Topic: The file.lists by example (PART I/2)
- The file.lists by example - Chapter 3: using DQL to gather list items or task items under the specific heading (and filter by a field) (and sum up a field) (and display each DVIF)
Summary
- How to gather list items or task items under the specific heading? (
DQL90,DVJS90) - How to gather list items or task items under the specific heading
- Each of the following DQLs requires a specific note.
- How to filter by a field? (
DQL10,DQL20,DQL30) - How to sum up a field? (
DQL63,DQL65) - How to display each DVIF in items as a table
- case_FLST_HLSS :
DQL10 - case_FLST_HLSSS :
DQL20 - case_FLST_HLDSS :
DQL30 - case_FLST_HLDDD :
DQL61,DQL63,DQL65
- case_FLST_HLSS :
Q1: How to gather list items or task items under the specific heading and display each DVIF in items as a table?
Answers: DQL10, DQL20, or DQL30
Q2: How to gather root list items or root task items under the specific heading?
Answers: DQL61, DQL63, or DQL65
Q3: How to distinguish list items from task items from the file.lists data?
Answers
- How to distinguish list items from task items from the file.lists data?
- a list item: !L.task
- a task item: L.task
- a root list item: !L.parent AND !L.task
- a root task item: !L.parent AND L.task
- L : each element of file.lists of each page
- No one can distinguish a list item from a task item from the value of L.text where L is an element of file.lists .
Structures:
Summary
Q1: How to use the file.lists data to design a Markdown file as a table in the database, where each record consists of multiple columns?
Summary_Q1
A1_11:
Another Example: A1_11
- There are at least four methods to do that by using the file.lists data.
| Code Name | Data type | Cases | Headings(list items) | Headings(task items) | Remark |
|---|---|---|---|---|---|
| DQL10 | file.lists | case_FLST_HLSS | milestones | main tasks | |
| DQL20 | file.lists | case_FLST_HLSSS | some events | some tasks | |
| DQL30 | file.lists | case_FLST_HLDSS | other events | other tasks | |
| DQL61 | file.lists | case_FLST_HLDDD | what happened today | what happened today | |
| DQL63 | file.lists | case_FLST_HLDDD | what happened today | what happened today | |
| DQL65 | file.lists | case_FLST_HLDDD | what happened today | what happened today |
Test
Summary
- dataview: v0.5.41
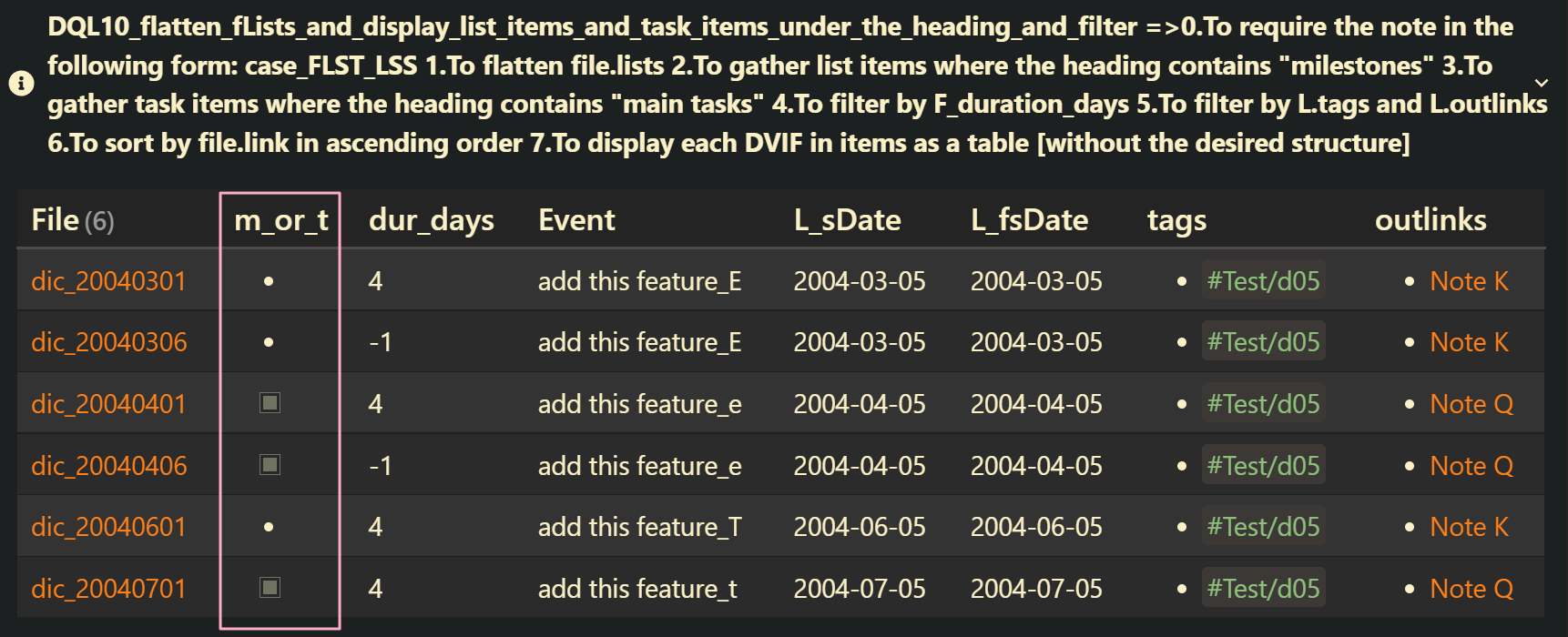
DQL10_flatten_fLists_and_display_list_items_and_task_items_under_the_heading_and_filter: case_FLST_HLSS
Summary
Main DQL
| Code Name | Data type | Group By | Purposes | Remark |
|---|---|---|---|---|
| DQL10_flatten_fLists _and_display_list_items _and_task_items _under_the_heading _and_filter |
file.lists | yes | 0.To require the note in the following form: case_FLST_HLSS 1.To flatten file.lists 2.To gather list items where the heading contains “milestones” 3.To gather task items where the heading contains “main tasks” 4.To filter by F_duration_days 5.To filter by L.tags and L.outlinks 6.To sort by file.link in ascending order 7.To display each DVIF in items as a table [without the desired structure] |
Note: Require the files with the case_FLST_HLSS structure |
Notes
Require the files with the case_FLST_HLSS structure
case_FLST_HLSS: use file.lists where L.text contains one field separator like " "
FLST: Use file.lists
H: a header
L : an element of file.lists
S: field separators
- filename :
dic_20040301contains the heading “milestones”
```md
---
Date: 2004-03-01
---
#Project/P03
Areas:: #research
#### input
##### milestones
- 2004-03-01 add this feature_A #Test/d01 [[Note J]] , [[Note K]]
- 2004-03-02 add this feature_B #Test/d02 [[Note J]]
- 2004-03-03 add this feature_C [[Note K]]
- 2004-03-04 add this feature_D #Test/d04
- 2004-03-05 add this feature_E #Test/d05 [[Note K]]
- 2004-03-06 add this feature_F #Test/d06
- 2004-73-07 add this feature_G #Test/d07
- 2004-03-08 add this feature_H [[Note J]] , [[Note K]]
- 2004-03-09 add this feature_I
- 2004-03-10 add this feature_J
- It is finished!
```
- filename :
dic_20040401contains the heading “main tasks”
```md
---
Date: 2004-04-01
---
#Project/P04
Areas:: #mocap
## input
### main tasks
- [ ] 2004-04-01 add this feature_a #Test/d01 [[Note P]] , [[Note Q]]
- [ ] 2004-04-02 add this feature_b #Test/d02 [[Note P]]
- [ ] 2004-04-03 add this feature_c [[Note Q]]
- [ ] 2004-04-04 add this feature_d #Test/d04
- [x] 2004-04-05 add this feature_e #Test/d05 [[Note Q]]
- [ ] 2004-04-06 add this feature_f #Test/d06
- [ ] 2004-74-07 add this feature_g #Test/d07
- [ ] 2004-04-08 add this feature_h [[Note P]] , [[Note Q]]
- [ ] 2004-04-09 add this feature_i
- [ ] 2004-04-10 add this feature_j
- [ ] It is finished!
```
Code DQL10_flatten_fLists_and_display_list_items_and_task_items_under_the_heading_and_filter: case_FLST_HLSS
Summary_code
title: DQL10_flatten_fLists_and_display_list_items_and_task_items_under_the_heading_and_filter =>0.Require the files with the `case_FLST_HLSS` structure
collapse: close
icon:
color:
```dataview
TABLE WITHOUT ID
file.link AS "File",
choice(L.task, "- [" + L.status + "] " + "", "- " + "") AS "m_or_t",
F_duration_days AS "dur_days",
F_text_without_outlinks AS "Event",
F_sDate_of_L AS "L_sDate",
F_fsDate_of_L AS "L_fsDate",
L.tags AS "tags",
L.outlinks AS "outlinks"
FROM "100_Project/02_dataview/Q92_FileLists/Q92_test_data" AND #Project
FLATTEN file.lists AS L
FLATTEN meta(L.header).subpath AS F_subpath
FLATTEN meta(L.header).type AS F_type
WHERE (contains(F_subpath, "milestones") AND F_type = "header")
OR (contains(F_subpath, "main tasks") AND F_type = "header")
WHERE regexmatch("^\d{4}-\d{2}-\d{2}\s+", L.text)
FLATTEN split(L.text, " ")[0] AS F_sDate_of_L
FLATTEN regexreplace(L.text, "^\d{4}-\d{2}-\d{2} ", "") AS F_text_without_date
FLATTEN regexreplace(F_text_without_date, "\s+#.+$", "") AS F_text_without_tags
FLATTEN regexreplace(F_text_without_tags, "(\s+\[\[.+\]\].*$)", "") AS F_text_without_outlinks
WHERE F_sDate_of_L != null
WHERE date(F_sDate_of_L) != null
FLATTEN date(F_sDate_of_L) AS F_dtDate_of_L
FLATTEN dateformat(F_dtDate_of_L, "yyyy-MM-dd") AS F_fsDate_of_L
FLATTEN Date AS YAML_Date
FLATTEN dur(F_dtDate_of_L - YAML_Date).days AS F_duration_days
WHERE F_duration_days != 0
WHERE (contains(L.tags, "#Test/d05") AND contains(L.outlinks, [[Note K]]))
OR (contains(L.tags, "#Test/d05") AND contains(L.outlinks, [[Note Q]]))
SORT file.link ASC
```
Screenshots(DQL10)
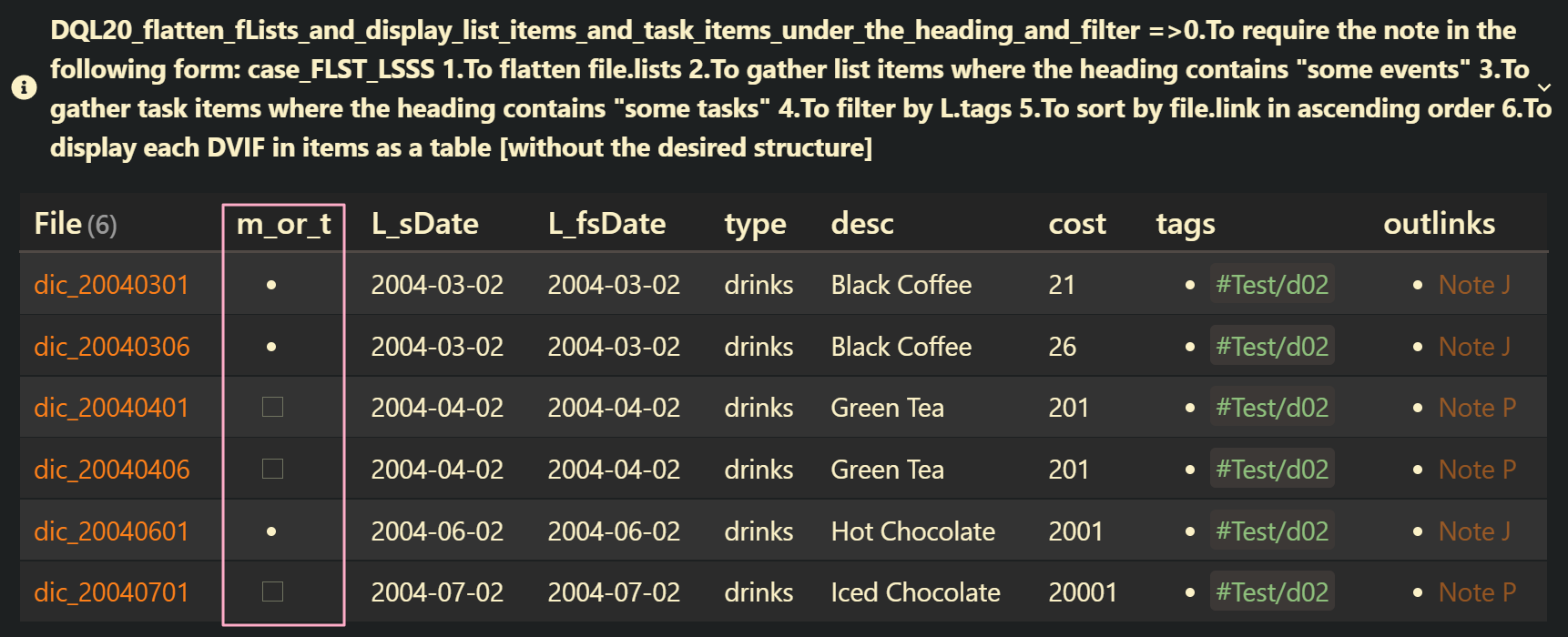
DQL20_flatten_fLists_and_display_list_items_and_task_items_under_the_heading_and_filter: case_FLST_HLSSS
Summary
Main DQL
| Code Name | Data type | Group By | Purposes | Remark |
|---|---|---|---|---|
| DQL20_flatten_fLists _and_display_list_items _and_task_items _under_the_heading _and_filter |
file.lists | yes | 0.To require the note in the following form: case_FLST_HLSSS 1.To flatten file.lists 2.To gather list items where the heading contains “some events” 3.To gather task items where the heading contains “some tasks” 4.To filter by L.tags 5.To sort by file.link in ascending order 6.To display each DVIF in items as a table [without the desired structure] |
Note: Require the files with the case_FLST_HLSSS structure |
Notes
Require the files with the case_FLST_HLSSS structure
case_FLST_HLSSS: use file.lists where L.text contains at least one field separator like “|”
FLST: Use file.lists
H: a header
L : an element of file.lists
S: field separators
- filename :
dic_20040301contains the heading “some events”
```md
---
Date: 2004-03-01
---
#Project/P03
Areas:: #research
#### input
##### some events
- 2004-03-01 | drinks | Black Coffee | 11 | #Test/d01 [[Note J]] , [[Note K]]
- 2004-03-02 | drinks | Black Coffee | 21 | #Test/d02 [[Note J]]
- 2004-03-03 | drinks | Black Coffee | 31 | [[Note K]]
- 2004-03-04 | drinks | Black Coffee | 41 | #Test/d04
- 2004-03-05 | drinks | Black Coffee | 51 | #Test/d05 [[Note K]]
- 2004-03-06 | drinks | Black Coffee | 61 | #Test/d06
- 2004-73-07 | drinks | Black Coffee | 71 | #Test/d07
- 2004-03-08 | drinks | Black Coffee | 81 | [[Note J]] , [[Note K]]
- 2004-03-09 | drinks | Black Coffee | 91
- 2004-03-10 | drinks | Black Coffee
- It is finished!
