Here is another take on this query:
```dataview
TABLE length(rows.agendaTag)
FROM #Agenda
FLATTEN file.lists as item
FLATTEN item.tags as tag
FLATTEN regexreplace(tag, "#Agenda/", "") as agendaTag
WHERE file.name = this.file.name
WHERE item.task AND item.status != "x" AND startswith(tag, "#Agenda")
GROUP BY agendaTag
```
With my (random?) test setup this returns:
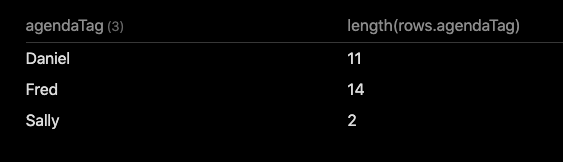
test setup
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Sally
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Sally
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred , #Yet/another/tag
- [x] Slightly repetitive task for #Agenda/Fred
- [x] Slightly repetitive task for #Agenda/Sally
- [x] Slightly repetitive task for #Agenda/Daniel
Ignore the first WHERE line, or adapt to your situation. This query uses flatten a lot, first to split the lists from the files into multiple item, then to split each of those items tags into separate tag, (which is also used to limit the query to only those starting with “#Agenda”), and then finally a flatten to reduce the agendaTag down to just the person.
Next step then is to group by the agendaTag (aka the person), and count the elements of the resulting rows.agendaTag set.
Note, if you want that output better, you can in this particular case replace TABLE with LIST in the query and get this output:
