Hi there,
I’ve been experimenting with topic modelling (NLP) to auto-generate MOCs in my vaults, via the Python data science stack. My largest vault (over 100k words across 500+ notes) has natural categories, so I didn’t need to create MOCs as I was building up the vault. The vault has my study notes for 11 module for my degree, so it was an interesting experiment to see if I could auto-generate MOCs that correspond to each module.
I’ve put my code on Github, so check out the notebooks and scripts on my obsidian-nlp-analytics repo.
I came across a topic modelling approach called Anchored CorEx, which seems quite versatile for this use case!
This only became possible for me to do since the latest version of my Python package obsidiantools, now that it can gather the plaintext of a vault’s notes in a format ready for NLP.
How is this different from other approaches?
The key difference from Robin Haupt’s popular plug-in is that my approach for auto-generating MOCs does NOT use wikilinks or the underlying graph structure to generate MOCs. I use text content across notes, rather than wikilinks.
There is more user overhead involved though, which I think carries its own advantages, as you specify keywords to influence the MOC generation and can make iterative improvements to the results.
Machine learning
I’ll explain more about the machine learning at play here. Feel free to skip to the next section if you want to see the results. ![]()
The TL;DR is: the topic modelling approach I’ve implemented involves semi-supervised learning (whereby the user specifies keywords to guide the topic modelling).
In the realm of machine learning, it seems like semi-supervised learning would work best for digital knowledge bases:
- Unsupervised learning can’t make use of nuances that humans have about their vaults. Semi-supervised approaches let humans bring in more context to influence the modelling. You probably have keywords that describe topics in your vault well, so it could be worthwhile to incorporate them in a model.
- With supervised learning, we would have labelled data for the problem. In my vault I do have 11 intuitive categories, so I could use those as labels, but it is clear that some notes do overlap across multiple categories based on their content. As you build larger vaults, categorisation can be difficult to scale. (That’s partly why people use MOCs in the first place
 , but if we can use a few labels to guide MOC creation then that does not have the scalability issue).
, but if we can use a few labels to guide MOC creation then that does not have the scalability issue).
The semi-supervised approach here takes user-provided keywords to guide the topic modelling.
Topic keywords
The Anchor CorEx algorithm lets a user specify keywords for each topic, also known as anchor words. ![]()
I specified a handful of anchor words for each topic. The authors of Anchored CorEx have a notebook that goes into more depth on the different strategies for specifying anchor words.
Let’s go to the results…
Results
Check out the notebook in my repo for the full commentary on the results.
![]() This image shows the value I got from the modelling:
This image shows the value I got from the modelling:
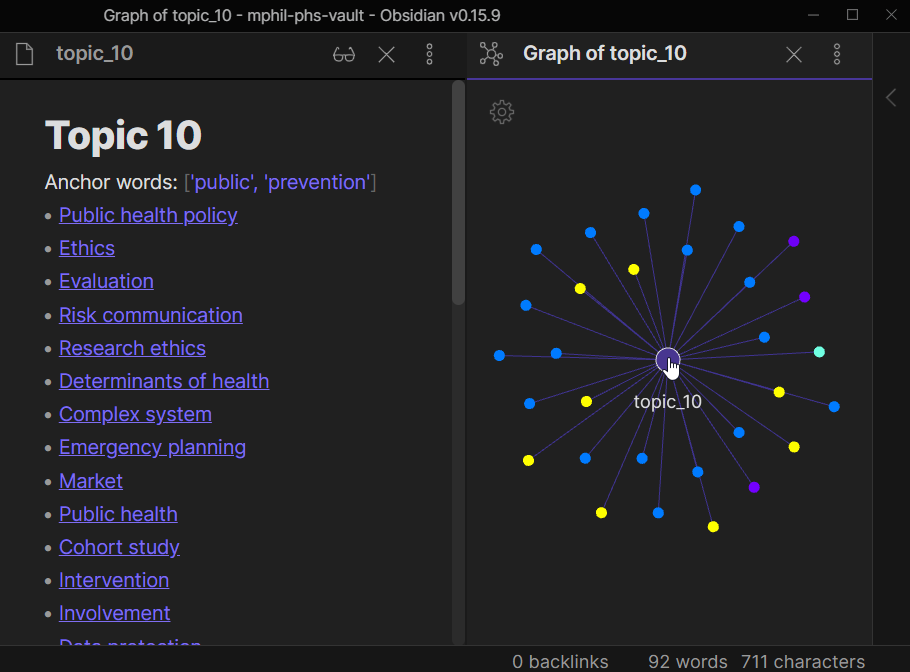
![]() My auto-generated MOC for the notes for my Public Health module! I used only two anchor words - ‘public’ and ‘prevention’ - to guide the modelling for its corresponding topic. In the local graph, most of the notes are coloured blue, which is great as they are the actual notes for that module. All this was done by an algorithm that has no information about the connections between notes.
