Summarize transcripts with AI for free
I started with AI transcript summaries rather late (Feb 2025). I took some of the ideas from Obsidian’s Discord channel (Obsidian Web Clipper related spaces), others from Reddit.
I have experimented with 3 types of methods…
- Python scripts via Obsidian Interactivity plugin
- Obsidian Web Clipper’s Interpreter method
- Obsidian Copilot plugin
I have found various (minor to major) flaws using the first two methods, so I ended up with a fusion of the second and third method.
My chosen method
I am first outlining the problem points and how to tackle them, then I’ll show you what works for me.
- The write-up expects the reader to have a minimal knowledge of computer science so I try not to overexplain myself (how to install Obsidian, plugins, browser extensions, or how to call up Obsidian plugin commands from the Command Palette).
Are transcripts available or not?
Chances are you will find videos of interest that have no available transcripts. This can have various causes:
- Video was uploaded several years ago.
- Uploader didn’t add the transcript as a subtitle so the Transcript button could emerge at Description.
Solution
Download the video with the method outlined below and upload it to your YT account so the video will be automatically transcribed by Google/YouTube. (I don’t want to use AI models to do this as I don’t have a powerful enough PC to do it fast enough. I want to use freely available Google services and resources.)
Do we need Web Clipper and for what?
The Obsidian Web Clipper’s Interpreter functionality is nice but I’ve not seen a workflow that would suit my needs.
- First of all, I want the transcripts to be available based on the URL. I don’t want to open the Transcripts manually (if available at all).
- I want the timestamps to be clickable (or not have to do or explain mass replacements through a script to make them clickable).
- Edit: The 260625 post has a script now that can be used for multiple purposes.
- I also want visual feedback of where we are (some kind of progress feedback) from the conclusion of the summary export.
- I’ve seen cases where the Interpreter took 120-180s to create the summary, while in Copilot, this was much faster.
- I can also keep the original transcript, while in Interpreter there is no apparent way to do this(?).
Obsidian note creation with metadata and YT video widget
What we would (or now: must) still use the Web Clipper for is to create the note in the folder we want it, with metadata we set and a widget below the frontmatter.
And: to have the URL in a source property for creating clickable timestamps with the new script I mentioned.
- In any case, it’s not only useful now to have Web Clipper create the file but sometimes even a necessity.
Used tools
- Video DownloadHelper browser extension
- Obsidian Web Clipper browser extension
- Obsidian YTranscript plugin
- Obsidian Copilot plugin
Optional
- Obsidian Hover Editor plugin
- Obsidian Surfing plugin
- Obsidian CSS Editor plugin
Setup
(…and workflow – the setup steps are longer than what you need to do as your workflow)
1
We will use Google Gemini’s free Flash Thinking experimental models. No need to think OpenAI, Groq, Cerebras or other providers’ models here. If anyone wants to use local LLMs it’s up to them.
Type in Google search: google gemini free api key
Get a Gemini API key in Google AI Studio
Sign in to your Google account if not signed in.
At https://aistudio.google.com/app/apikey, Create API key. Copy it. Keep it safe.
Head over to Google AI Studio’s https://aistudio.google.com/app/prompts/new_chat page.
Over on the right, look up the model’s name: gemini-2.0-flash-thinking-exp-01-21
- An older
gemini-2.0-flash-thinking-exp-1219model is still valid and useable. - In the future, you’ll need to come back to this page to look for any possible newer models and update your model settings in Copilot.
2
In Obsidian Copilot plugin’s settings, add the key:
Basic → General → Set keys
Add your key in the Gemini bar and verify it.
Model → Add Custom Model
Add both models mentioned above.

Leave Base URL as it is, tick ‘Reasoning’, then Verify model and Add Model (provider is Gemini, which you need to set too).
Same for the 1219 model as well.
- Notice there is no hyphen in the 1219 model name, but there is one in the 01-21 one.