```
- filename :
dic_20040401contains the heading “some tasks”
```md
---
Date: 2004-04-01
---
#Project/P04
Areas:: #mocap
## input
### some tasks
- [ ] 2004-04-01 | drinks | Green Tea | 101 | #Test/d01 [[Note P]] , [[Note Q]]
- [ ] 2004-04-02 | drinks | Green Tea | 201 | #Test/d02 [[Note P]]
- [ ] 2004-04-03 | drinks | Green Tea | 301 | [[Note Q]]
- [ ] 2004-04-04 | drinks | Green Tea | 401 | #Test/d04
- [x] 2004-04-05 | drinks | Green Tea | 501 | #Test/d05 [[Note Q]]
- [ ] 2004-04-06 | drinks | Green Tea | 601 | #Test/d06
- [ ] 2004-74-07 | drinks | Green Tea | 701 | #Test/d07
- [ ] 2004-04-08 | drinks | Green Tea | 801 | [[Note P]] , [[Note Q]]
- [ ] 2004-04-09 | drinks | Green Tea | 901
- [ ] 2004-04-10 | drinks | Green Tea
- [ ] It is finished!
```
Code DQL20_flatten_fLists_and_display_list_items_and_task_items_under_the_heading_and_filter: case_FLST_HLSSS
Summary_code
title: DQL20_flatten_fLists_and_display_list_items_and_task_items_under_the_heading_and_filter =>0.Require the files with the `case_FLST_HLSSS` structure
collapse: close
icon:
color:
```dataview
TABLE WITHOUT ID
file.link AS "File",
choice(L.task, "- [" + L.status + "] " + "", "- " + "") AS "m_or_t",
F_sDate_of_L AS "L_sDate",
F_fsDate_of_L AS "L_fsDate",
F_type AS "type",
F_desc AS "desc",
F_cost AS "cost",
L.tags AS "tags",
L.outlinks AS "outlinks"
FROM "100_Project/02_dataview/Q92_FileLists/Q92_test_data" AND #Project
FLATTEN file.lists AS L
FLATTEN meta(L.header).subpath AS F_subpath
FLATTEN meta(L.header).type AS F_type
WHERE contains(F_subpath, "some events") AND F_type = "header"
OR (contains(F_subpath, "some tasks") AND F_type = "header")
WHERE regexmatch("^\d{4}-\d{2}-\d{2}\s+", L.text)
FLATTEN split(L.text, "\s+\|\s+")[0] AS F_sDate_of_L
FLATTEN split(L.text, "\s+\|\s+")[1] AS F_type
FLATTEN split(L.text, "\s+\|\s+")[2] AS F_desc
FLATTEN split(L.text, "\s+\|\s+")[3] AS F_cost
WHERE F_sDate_of_L != null
WHERE date(F_sDate_of_L) != null
FLATTEN date(F_sDate_of_L) AS F_dtDate_of_L
FLATTEN dateformat(F_dtDate_of_L, "yyyy-MM-dd") AS F_fsDate_of_L
WHERE contains(L.tags, "#Test/d02")
SORT file.link ASC
```
Screenshots(DQL20)
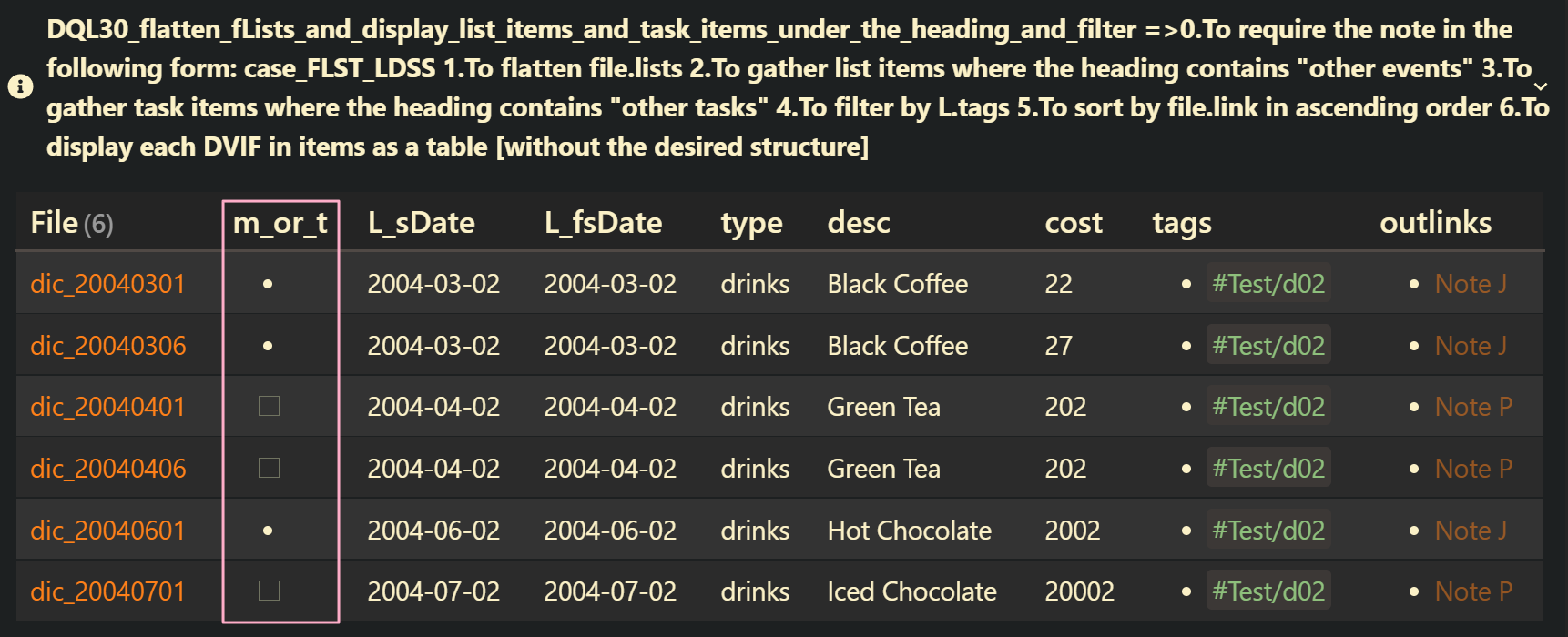
DQL30_flatten_fLists_and_display_list_items_and_task_items_under_the_heading_and_filter: case_FLST_HLDSS
Summary
Main DQL
| Code Name | Data type | Group By | Purposes | Remark |
|---|---|---|---|---|
| DQL30_flatten_fLists _and_display_list_items _and_task_items _under_the_heading _and_filter |
file.lists | yes | 0.To require the note in the following form: case_FLST_HLDSS 1.To flatten file.lists 2.To gather list items where the heading contains “other events” 3.To gather task items where the heading contains “other tasks” 4.To filter by L.tags 5.To sort by file.link in ascending order 6.To display each DVIF in items as a table [without the desired structure] |
Note: Require the files with the case_FLST_HLDSS structure |
Notes
Require the files with the case_FLST_HLDSS structure
case_FLST_HLDSS: use file.lists where L.text consists of one DVIF and field separators
FLST: Use file.lists
H: a header
L : an element of file.lists
D: DVIF
S: field separators
- filename :
dic_20040301contains the heading “other events”
```md
---
Date: 2004-03-01
---
#Project/P03
Areas:: #research
#### input
##### other events
- info:: 2004-03-01 | drinks | Black Coffee | 12 | #Test/d01 [[Note J]] , [[Note K]]
- info:: 2004-03-02 | drinks | Black Coffee | 22 | #Test/d02 [[Note J]]
- info:: 2004-03-03 | drinks | Black Coffee | 32 | [[Note K]]
- info:: 2004-03-04 | drinks | Black Coffee | 42 | #Test/d04
- info:: 2004-03-05 | drinks | Black Coffee | 52 | #Test/d05 [[Note K]]
- info:: 2004-03-06 | drinks | Black Coffee | 62 | #Test/d06
- info:: 2004-73-07 | drinks | Black Coffee | 72 | #Test/d07
- info:: 2004-03-08 | drinks | Black Coffee | 82 | [[Note J]] , [[Note K]]
- info:: 2004-03-09 | drinks | Black Coffee | 92
- info:: 2004-03-10 | drinks | Black Coffee
- It is finished!
```
- filename :
dic_20040401contains the heading “other tasks”
```md
---
Date: 2004-04-01
---
#Project/P04
Areas:: #mocap
## input
### other tasks
- [ ] (info:: 2004-04-01 | drinks | Green Tea | 102) #Test/d01 [[Note P]] , [[Note Q]]
- [ ] (info:: 2004-04-02 | drinks | Green Tea | 202) #Test/d02 [[Note P]]
- [ ] (info:: 2004-04-03 | drinks | Green Tea | 302) [[Note Q]]
- [ ] (info:: 2004-04-04 | drinks | Green Tea | 402) #Test/d04
- [x] (info:: 2004-04-05 | drinks | Green Tea | 502) #Test/d05 [[Note Q]]
- [ ] (info:: 2004-04-06 | drinks | Green Tea | 602) #Test/d06
- [ ] (info:: 2004-74-07 | drinks | Green Tea | 702) #Test/d07
- [ ] (info:: 2004-04-08 | drinks | Green Tea | 802) [[Note P]] , [[Note Q]]
- [ ] (info:: 2004-04-09 | drinks | Green Tea | 902)
- [ ] (info:: 2004-04-10 | drinks | Green Tea)
- [ ] It is finished!
```
Code DQL30_flatten_fLists_and_display_list_items_and_task_items_under_the_heading_and_filter: case_FLST_HLDSS
Summary_code
title: DQL30_flatten_fLists_and_display_list_items_and_task_items_under_the_heading_and_filter =>0.Require the files with the `case_FLST_HLDSS` structure
collapse: close
icon:
color:
```dataview
TABLE WITHOUT ID
file.link AS "File",
choice(L.task, "- [" + L.status + "] " + "", "- " + "") AS "m_or_t",
F_sDate_of_L AS "L_sDate",
F_fsDate_of_L AS "L_fsDate",
F_type AS "type",
F_desc AS "desc",
F_cost AS "cost",
L.tags AS "tags",
L.outlinks AS "outlinks"
FROM "100_Project/02_dataview/Q92_FileLists/Q92_test_data" AND #Project
FLATTEN file.lists AS L
FLATTEN meta(L.header).subpath AS F_subpath
FLATTEN meta(L.header).type AS F_type
WHERE contains(F_subpath, "other events") AND F_type = "header"
OR (contains(F_subpath, "other tasks") AND F_type = "header")
WHERE L.info != null
FLATTEN split(L.info, "\s+\|\s+")[0] AS F_sDate_of_L
FLATTEN split(L.info, "\s+\|\s+")[1] AS F_type
FLATTEN split(L.info, "\s+\|\s+")[2] AS F_desc
FLATTEN split(L.info, "\s+\|\s+")[3] AS F_cost
WHERE F_sDate_of_L != null
WHERE date(F_sDate_of_L) != null
FLATTEN date(F_sDate_of_L) AS F_dtDate_of_L
FLATTEN dateformat(F_dtDate_of_L, "yyyy-MM-dd") AS F_fsDate_of_L
WHERE contains(L.tags, "#Test/d02")
SORT file.link ASC
```
Screenshots(DQL30)
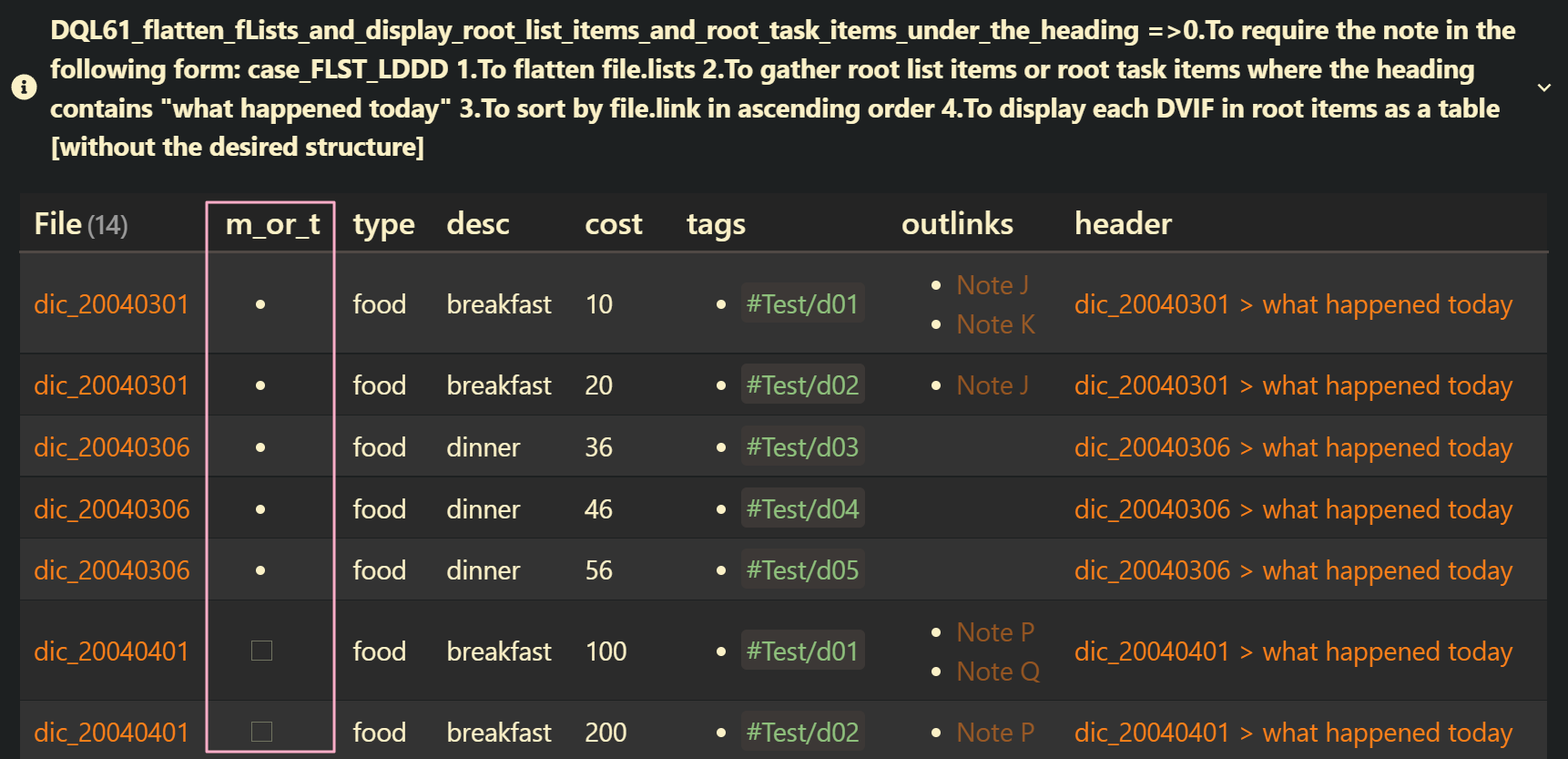
DQL61_flatten_fLists_and_display_root_list_items_and_root_task_items_under_the_heading: case_FLST_HLDDD
Summary
Main DQL
| Code Name | Data type | Group By | Purposes | Remark |
|---|---|---|---|---|
| DQL61_flatten_fLists _and_display _root_list_items _and_root_task_items _under_the_heading |
file.lists | yes | 0.To require the note in the following form: case_FLST_HLDDD 1.To flatten file.lists 2.To gather root list items or root task items where the heading contains “what happened today” 3.To sort by file.link in ascending order 4.To display each DVIF in root items as a table [without the desired structure] |
Note: Require the files with the case_FLST_HLDDD structure |
Notes
Require the files with the case_FLST_HLDDD structure
case_FLST_HLDDD: use file.lists where L.text consists of more than one DVIF
FLST: Use file.lists
H: a header
L : an element of file.lists
D: DVIF
- filename :
dic_20040301contains the heading “what happened today”
```md
---
Date: 2004-03-01
---
#Project/P03
Areas:: #research
#### input
##### what happened today?
- [type:: "food"] [desc:: "breakfast"] [cost:: 10] #Test/d01 [[Note J]] , [[Note K]]
- [type:: "food"] [desc:: "breakfast"] [cost:: 20] #Test/d02 [[Note J]]
##### Each DVIF is aligned to the left
- [type:: "food"]
[desc:: "breakfast"]
[cost:: 10]
#Test/d01 [[Note J]] , [[Note K]]
- [type:: "food"]
[desc:: "breakfast"]
[cost:: 20]
#Test/d02 [[Note J]]
```
- filename :
dic_20040401contains the heading “what happened today”
```md
---
Date: 2004-04-01
---
#Project/P04
Areas:: #mocap
## input
### what happened today?
- [ ] [type:: "food"] [desc:: "breakfast"] [cost:: 100] #Test/d01 [[Note P]] , [[Note Q]]
- [ ] [type:: "food"] [desc:: "breakfast"] [cost:: 200] #Test/d02 [[Note P]]
### Each DVIF is aligned to the left
- [ ] [type:: "food"]
(desc:: "breakfast")
%%(cost:: 100)%%
#Test/d01 [[Note P]] , [[Note Q]]
- [ ] [type:: "food"]
(desc:: "breakfast")
%%(cost:: 200)%%
#Test/d02 [[Note P]]
```
Code DQL61_flatten_fLists_and_display_root_list_items_and_root_task_items_under_the_heading: case_FLST_HLDDD
Summary_code
title: DQL61_flatten_fLists_and_display_root_list_items_and_root_task_items_under_the_heading =>0.Require the files with the `case_FLST_HLDDD` structure
collapse: close
icon:
color:
```dataview
TABLE WITHOUT ID
file.link AS "File",
choice(L.task, "- [" + L.status + "] " + "", "- " + "") AS "m_or_t",
L.type AS "type",
L.desc AS "desc",
L.cost AS "cost",
L.tags AS "tags",
L.outlinks AS "outlinks",
L.header AS "header"
FROM "100_Project/02_dataview/Q92_FileLists/Q92_test_data" AND #Project
FLATTEN file.lists AS L
FLATTEN meta(L.header).subpath AS F_subpath
FLATTEN meta(L.header).type AS F_type
WHERE !L.parent
WHERE contains(F_subpath, "what happened today") AND F_type = "header"
SORT file.link ASC
```
Screenshots(DQL61)
Part 1/2
Part 2/2
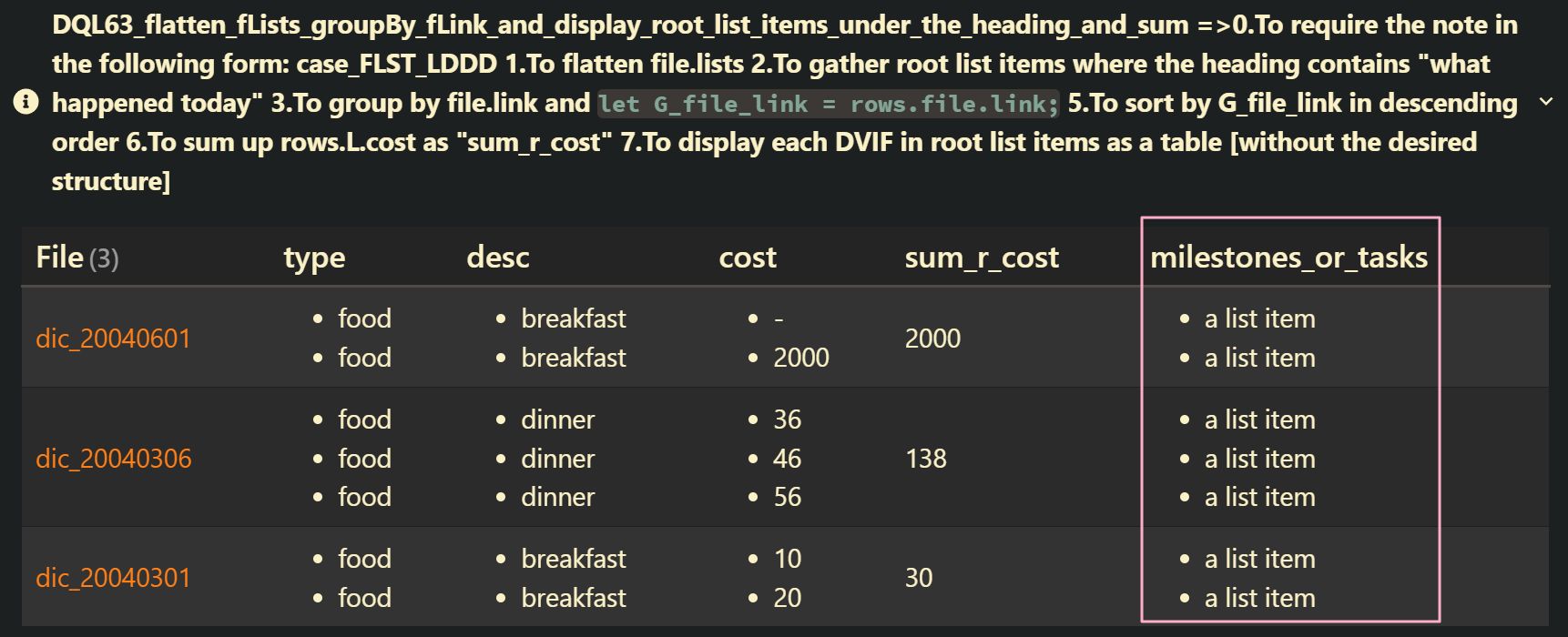
DQL63_flatten_fLists_groupBy_fLink_and_display_root_list_items_under_the_heading_and_sum: case_FLST_HLDDD
Summary
Main DQL
| Code Name | Data type | Group By | Purposes | Remark |
|---|---|---|---|---|
| DQL63_flatten_fLists _groupBy_fLink _and_display _root_list_items _under_the_heading _and_sum |
file.lists | yes | 0.To require the note in the following form: case_FLST_HLDDD 1.To flatten file.lists 2.To gather root list items where the heading contains “what happened today” 3.To group by file.link and let G_file_link = rows.file.link; 4.To sort by G_file_link in descending order 5.To sum up rows.L.cost as “sum_r_cost” 6.To display each DVIF in root list items as a table [without the desired structure] |
Note: Require the files with the case_FLST_HLDDD structure |
Code DQL63_flatten_fLists_groupBy_fLink_and_display_root_list_items_under_the_heading_and_sum: case_FLST_HLDDD