My auto-generated MOC for the notes for my Public Health module! I used only two anchor words - ‘public’ and ‘prevention’ - to guide the modelling for its corresponding topic. In the local graph, most of the notes are coloured blue, which is great as they are the actual notes for that module. All this was done by an algorithm that has no information about the connections between notes.
My code exported MOCs for 11 topics to one folder. I copied those files into my vault and was able to use them straight away.
These are the most important words for each topic - numbered 0 to 10, with the public health words highlighted - as a result of fitting the model:

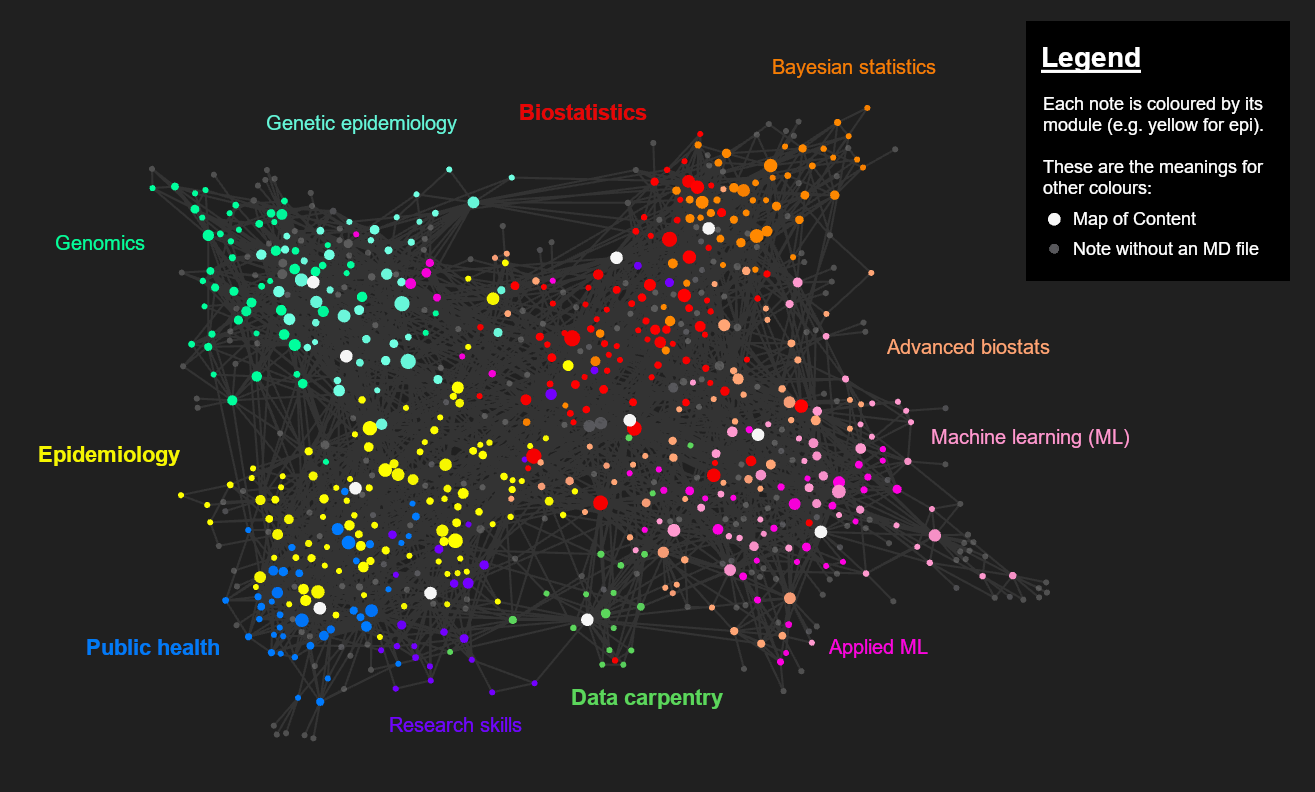
Now I have my MOCs in my Obsidian vault (coloured white in the graph below). It only took a few hours to experiment with the anchor words, in my first time implementing the algorithm, but I’m very pleased with the results. I don’t think I could ever have created ones that good manually. ![]() I now have these MOCs that I can use as navigational aides for a vault I’ve built across one year of full-time study.
I now have these MOCs that I can use as navigational aides for a vault I’ve built across one year of full-time study.
That’s all folks
Keen to get any thoughts about this approach. Maybe it would be challenging to get something like this in a plug-in, with all the Python packages involved. Happy to explain things a bit more, or even collaborate with anyone interested in getting something like this into a plug-in.