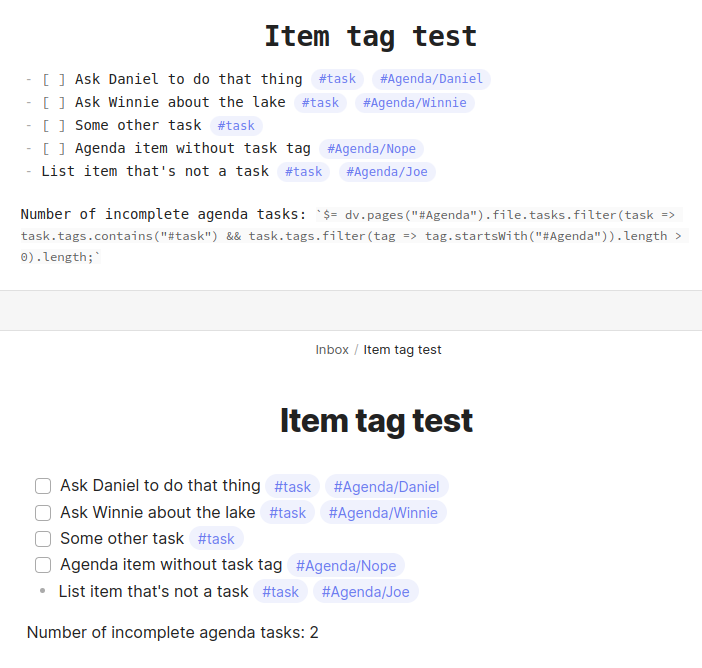
I use Tasks plugin extensively, and I have a nice system of remembering agenda items for people or projects by creating a tag like this in my notes:
[ ] Ask Daniel to do that thing #task#Agenda/Daniel
Then I have a query like this:
Agenda for next meeting
tags include #agenda/Daniel
not done
Works great.
What I’m trying to do
Now I want to add a section to my daily note template to do a COUNT of uncompleted tasks that have a tag starting with #Agenda/ so that I can see who I should be following-up with next.
Any suggestions? Either tasks plugin query or dataview query would be fine.
// Get all pages with #Agenda tag
dv.pages("#Agenda")
// Examine each task on the page
.file.tasks.filter(task =>
// Make sure it has the #task tag
task.tags.contains("#task")
// Make sute it has a tag starting with #Agenda
&& task.tags.filter(tag => tag.startsWith("#Agenda")).length > 0)
// Return number of matching tasks
.length;
// Get all pages with #Agenda tag
dv.pages("#Agenda")
// Examine each task on the page
.file.tasks.filter(task =>
// Make sure it has the #task tag
task.tags.contains("#task")
// Make sute it has a tag starting with #Agenda
&& task.tags.filter(tag => tag.startsWith("#Agenda")).length > 0
// Make sure it's not completed
&& !task.completed)
// Return number of matching tasks
.length;
This is so close to what I’m looking for. Or, maybe I’m misunderstanding the code: It seems to be counting up all #Agenda subtag, and no way to break down by the subtag.
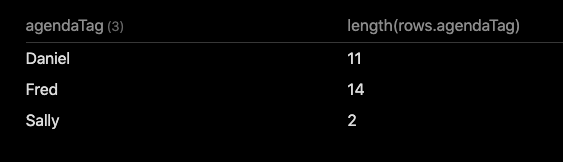
I should have been more clear; this is what I’m looking for
```dataview
TABLE length(rows.agendaTag)
FROM #Agenda
FLATTEN file.lists as item
FLATTEN item.tags as tag
FLATTEN regexreplace(tag, "#Agenda/", "") as agendaTag
WHERE file.name = this.file.name
WHERE item.task AND item.status != "x" AND startswith(tag, "#Agenda")
GROUP BY agendaTag
```
With my (random?) test setup this returns:
test setup
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Sally
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred
- [ ] Slightly repetitive task for #Agenda/Sally
- [ ] Slightly repetitive task for #Agenda/Daniel
- [ ] Slightly repetitive task for #Agenda/Fred , #Yet/another/tag
- [x] Slightly repetitive task for #Agenda/Fred
- [x] Slightly repetitive task for #Agenda/Sally
- [x] Slightly repetitive task for #Agenda/Daniel
Ignore the first WHERE line, or adapt to your situation. This query uses flatten a lot, first to split the lists from the files into multiple item, then to split each of those items tags into separate tag, (which is also used to limit the query to only those starting with “#Agenda”), and then finally a flatten to reduce the agendaTag down to just the person.
Next step then is to group by the agendaTag (aka the person), and count the elements of the resulting rows.agendaTag set.
Note, if you want that output better, you can in this particular case replace TABLE with LIST in the query and get this output:
To sort by it, you need to move it down to its own FLATTEN line, and then add the ordinary SORT line later on.
```dataview
LIST tagCount
FROM #Agenda
FLATTEN file.lists as item
FLATTEN item.tags as tag
FLATTEN regexreplace(tag, "#Agenda/", "") as agendaTag
WHERE file.name = this.file.name
WHERE item.task AND item.status != "x" AND startswith(tag, "#Agenda")
GROUP BY agendaTag
FLATTEN length(rows.agendaTag) as tagCount
SORT tagCount DESC
```