Hello, I’m trying to automate tallying hours worked across project codes.
My Current Workflow
Currently everyday I open a daily note entitled by the days date and I organize my notes by work week folders. For example:
-
- Week of May 29th
- 2023-05-29
- 2023-05-30
- etc…
-
- Week of June 5th
- 2023-06-05
- 2023-06-06
- etc…
In each of my daily notes I have a list of items which outline what I did and the project code allocated to that task. I’ve added an embedded field for the purpose of tallying hours later. The value of the field corresponds to the amount of hours worked towards that project code.
For example here are example contents for a few files:
/22. Week of May 29th/2023-05-29:
- #projectcode1 Completed development task [projectcode1::3.5]
- Random notes I type related to this work activity. This can be ignored in my obsidian processing and is just for personal reference
- #projectcode2 Meeting regarding scope [projectcode2::1]
- More random notes taken during this meeting
- #projectcode1 Meeting regarding task 179 [projectcode1::0.5]
- #projectcode3 New Project meeting [projectcode3::1]
/22. Week of May 29th/2023-05-30:
- #projectcode1 Completed development task [projectcode1::3.5]
- Similarly I’ll have random notes nested under the top level list which can be ignored
- #projectcode3 Meeting regarding scope [projectcode2::1]
- #projectcode1 Meeting regarding task 179 [projectcode1::0.5]
- #projectcode4 New Project meeting [projectcode3::1]
What I’m trying to do
I’m trying to create a template file which I can copy into each work week directory which will parse all the files in the current folder (except this file) and produce aggregate information for me to type into my hour logging system.
Ultimately I’d like to be able to produce the following objectives, all can be separate dataview commands:
-