Summary_code
title: DQL63_flatten_fLists_groupBy_fLink_and_display_root_list_items_under_the_heading_and_sum =>0.Require the files with the `case_FLST_HLDDD` structure
collapse: close
icon:
color:
```dataview
TABLE WITHOUT ID
G_file_link AS "File",
rows.L.type AS "type",
rows.L.desc AS "desc",
rows.L.cost AS "cost",
sum(map(rows.L.cost, (e) => sum(default(e, 0)))) AS "sum_r_cost",
map(rows.L, (L) => choice(L.task, "- [" + L.status + "] ", "a list item")) AS "milestones_or_tasks"
FROM "100_Project/02_dataview/Q92_FileLists/Q92_test_data" AND #Project
FLATTEN file.lists AS L
FLATTEN meta(L.header).subpath AS F_subpath
FLATTEN meta(L.header).type AS F_type
WHERE !L.parent AND !L.task
WHERE contains(F_subpath, "what happened today") AND F_type = "header"
GROUP BY file.link AS G_file_link
SORT G_file_link DESC
```
Screenshots(DQL63)
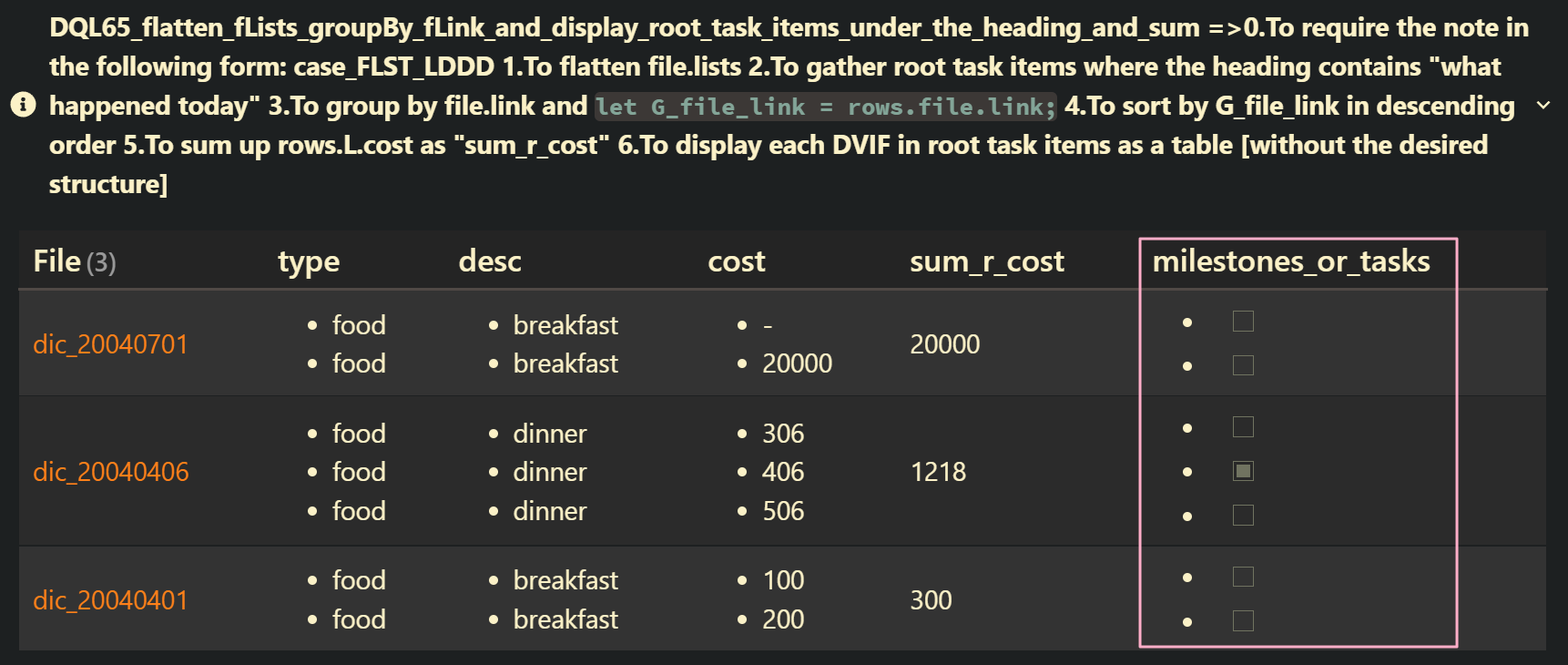
DQL65_flatten_fLists_groupBy_fLink_and_display_root_task_items_under_the_heading_and_sum: case_FLST_HLDDD
Summary
Main DQL
| Code Name | Data type | Group By | Purposes | Remark |
|---|---|---|---|---|
| DQL65_flatten_fLists _groupBy_fLink _and_display _root_task_items _under_the_heading _and_sum |
file.lists | yes | 0.To require the note in the following form: case_FLST_HLDDD 1.To flatten file.lists 2.To gather root task items where the heading contains “what happened today” 3.To group by file.link and let G_file_link = rows.file.link; 4.To sort by G_file_link in descending order 5.To sum up rows.L.cost as “sum_r_cost” 6.To display each DVIF in root task items as a table [without the desired structure] |
Note: Require the files with the case_FLST_HLDDD structure |
Code DQL65_flatten_fLists_groupBy_fLink_and_display_root_task_items_under_the_heading_and_sum: case_FLST_HLDDD
Summary_code
title: DQL65_flatten_fLists_groupBy_fLink_and_display_root_task_items_under_the_heading_and_sum =>0.Require the files with the `case_FLST_HLDDD` structure
collapse: close
icon:
color:
```dataview
TABLE WITHOUT ID
G_file_link AS "File",
rows.L.type AS "type",
rows.L.desc AS "desc",
rows.L.cost AS "cost",
sum(map(rows.L.cost, (e) => sum(default(e, 0)))) AS "sum_r_cost",
map(rows.L, (L) => choice(L.task, "- [" + L.status + "] ", "a list item")) AS "milestones_or_tasks"
FROM "100_Project/02_dataview/Q92_FileLists/Q92_test_data" AND #Project
FLATTEN file.lists AS L
FLATTEN meta(L.header).subpath AS F_subpath
FLATTEN meta(L.header).type AS F_type
WHERE !L.parent AND L.task
WHERE !rows.L.cost
WHERE contains(F_subpath, "what happened today") AND F_type = "header"
GROUP BY file.link AS G_file_link
SORT G_file_link DESC
```
Screenshots(DQL65)
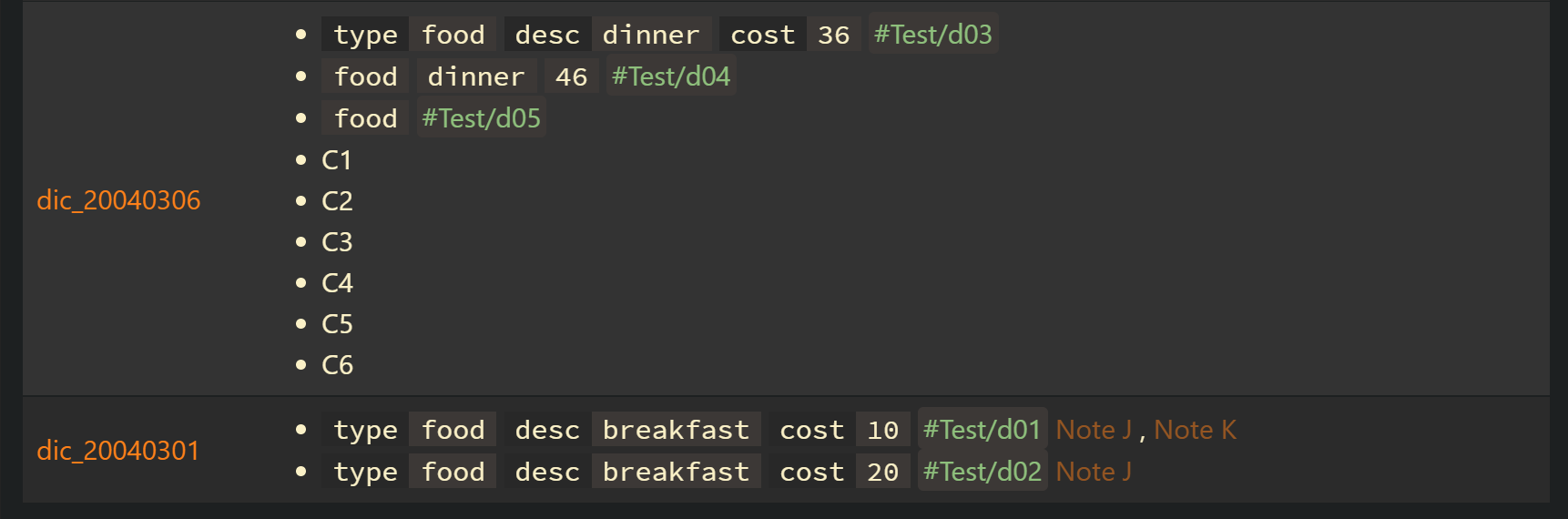
Exercises : DQL90_flatten_fLists_groupBy_fLink_and_display_list_items_and_task_items_under_the_heading