We add the older model in case the newer model is overworked by users worldwide and we are thwarted in our attempts to use the latest model. - By the way, a
gemini-2.0-flash-thinking-exp-latestnaming convention does not exist, but upon thinkinggemini-2.0-flash-thinking-explike so would be the latest model, so I guess we could take this on as a third (or even as a sole candidate) for the go-to model version. Then we wouldn’t need to go to Google to check time and again.
Add other settings:
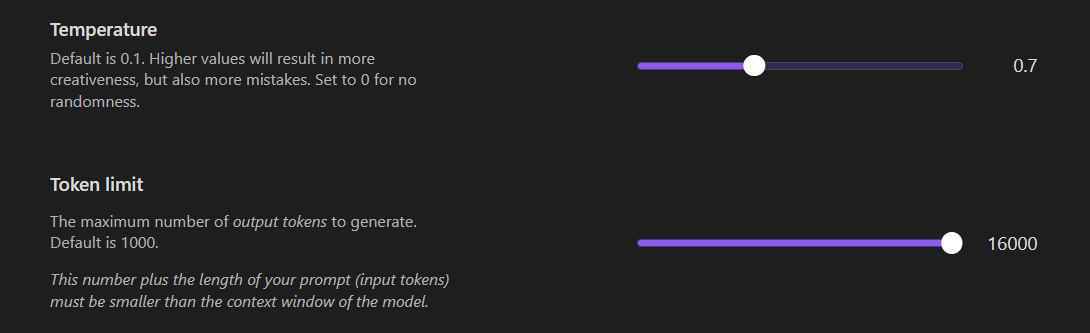
The 0.7 temperature setting may be too high (too creative) for some. In that case, try to explore summary outputs with 0.1 or maybe in between the two.
Because the models mentioned are able to output 64000 tokens and you cannot set any value higher than 16000, do the following:
Close Obsidian, head to the Copilot plugin’s settings in .obsidian\plugins\copilot in your Explorer/Finder and open data.json with a text editor.
Find "maxTokens": 16000, line and exchange the number with 64000.
Save the json file. You can open Obsidian again.
Go back to the settings of Copilot. Don’t touch the 64000 setting.
Add your own folders where you want to keep your custom prompts and where you want to save conversations:

Create an empty md file and add this content as your Copilot AI Summarizer prompt:
Summarize {activeNote} in Markdown format. If the transcript is in English or any language except German, summarize in German.
If it is in German, summarize in German. Fix obvious spelling errors automatically. Use appropriate H1 to H4 headers.
Insert callout boxes where relevant to expand context. Use the following types exactly as described (both type and content of box must be preceded with `> ` as you can see) and **always** keeping empty lines between these elements:
> [!check]
> For key insights or useful information.
> [!important]
> For critical points or must-remember details.
> [!fail]
> For warnings, dangers, or failures.
> [!note]
> For notable quotes or poetic/philosophical reflections.
> [!question]
> For thought-provoking or discussion-worthy questions.
> [!example]
> For extended exploration, implications, and creative ideas.
Distinguish **question** and **example** boxes: Question relates closely to the topic, while Example allows deeper, more philosophical or spiritual extensions.
### Formatting & Processing Rules:
- Ensure logical flow.
- Avoid redundant introductions and outros.
- Ignore irrelevant sections (disclaimers, social media plugs, intros/outros without subject relevance).
- Must preserve timestamps for reference.
- Ensure proper Markdown rendering: Every callout box **must** be separated from other content and other callouts by exactly ONE blank line, both before and after.
- Summary length should match content depth – expand when meaningful, condense when generic.
If the input transcript is missing definite articles or seemingly starts the sentences with lowercase characters, **fix it automatically.**
### FINAL SECTIONS:
At the end, create these structured bullet-point sections:
**IDEAS** - 1-10 distilled key insights.
**QUOTES** - 1-10 impactful direct quotes. Here, use double quotes, not backticks!
**TIPS** - 1-10 practical takeaways.
**REFERENCES** - List of relevant books, tools, projects, and inspirations.
### OUTPUT INSTRUCTIONS:
- Use only Markdown and consistently.