List all the unique project codes which have been written within the current week. For example if I were to insert this template document in the folder
/22. Week of May 29thit should generate the following list:- projectcode1
- projectcode2
- projectcode3
- projectcode4
-
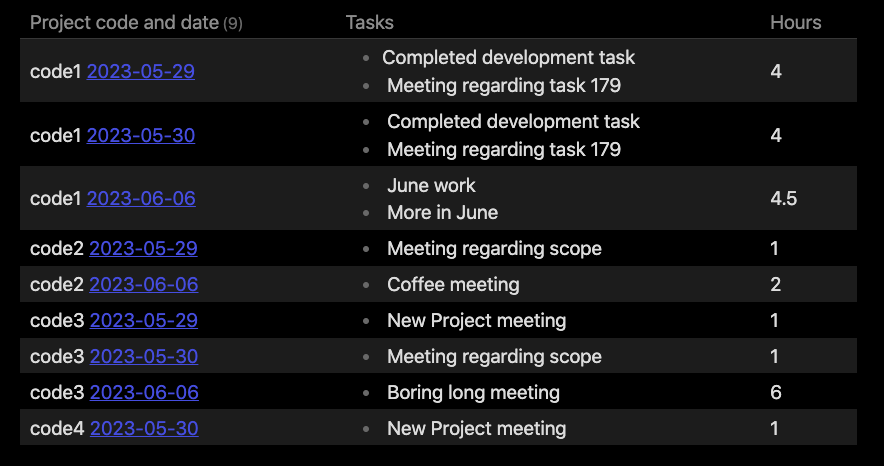
List all lines of text in all files in the current directory which contain the project code tag and embedded field and group the output by file name. The purpose of this is to list all high level task descriptions to write into an hour logging system. It should produce the following:
- 2023-05-29
- #projectcode1 Completed development task [projectcode1::3.5]
- #projectcode2 Meeting regarding scope [projectcode2::1]
- #projectcode1 Meeting regarding task 179 [projectcode1::0.5]
- #projectcode3 New Project meeting [projectcode3::1]
- 2023-05-30
- #projectcode1 Completed development task [projectcode1::3.5]
- #projectcode3 Meeting regarding scope [projectcode2::1]
- #projectcode1 Meeting regarding task 179 [projectcode1::0.5]
- #projectcode4 New Project meeting [projectcode3::1]
- 2023-05-29
-
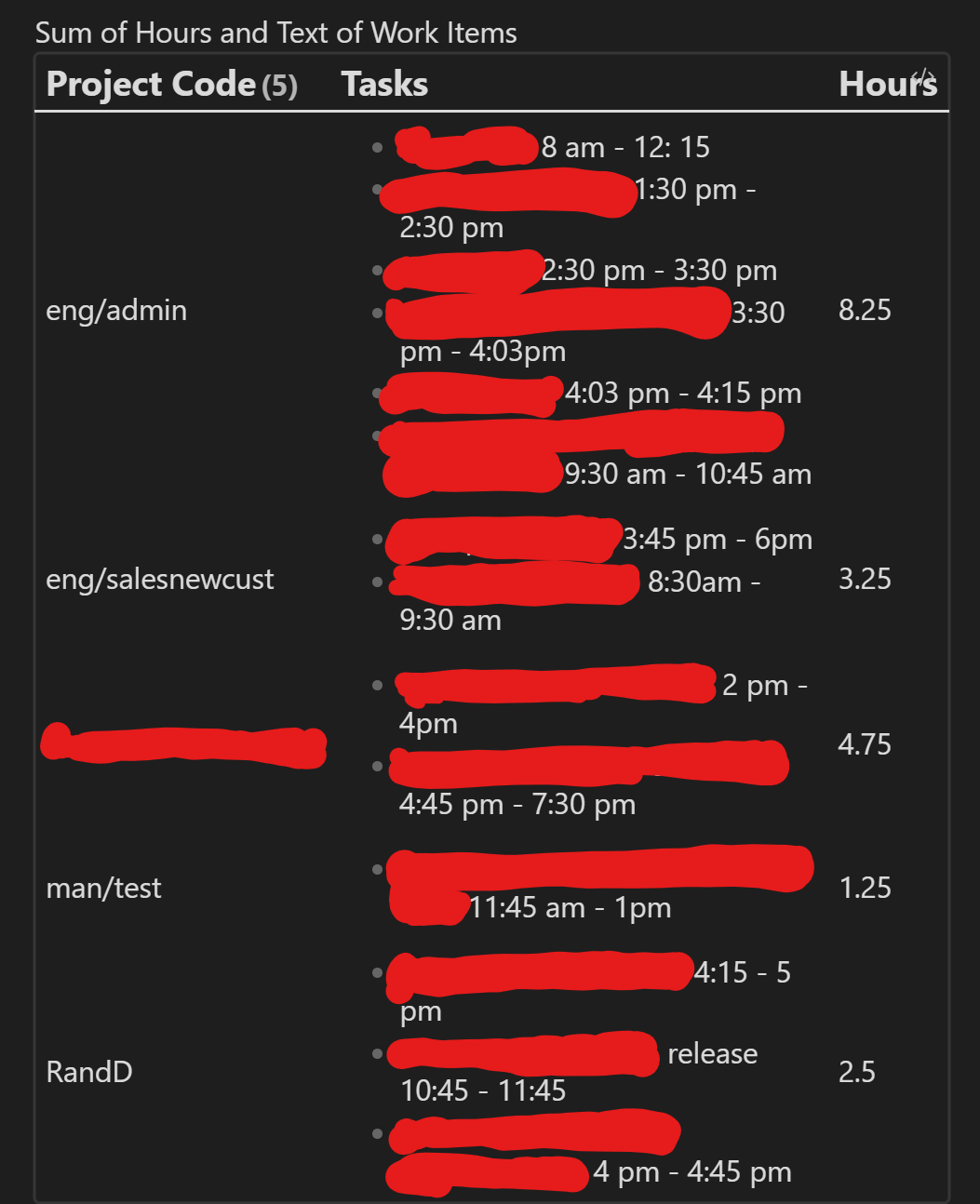
List the sum of hours worked across each unique project code as well as a total number of hours worked. The output should produce the following (formatting can differ):
- Project Code, Hours
- projectcode1: 8
- projectcode2: 1
- projectcode3: 2
- projectcode4: 1
- Total: 12
Things I have tried
As I’ve outlined three separate objectives I’ll share what I’ve done for each by the objective number in the list above:
- List of unique project codes
I’ve tried the following, though in each case it produces lists of unique job codes per file grouping them by file when I don’t want duplicates. Otherwise it does extract the embedded tags I want it just does not product a unique list across all files in the folder.
