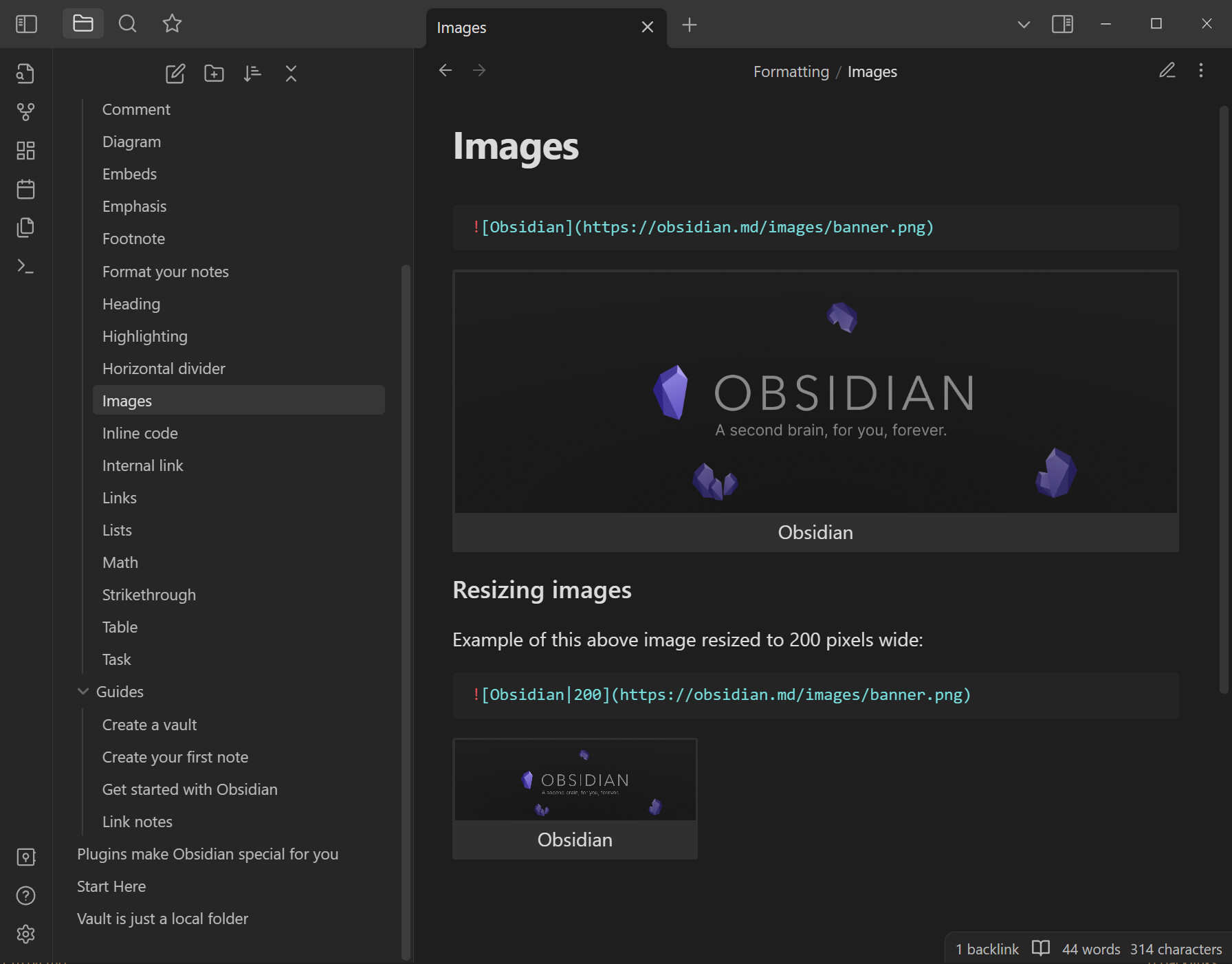
Create a .css file with the following code (I use Textedit for mac, don’t leave the .txt extension)
Put it in the snippet folder : your vault/.vault/snippet
Open the .vault folder using CMD OPT . command.
Notice that I added text-align: center; to center the caption because I use another snippet to center my image. If you don’t want to center your image, juste erase this part of the code (for reading mode and source view).