- Ensure proper sentence capitalization (uppercase letters **must** start a sentence!).
- Output only the requested sections - no additional notes or warnings.
- Maintain efficiency and consistency throughout. Use timestamps with exact clickable format as they appeared in the text so each notion has its easily clicked reference.
- Do NOT use escape characters before double quotes. In fact, when providing German summaries, use smart quotes.
The {activeNote} variable is used in the prompt, which means you need to have the note with the transcript added to it open.
I expect users to come from a bilingual background. I was using German as the other language. Find German in the md file and replace with your own language. If not needed, remove those references to another language.
3
Install the Obsidian Web Clipper extension in your browser(s).
- I use Firefox everywhere and sync my extensions, so I need to install extensions once and on a new install I get the extensions with data on sync. I expect it works the same way on Chrome and Edge.
Add this template by Importing it.
Import template → Paste content below:
{
"schemaVersion": "0.1.0",
"name": "YouTube Transcript Summarizer Metadata and Header Widget Creator",
"behavior": "create",
"noteContentFormat": "## AI Summary\n\nAuthor: {{author}}\n<iframe height=\"315\" class=\"w-full rounded-btn\" src=\"https://www.youtube-nocookie.com/embed/{{url|replace:\"/.*[?&]v=([a-zA-Z0-9_-]{11}).*|.*youtu\\.be\\/([a-zA-Z0-9_-]{11}).*|.*\\/embed\\/([a-zA-Z0-9_-]{11}).*|.*\\/v\\/([a-zA-Z0-9_-]{11}).*/\":\"$1$2$3$4\"}}?enablejsapi=1\" title=\"{{title|replace:\"/[\\\\/\\:*?\\\"<>\\|]/g\":\"-\"}}\" frameborder=\"0\" allow=\"clipboard-write; encrypted-media; picture-in-picture ;web-share\" allowfullscreen=\"\" id=\"widget2\"></iframe>\n\n",
"properties": [
{
"name": "title",
"value": "{{title|replace:\\\"/[\\\\/\\:*?\\\\\"<>\\|]/g\\\":\\\"-\\\"}}",
"type": "text"
},
{
"name": "source",
"value": "{{url|replace:\\\"/([?&]list=[^&]*)|([?&]index=[^&]*)|([?&]t=[^&]*)|([?&]start=[^&]*)|([?&]feature=[^&]*)|([?&]ab_channel=[^&]*)/g\\\":\\\"\\\"}}",
"type": "text"
},
{
"name": "description",
"value": "{{description}}",
"type": "text"
},
{
"name": "author",
"value": "{{author|split:\\\", \\\"|wikilink|join}}",
"type": "multitext"
},
{
"name": "tags",
"value": "webclip transcript-summary",
"type": "multitext"
},
{
"name": "published",
"value": "{{published}}",
"type": "date"
},
{
"name": "created",
"value": "{{date}}",
"type": "datetime"
}
],
"triggers": [],
"noteNameFormat": "{{title|replace:\"/[\\\\/\\:*?\\\"<>\\|]/g\":\"-\"}}",
"path": "Add your path here"
}
Once you imported it, rename the template if you want and of course, Add your path here will not be your path in your vault where you want your note saved, so edit it. You can edit the tags values to any values of your choice. If your created property is date created or anything else, you change that too.
- The sanitizer regex for 3 title replacements was updated on 24-02-2025 to include ‘g’ flags.
4
Pick the video you want and run the clipper with the above template.
You’ll have your note with the metadata and widget of the vid in your (last used) vault (which is the default setting in Web Clipper).
5
Go back to the video you wanted, copy the URL and try adding it to the YTranscript plugin. If it throws an error, the transcript is not (yet) available.
You’ll need to download the video and upload it to your account.
6
Download the vid with the DownloadHelper. If it’s a YT video, the extension asks you to install some helper app. Install it and in the settings add your own preferred download location.