TABLE without id file.etags AS "Job Codes"
from "Daily Notes/2023/22. Week of May 29th"
TABLE file.etags AS "Job Codes"
from "Daily Notes/2023/22. Week of May 29th"
- List all Lines which contain
I’ve been able to implement this feature, thought it would be the most difficult but it ended up being alright, heres the solution:
TABLE L.text AS "My Lists"
FROM "Daily Notes/2023/22. Week of May 29th"
FLATTEN file.lists As L
WHERE contains(L.tags, "#")
SORT file.cday ASC
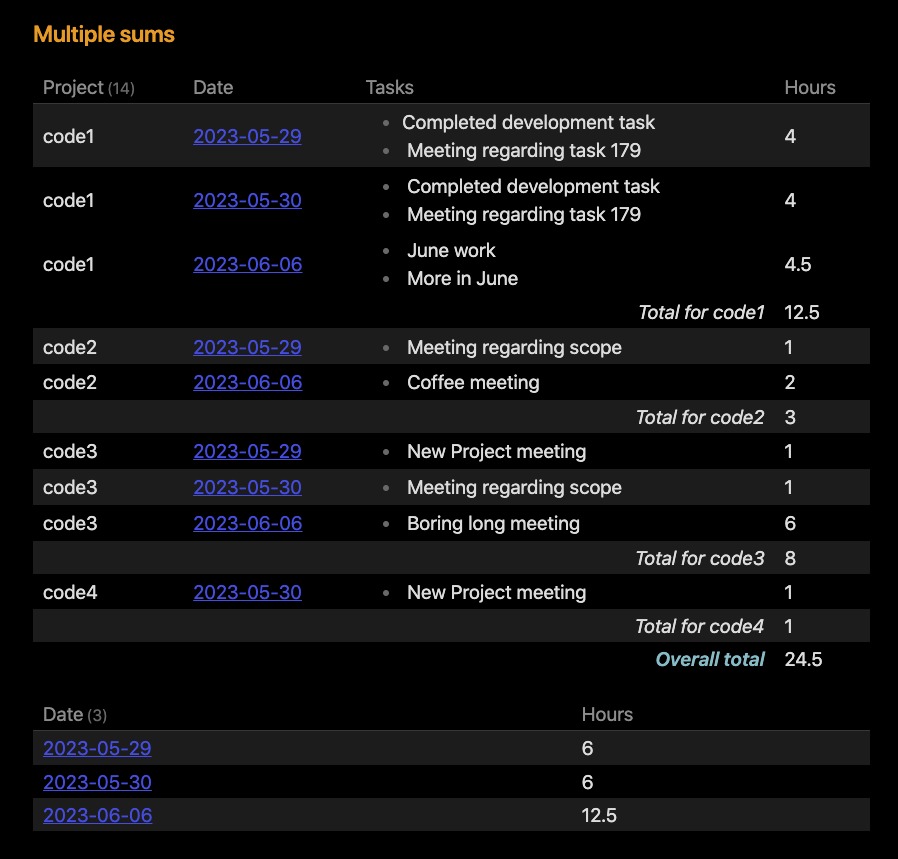
- List of sum of hours across each unique project code
I’ve tried something like the following which has yielded okay results but I’d like to generalize it so I don’t have to change the dataview command when the project codes change week to week. Ultimately it would be ideal to take the result from Objective 1 as a list of project codes which programmatically generates this table with those codes.
TABLE sum(projectcode1) as pc1, sum(projectcode2) as pc2, sum(projectcode3) as pc3, sum(projectcode4) as pc4, sum([sum(projectcode1), sum(projectcode2), sum(projectcode3), sum(projectcode4)]) as Total
from "Daily Notes/2023/22. Week of May 29th"
Thanks so much in advance. I look forward to suggestions on improving my question and resolve it!