Don’t forget to activate this new snippet in the obsidian setting
Normal text
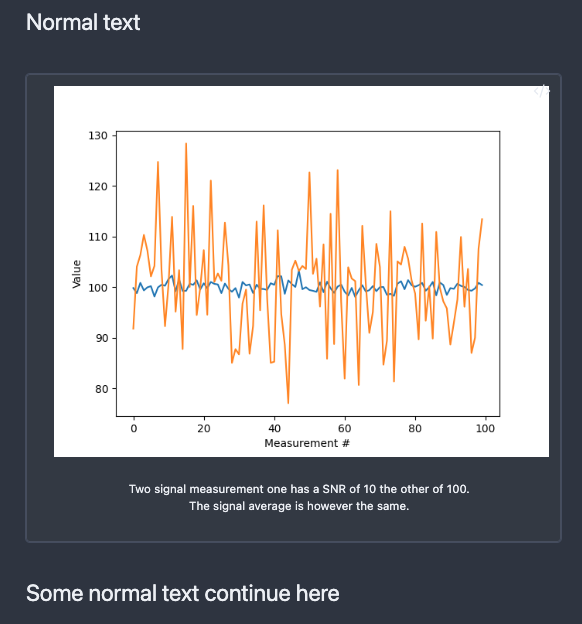
> [!figure] ![[two_noises.png]]
> Two signal measurement one has a SNR of 10 the other of 100. The signal average is however the same.
Some normal text continue here
Markdown already has a place for the image description (spec here):

or
![[path/to/image.jpg|Image description]]
This is where the text is taken from in the captions plugin(s) above.
Relying on Obsidian-style callouts is quite far from any sort of standard Markdown. It might be supported on another Markdown renderer, but it probably won’t be.
Using the in-spec Image Description has a higher likelihood of being supported on another platform into the future, and even without that, it is easier for other software to parse and renders perfectly into HTML.
edit: I’ll add that there’s nothing wrong with doing it the callout way - it’s just food for thought as you consider the longevity of your vault, and the cross-compatibility of it on other platforms if Obsidian is no longer around.
Of course . This was just an additional solution on the topics.
This solution is pretty suitable for long descriptions which can include bold text LaTeX , cross references etc …
Works well within Obsidian and any Markdown render with Obsidian callout flavour .
In fact the information is still there for Markdown render that does not handle callouts (like pandoc) . Only a weird [!figure] is added somewhere, but figure and caption are there.
I have another example use-case to add. I’m trying to make a local vault in the src directory of GitHub - cp-algorithms/cp-algorithms: Algorithm and data structure articles for https://cp-algorithms.com (based on http://e-maxx.ru) so that I can use Smart Connections for studying. Some of the articles are written with a ton of admonitions, and I’d really like to have a robust captioning feature so that admonitions are also manageable. I’m already cleaning up the files to replace the indented admonition syntax (!!! example "Example") with Obsidian’s amazing admonition syntax; it would be helpful if I had less Obsidian Markdown converting to do.
Screenshot (I tried inside the figure caption and the next line down, but I don’t like how either look):
> [!example] Nose stretching algorithm
>
> Each time you add $\vec r_{k-1}$ to the vector $\vec p$, the value of $\vec p \times \vec r$ is increased by $\vec r_{k-1} \times \vec r$.
>
> Thus, $a_k=\lfloor s_k \rfloor$ is the maximum integer number of $\vec r_{k-1}$ vectors that can be added to $\vec r_{k-2}$ without changing the sign of the cross product with $\vec r$.