If the video you are downloading is from YouTube, it’s okay to download the video at 360px, so the download and upload time will take less.
Upload the vid to your own YT account. Set the visibility to Unlisted. YT will still transcribe the video at this setting.
In a short while, the checks will have been done and the transcription added.
7
Try your own URL (the new YT URL) in YTranscript again.
If the transcription process have been done, you’ll have the timestamped lines appear in the sidebar. Below the Search bar, right click on the text → Copy all.
Paste the clipboard contents into the note we created with Web Clipper. You can close the YTranscript sidebar element. We don’t need it anymore.
8
Command Palette: Open Copilot Chat Window
On the bottom of the sidebar element, set the newly added model as the one we want to use:

In the panel where you’d add your input, press / to add your custom prompt you saved above:
Upon having the prompt added, you need to send it with Enter. Then in a short time, the summary is being streamed line by line into the sidebar element pane.
In the meantime, add two empty lines or a separator (---) below the transcript, which you can choose to keep or not (I keep it).
When the streaming has finished, at the bottom of the response, you can click Insert to note as cursor:

- The icons appear on hover only, so sometimes it is difficult to find them.
9
If all has been done well, you’ll have your note populated with the intended content.
Here we can make use of optional plugins, so when we hover over a timestamp, we can listen in on the topics.
We need to install and enable:
- Hover Editor
- Surfing
- CSS Editor
In order for what we want to work, the Page Preview core plugin needs to be enabled.
With the CSS Editor plugin, you’ll need to add the following CSS snippet:
.theme-light, .theme-dark {
–popover-width: 1432px;
–popover-height: 680px;
}
- The width value will need to be adjusted to the right edge of the left sidebar, if that’s what is needed.
- The height value seems to make no difference.
- A simple
.themeselector rule didn’t work, hence.theme-light, .theme-dark {is used in the first line.
When you create the Hover Popup Width.css file (or you can name this with any other name) with the plugin (you need to add the .css extension), the plugin automatically enables the snippet.
Tips
1
The steps above don’t need to be done in that order. Ideally, you need to explore what videos you are interested in first. You can use the YTranscript plugin to check whether the video has available transcript(s).
In case you need transcripts, download all videos and upload them to your YouTube to allow plenty of time for the transcribing jobs to be finished.
2
When juggling settings in Copilot, try adding credentials to or – if you have no credit cards or intention to use this – remove the default OpenAI provider as the plugin notices in the upper right-hand corner can be annoying after a while.
User feedback
Please provide feedback how you’d make the above work faster or more intuitively, especially with the Interpreter, for video summaries with clickable time stamps, videos over the length of 59:59 mins:secs, etc.
Notes
1
I dared to title this ‘Perfect Summaries’.
The model does a really good job cleaning up transcription problems.
For example, in my original text I had ‘albert cu and jean-paul sart’. The model in the summary rectified the names with ‘Albert Camus’ and ‘Jean-Paul Sartre’.
Out of 10 names it got 8-9 spelling right even when they were in my native language.
2
In the last few days I’ve seen problems with incomplete summaries. No errors but only a few lines were output for all 3 models mentioned above.
I went back to my Python script, which worked but as I said above, with that, the output is somehow never as good there as with Copilot.
3
Some widgets will come out black with the video being unavailable in your region. The videos may still play though and in thast case the playing of videos through the timestamps will still be possible.
4
I have fed it some topics to do with fringe science. It looks as if Copilot inherently deals with uncensoring output…
- The equivalent of…
{
"safetySettings": [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_NONE"
},
{
"category": "HARM_CATEGORY_UNSPECIFIED",
"threshold": "BLOCK_NONE"
}
]
}
…so the output is streamed without hindrance, but I have not tested the models with the most outrageous topics yet, of course.
I am mainly alluding to the fact Google censored me on occasions where I simply wanted to translate something and did not do it, but tried to boss over what I should know about things.
5
260625:
Updated post to draw attention to this script we can use.
There are other scripts as well to download (Python).

