Changes to the test vault
First of all, I did a few changes to the test vault:
- Added some links here and there to
[[Erklärung]] so I could trigger a backlink not starting with @
- Changed
Abrams2020 to Tabrams2020, so that I could get an uncreated link between Unruh and Suner
- Added a few more links to
@Unruh2020
- Moved all the citekey files into a folder
Reading Notes
With my script, using the backlinkCount sorting, I got the following output:
And now for the actual script, followed by some explanations. Sorry for the lengthy post, which is why I opted to collapse the various parts, so that one could focus on one of the parts. I would also strongly suggest copying the script to another window, so that one could read the script in parallell to reading the explanation.
The pseudo code of the script
The script is separated into different parts:
- A regex used to pull the citekey
- Two compare functions,
backlinkCount() and citekey()
- Your original queries, stored into
unreadStuff and uncreatedStuff
- A loop to build the
joinedArray
- Sorting the
joinedArray, either based upon backlinkCount (or citekey)
- Display of the final table
The gist of this script is to gather the data through the two queries, join the results into one larger table, sort that table, and present it. The compare functions are placed at front, due to common practice in programming.
The full script
```dataviewjs
const citekeyRegex = /^(?:.*\/)?([^\/]+)(?:\.md)?/
// Reverse compared backlink count
// ... and if equal, resort to citekey
function backlinkCount(a, b) {
console.log(`pre: ${a[2]} vs ${b[2]}`)
const aCount = a[2]
const bCount = b[2]
if (aCount == bCount) {
return citekey(a, b)
} else {
return (aCount < bCount ? 1 : -1)
}
}
// Compare citekeys
function citekey(a, b) {
console.log(`pre: ${a[0].path} vs ${b[0].path}`)
const aName = a[0].path.match(citekeyRegex)[1]
const bName = b[0].path.match(citekeyRegex)[1]
console.log(`post: ${aName} vs ${bName}`)
return aName < bName ? -1 : 1
}
const unreadStuff = await dv.tryQuery(`
TABLE
title AS Title,
length(file.inlinks) AS Backlinks
FROM "Reading Notes" and #unread
SORT length(file.inlinks) DESC
WHERE length(file.inlinks) >= 2
`)
const uncreatedStuff = await dv.tryQuery(`
TABLE without id
out AS "Uncreated files",
length(rows) AS Backlinks
FLATTEN file.outlinks AS out
WHERE !(out.file)
AND !contains(meta(out).path, "/")
AND startswith(meta(out).path, "@")
GROUP by out
SORT length(rows) DESC
WHERE length(rows) >=2
`)
//console.log(unreadStuff)
//console.log(uncreatedStuff)
let joinedArray = unreadStuff.values
for (let uncreated of uncreatedStuff.values) {
joinedArray.push([uncreated[0], "-", uncreated[1]])
}
console.log("\n\n\n\nNew run")
// joinedArray = joinedArray.sort(citekey)
joinedArray = joinedArray.sort(backlinkCount)
// console.log(joinedArray)
dv.table(["Citekey", "Title", "Backlinks"], joinedArray)
```
The queries
The queries are pretty much as they were, with the exception that I added another AND clause to the uncreated one, to single out those starting with @. That is the AND startswith(out.path, "@") line.
I’m using dv.tryQuery() which will trigger an error if something bad happens. One could also use dv.query(), but then one would need to handle the result a little different.
The joined array
When building the joined array, we’re not really interested in all the other stuff returned by the query, so we start it off with the values from the query with the most columns, aka the unreadStuff with its three columns.
We then loop through the values of the uncreatedStuff, and push each and every item into the joinedArray. Since we need it to be three columns, we add a fake column in the middle, and this can contain whatever text you want. I opted for nothing, but you can change the text to your liking.
This resulted in the following line:
joinedArray.push( [uncreated[0], "", uncreated[1]] )
Sorting the joined array
Sorting arrays in javascript is a little convoluted, but the gist is that you provide a compare function, which gets the two elements to compare. If the first is smaller than the other, you return -1. If they are equal, you return 0, and if the first is larger than the other, you return 1.
The javascript library then compares all the element two by two, and returns a sorted array.
I was not sure how you would like it sorted, so I provided two alternatives. One a pure alphabetic sort based upon the citekey(), and one with primary sort on the number of backlinks, and if that is equal than a secondary sort on the citekey.
The compare functions
When doing citekey() sort, you need to get the actual citekey, which depends on the regex explained below. But to get the starting point you need to get the actual path of the link, aka the a[0].path.
To discover this, I first did multiple console.log(a), which provide output like the following image:
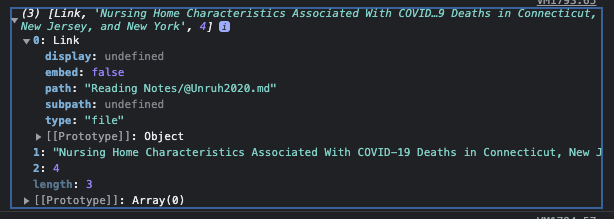
This is from the console in the Developers Tool pane. And one can see that the 0: element is the actual link, and it has a property path, which holds the full folder and filename including the citekey we’re looking for. Translated into pure javascript, that meant a[0].path.
Which I then pulled the citekey from, using the citekeyRegex. Now the result from the a[0].path.match(citekeyRegex] is another array, where the first element is the entire matched string, but we were only concerned with the captured group, so I put a [0] at the end of it all.
The regex to pull the citekey
I’m a little short on time, so I’m going to do a rather simple explanation of the regex, /^(?:.*\/)?([^\/]+)(?:\.md)?/:
-
^(?:.*\/)? – Start with an non-capturing, optional group, (?: ... )?, which gobbles up everything, .*, up to and including a literal forward slash, \/
-
([^\/]+) - Capture the group, ( ... ), of characters not being forward slash,[^\/] , and get at least one of these, +
-
(?:\.md)? – End with a non-capturing, optional group, (?: ... )? of the literal text, .md
In the case of actual links, the first and last group triggers, and gets discarded. In both cases, the middle group catches the actual citekey.
Regarding the other compare function, backlinkCount, I also viewed the image above, and saw that the count was in the last column, aka 2:, so I pulled out the two counts, and compared them. If they were equal, I returned the comparison of the citekey, and if unequal, returned them reversed, so that the larger backlink count comes to the top signifying it’s more vital read. (Not sure if this is correct, but that was my thought)
Some final thoughts
- The script as it is includes some
console.log() statements. These can be commented out by adding // in front of them. Some are already commented out, but if you want to really understand the script you can remove the comment, and watch the output
- I’ve not done a whole lot to the queries, so it’s possible they can still be optimised further
- I’ve not done a whole lot of error checking, so it’s possible this might break if either of the queries are empty, or similar
- A final debug tip, which I used to get started was to add
meta(out) to either table query, so that I could see the full data set available in the table. This was later removed, but it was very useful in the start
Hope this is somewhat what you wanted, and that it has enough explanations that you can utilise it and/or modify it to suit your needs.