>
> In other words, $a_k$ is the maximum integer number of times you can add $\vec r_{k-1}$ to $\vec r_{k-2}$ without crossing the line defined by $\vec r$:
>
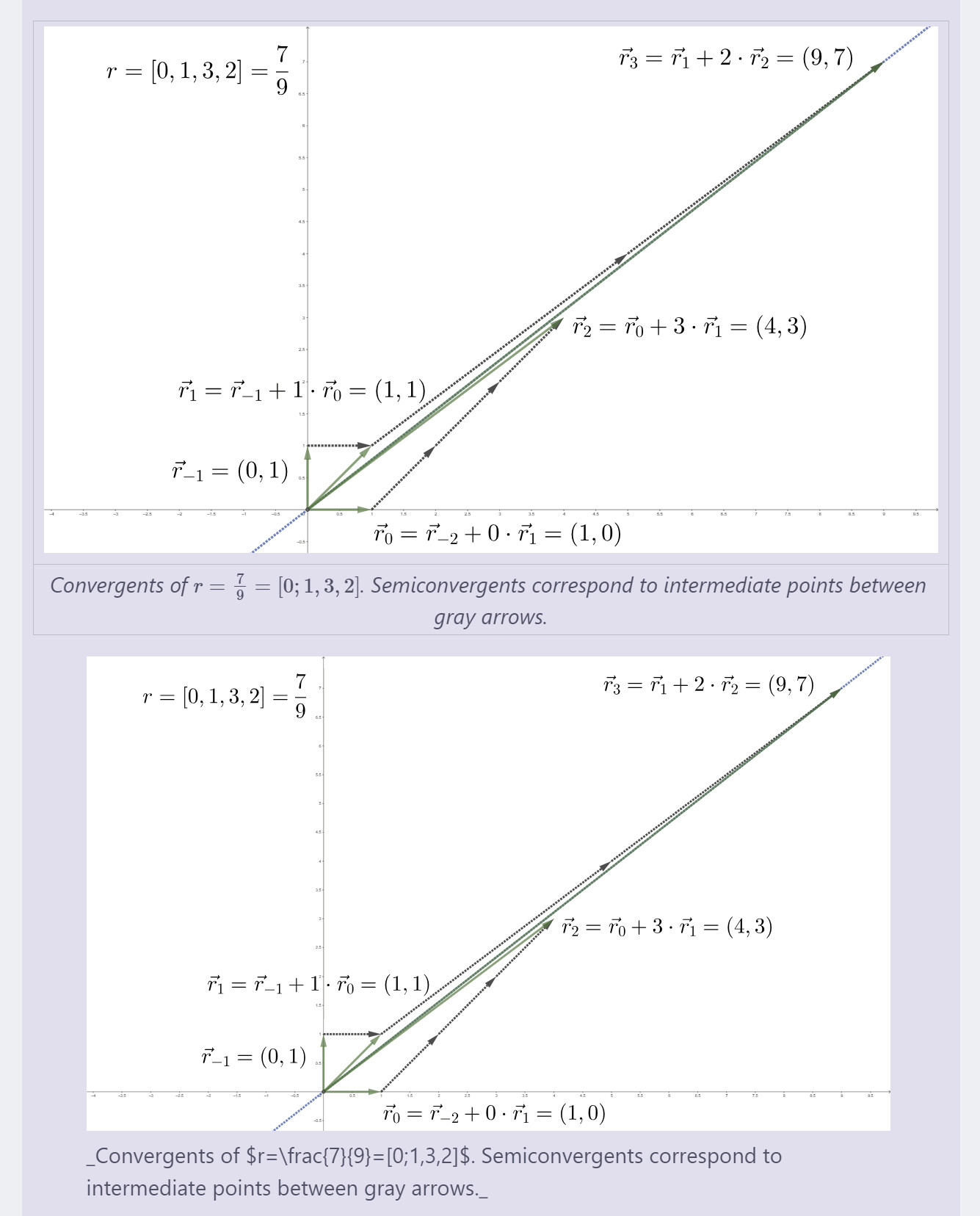
> <figure><img src="https://upload.wikimedia.org/wikipedia/commons/9/92/Continued_convergents_geometry.svg" width="600px"/><figcaption>_Convergents of $r=\frac{7}{9}=[0;1,3,2]$. Semiconvergents correspond to intermediate points between gray arrows._</figcaption></figure>
>
> _Convergents of $r=\frac{7}{9}=[0;1,3,2]$. Semiconvergents correspond to intermediate points between gray arrows._
>
> On the picture above, $\vec r_2 = (4;3)$ is obtained by repeatedly adding $\vec r_1 = (1;1)$ to $\vec r_0 = (1;0)$.
>
> When it is not possible to further add $\vec r_1$ to $\vec r_0$ without crossing the $y=rx$ line, we go to the other side and repeatedly add $\vec r_2$ to $\vec r_1$ to obtain $\vec r_3 = (9;7)$.
This is my favorite solution so far because I’m trying to use Obsidian to view someone else’s Markdown. The table format is the most reliable way for me to use a script to clean-up process.
Using callouts for captions works well for me. Thanks for your excellent idea!
Here’s my current CSS snippet for figure callouts. It has three variants: [!figure] is the default for figures that span the whole column width. [!figure-left] and [!figure-right] are floating images.