Summary
Main DQL
| Code Name | Data type | Group By | Purposes | Remark |
|---|---|---|---|---|
| DQL90_flatten_fLists _groupBy_fLink _and_display_list_items _and_task_items _under_the_heading |
file.lists | yes | 1.To flatten file.lists 2.To gather list items or task items where the heading contains “what happened today” 3.To group by file.link and let G_file_link = rows.file.link; 4.To sort by G_file_link in descending order 5.To display the result as a table [without the desired structure] |
1.The DQL90 is based on the DQL07 in the following topic. 1.1 Q93_Tasks: Solutions |
Notes
dictionary files
- filename :
dic_20040301contains the heading “what happened today”
```md
---
Date: 2004-03-01
---
#Project/P03
Areas:: #research
#### input
##### what happened today?
- [type:: "food"] [desc:: "breakfast"] [cost:: 10] #Test/d01 [[Note J]] , [[Note K]]
- [type:: "food"] [desc:: "breakfast"] [cost:: 20] #Test/d02 [[Note J]]
##### Each DVIF is aligned to the left
- [type:: "food"]
[desc:: "breakfast"]
[cost:: 10]
#Test/d01 [[Note J]] , [[Note K]]
- [type:: "food"]
[desc:: "breakfast"]
[cost:: 20]
#Test/d02 [[Note J]]
```
- filename :
dic_20040401contains the heading “what happened today”
```md
---
Date: 2004-04-01
---
#Project/P04
Areas:: #mocap
## input
### what happened today?
- [ ] [type:: "food"] [desc:: "breakfast"] [cost:: 100] #Test/d01 [[Note P]] , [[Note Q]]
- [ ] [type:: "food"] [desc:: "breakfast"] [cost:: 200] #Test/d02 [[Note P]]
### Each DVIF is aligned to the left
- [ ] [type:: "food"]
(desc:: "breakfast")
%%(cost:: 100)%%
#Test/d01 [[Note P]] , [[Note Q]]
- [ ] [type:: "food"]
(desc:: "breakfast")
%%(cost:: 200)%%
#Test/d02 [[Note P]]
```
Code DQL90_flatten_fLists_groupBy_fLink_and_display_list_items_and_task_items_under_the_heading
Summary_code
title: DQL90_flatten_fLists_groupBy_fLink_and_display_list_items_and_task_items_under_the_heading =>1.To flatten file.lists 2.To gather list items or task items where the heading contains "what happened today" 3.To group by file.link and `let G_file_link = rows.file.link;` 4.To sort by G_file_link in descending order 5.To display the result as a table [without the desired structure]
collapse: close
icon:
color:
```dataview
TABLE WITHOUT ID
G_file_link AS "File",
map(rows.L, (L) => choice(L.task, "- [" + L.status + "] " + L.text, L.text)) AS "milestones_or_tasks"
FROM "100_Project/02_dataview/Q92_FileLists/Q92_test_data" AND #Project
FLATTEN file.lists AS L
FLATTEN meta(L.header).subpath AS F_subpath
FLATTEN meta(L.header).type AS F_type
WHERE contains(F_subpath, "what happened today") AND F_type = "header"
GROUP BY file.link AS G_file_link
SORT G_file_link DESC
```
Screenshots(DQL90)
Part 1/3

Part 2/3

Part 3/3
Exercises : DVJS90_groupBy_fLink_flatten_fLists_and_taskList_under_the_heading
Summary
Main DVJS
| Code Name | Data type | Group By | Purposes | Remark |
|---|---|---|---|---|
| DVJS90 _groupBy_fLink _flatten_fLists _and_taskList _under_the_heading |
file.lists | yes groupIn:no |
1.To groupBy page.file.link as G1 (G1=group.rows) 2.To flatten page.file.lists 3.To gather a list item(or a task item) under the heading “what happened today” 4.To display the result by using the dv.taskList [with the desired structure] |
1.The DVJS90 is based on the DVJS01 in the following topic. 1.1 Q17_GroupIn: Solutions |
code DVJS90_groupBy_fLink_flatten_fLists_and_taskList_under_the_heading
Summary_code
title: DVJS90_groupBy_fLink_flatten_fLists_and_taskList_under_the_heading => 1.To groupBy page.file.link as G1 (G1=group.rows) 2.To flatten page.file.lists 3.To gather a list item(or a task item) under the heading "what happened today" 4.To display the result by using the dv.taskList [with the desired structure]
collapse: close
icon:
color:
```dataviewjs
// M11. define pages: gather all relevant pages
// #####################################################################
let pages = dv
.pages('"100_Project/02_dataview/Q92_FileLists/Q92_test_data" and #Project')
.where((page) => page.Areas);
// M21. define groups:
// To groupBy page.file.link AS G1 (G1=group.rows)
// #####################################################################
let groups = pages
.groupBy((page) => page.file.link)
.sort((group) => group.key, "desc");
// M31. output groups:
// #####################################################################
for (let group of groups) {
// M31.FR13 define a_filtered_lists:
// FLATTEN_CASE_10:To FLATTEN page.file.lists and gather them
// WHERE_CASE_11 :To gather a list item(or a task item)
// under the heading "what happened today"
// #####################################################################
let a_filtered_lists = group.rows
.flatMap((page) => page.file.lists)
.where(
(L) => dv.func.contains(L.header.subpath, "what happened today") &&
L.header.type === "header"
);
// M31.FR15 check a_filtered_lists.length :
// #####################################################################
if (a_filtered_lists.length === 0){
continue;
}
// M31.FR21 output page.file.link :
// #####################################################################
dv.header(3, group.key);
// M31.FR23 output a_filtered_lists.text: [with the desired structure]
// #####################################################################
dv.taskList(a_filtered_lists, false);
}
```
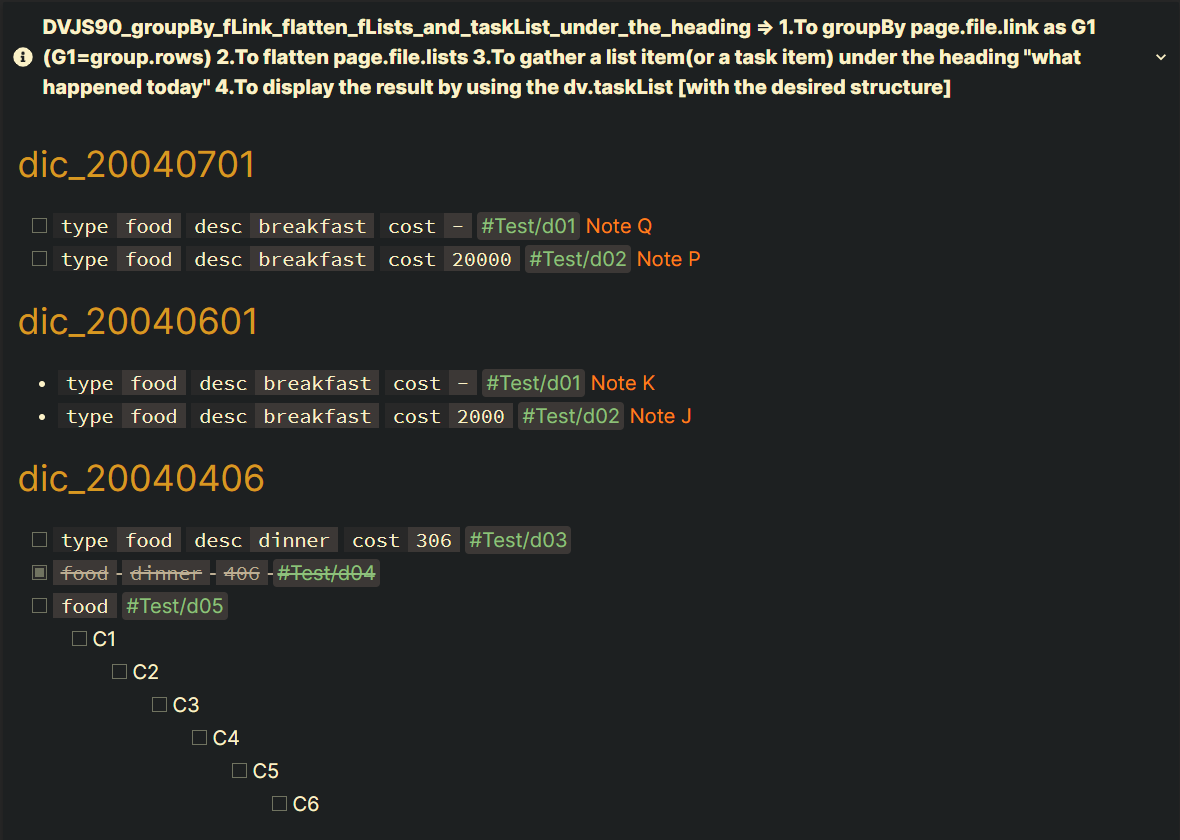
Screenshots(DVJS90):
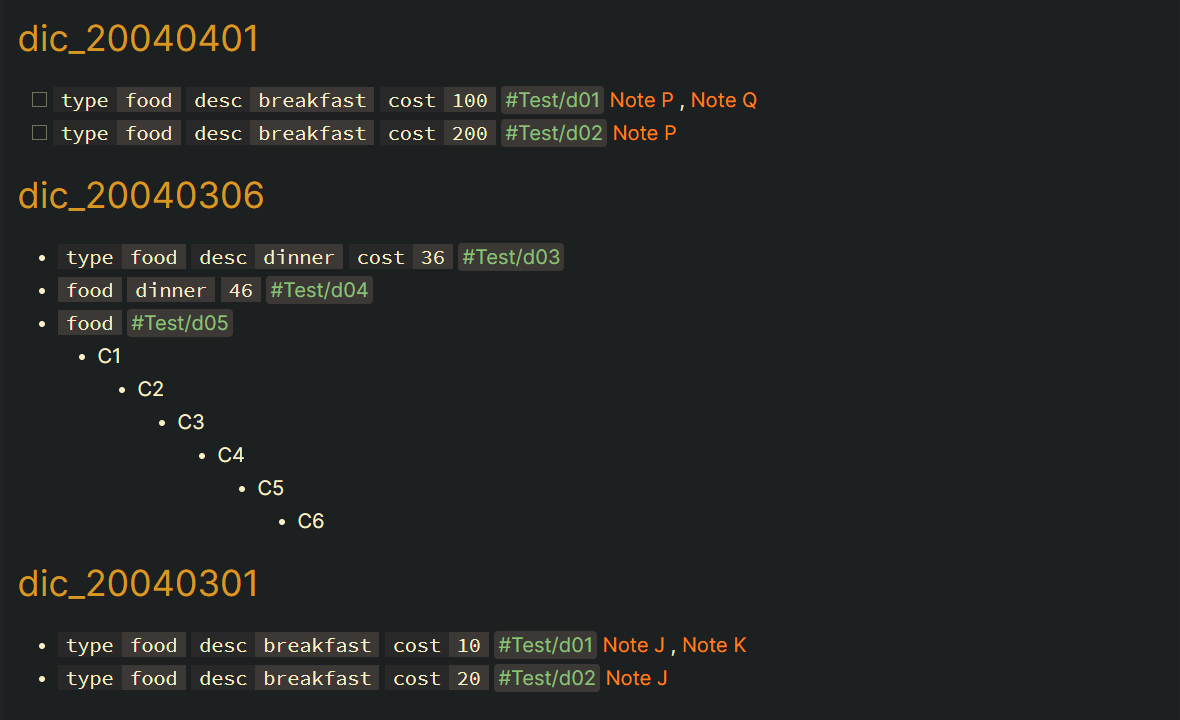
Part 1/2
Part 2/2
Reference
Summary
Q93_Tasks > DQL07
- Q93_Tasks: Solutions
Q17_GroupIn > DVJS01
- Q17_GroupIn: Solutions, Q17_DVJS10_Notes, Q17_DVJS20_Notes