Head of our school, and the one person in charge of the capability
- Discussion to reduce the gap in knowledge and appreciation of all 4 dimensions on this capability
- Negotiation to provide a final evaluation
- Some time later, rinse and repeat with the same steps
To stick with that philosophy, I therefore built another structure of Notes to handle the evaluation. Another Folders/Notes structure, with one folder containing this time multiple evaluations, and the evaluation Notes contained being like this :
BC202 - AKS - 20241201 (note name)
---
Évaluateur: "[[René DESCARTES]]"
DateÉvaluation: 2024-12-01
TypeÉvaluation: Direction
CapacitéÉvaluée: "[[BC202 Alignement, planification et organisation]]"
NoteOrga: 2
NoteProcessus: 3
NoteSolutions: 1
NoteGlobale: 2
tags:
- évaluation
---
Obvisously, I have all grades (the NoteSomethings), a date, a type (Direction, Responsable or Finale), and a person related to the evaluation (in case of Direction or Responsable, not Finale). And a tag to help gathering info later on. The obvious thing is that I link the evaluation to the Note of the evaluated Business Capacity (CapacitéÉvaluée).
In this case, I could have also these notes in other folders :
---
Évaluateur: "[[Jean-Jacques ROUSSEAU]]"
DateÉvaluation: 2024-12-05
TypeÉvaluation: Accountable
CapacitéÉvaluée: "[[BC202 Alignement, planification et organisation]]"
NoteOrga: 3
NoteProcessus: 4
NoteSolutions: 2
NoteGlobale: 3
tags:
- évaluation
---
AND
---
Évaluateur:
DateÉvaluation: 2024-12-31
TypeÉvaluation: Finale
CapacitéÉvaluée: "[[BC202 Alignement, planification et organisation]]"
NoteOrga: 3
NoteProcessus: 3
NoteSolutions: 2
NoteGlobale: 2
tags:
- évaluation
---
2. What I could achieve
With this data structure and my personal knowledge of using Dataview in Obsidian, I could build at least a summary of all evaluations for one Business Capability inside the Note of itself. Like this :
dataview
TABLE NoteOrga, NoteProcessus, NoteSolutions, NoteGlobale, Évaluateur, DateÉvaluation, TypeÉvaluation
FROM "Évaluations"
WHERE contains(file.outlinks, this.file.link)
SORT DateÉvaluation ASC
This helps already to compare evaluations between multiple shareholders, and also to have perspective over time on how the capability is evolving.
Side note : all evaluations are in the folder structure starting with a root folder name “Évaluations”, but I could also use the #évaluation instead
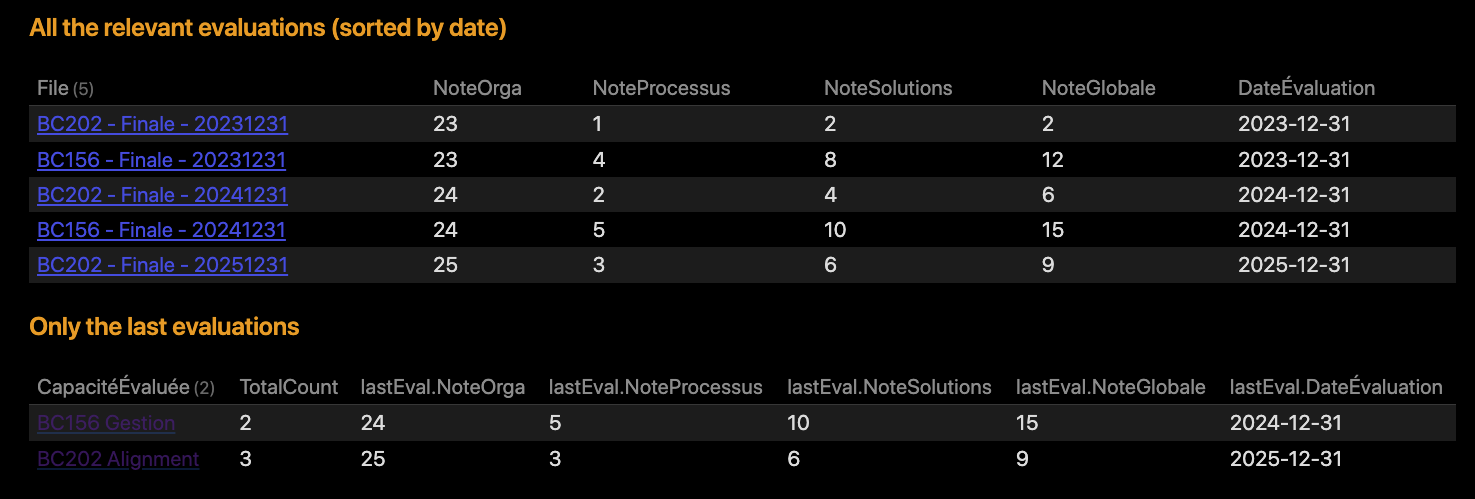
3. What I would like to achieve
Given the data structure described above, what I miss now is the possibility to have in just one place a super table listing all my Business Capacities (only on the 4th level) with their latest finale grades.
The final result would look like somthing like :
| file.name | NoteOrga | NoteProcessus | NoteSolutions | NoteGlobale | DateÉvaluation |
|---|---|---|---|---|---|
| BC202 Alignement, planification et organisation | 3 | 3 | 2 | 2 | décembre 31, 2024 |
| BC203 Construction, acquisition et implémentation | 3 | 3 | 3 | 3 | décembre 31, 2024 |
| BC204 Livraison, service et support | 1 | 1 | 1 | 1 | décembre 31, 2024 |
| BC205 Suivi évaluation et contrôle | 2 | 3 | 3 | 3 | décembre 31, 2024 |
| BC205 Suivi évaluation et contrôle | 2 | 3 | 3 | 3 | décembre 31, 2024 |
With my dummy data sets, for now, with just one final evaluation, I could gather only this type and it will work. But when I will have multiple final evaluations over the same items, I quite don’t know how to create the proper dataview.
The case of an item not being evaluated (with a Finale evaluation type) would raise occasionally as well.
I used to be a developper, like a thousand years ago, so I feel stupid on these. I have tried to dig into similar issues, and I have the feeling that I probably would have to use the FLATTEN and GROUP BY arguments in the query, but honestly, I do not understand well these concepts.
Examples of threads I tried and failed to understand :
https://forum.obsidian.md/t/dataview-query-using-where-and-flatten/54303
https://forum.obsidian.md/t/dataview-join-tables-and-limit-output-of-ungenerated-notes/50049
https://forum.obsidian.md/t/left-join-right-join-inner-join/53940
So if anyone (maybe holroy ? as he seems to be the most active and proficient on these) could have a look on this and help me with the proper code, it would be great ! And if there is enough explanation to make me more autonomous, it will be even better ![]()
Thanks !