Wow, thanks a lot for that long post!!!
However, it’s kind of hard to understand your intention. Is this some kind of summary of good advises for working with dataview? Did you copy the parts out of some manual, if yes, which one?
Wow, thanks a lot for that long post!!!
However, it’s kind of hard to understand your intention. Is this some kind of summary of good advises for working with dataview? Did you copy the parts out of some manual, if yes, which one?
Hi Alan,
I have two questions to these lines of code, you proposed to me:
Thanks in advance!
Silias
dic_20040301
---
Date: 2004-03-01
---
#Project/P03
Areas:: #research
#### input
##### milestones
- 2004-03-01 add this feature_A #Test/d01 [[Note J]] , [[Note K]]
- 2004-03-02 add this feature_B #Test/d02 [[Note J]]
- 2004-03-03 add this feature_C [[Note K]]
- 2004-03-04 add this feature_D #Test/d04
- 2004-03-05 add this feature_E #Test/d05 [[Note K]]
- 2004-03-06 add this feature_F #Test/d06
- 2004-73-07 add this feature_G #Test/d07
- 2004-03-08 add this feature_H [[Note J]] , [[Note K]]
- 2004-03-09 add this feature_I
- 2004-03-10 add this feature_J
- It is finished!
>case_FLST_HLSS: use file.lists where L.text contains one field separator like " "
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
##### some events
- 2004-03-01 | drinks | Black Coffee | 11 | #Test/d01 [[Note J]] , [[Note K]]
- 2004-03-02 | drinks | Black Coffee | 21 | #Test/d02 [[Note J]]
- 2004-03-03 | drinks | Black Coffee | 31 | [[Note K]]
- 2004-03-04 | drinks | Black Coffee | 41 | #Test/d04
- 2004-03-05 | drinks | Black Coffee | 51 | #Test/d05 [[Note K]]
- 2004-03-06 | drinks | Black Coffee | 61 | #Test/d06
- 2004-73-07 | drinks | Black Coffee | 71 | #Test/d07
- 2004-03-08 | drinks | Black Coffee | 81 | [[Note J]] , [[Note K]]
- 2004-03-09 | drinks | Black Coffee | 91
- 2004-03-10 | drinks | Black Coffee
- It is finished!
>case_FLST_HLSSS: use file.lists where L.text contains at least one field separator like "|"
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
##### other events
- info:: 2004-03-01 | drinks | Black Coffee | 12 | #Test/d01 [[Note J]] , [[Note K]]
- info:: 2004-03-02 | drinks | Black Coffee | 22 | #Test/d02 [[Note J]]
- info:: 2004-03-03 | drinks | Black Coffee | 32 | [[Note K]]
- info:: 2004-03-04 | drinks | Black Coffee | 42 | #Test/d04
- info:: 2004-03-05 | drinks | Black Coffee | 52 | #Test/d05 [[Note K]]
- info:: 2004-03-06 | drinks | Black Coffee | 62 | #Test/d06
- info:: 2004-73-07 | drinks | Black Coffee | 72 | #Test/d07
- info:: 2004-03-08 | drinks | Black Coffee | 82 | [[Note J]] , [[Note K]]
- info:: 2004-03-09 | drinks | Black Coffee | 92
- info:: 2004-03-10 | drinks | Black Coffee
- It is finished!
>case_FLST_HLDSS: use file.lists where L.text consists of one DVIF and field separators
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
>S: field separators
##### what happened today?
- [type:: "food"] [desc:: "breakfast"] [cost:: 10] #Test/d01 [[Note J]] , [[Note K]]
- [type:: "food"] [desc:: "breakfast"] [cost:: 20] #Test/d02 [[Note J]]
>case_FLST_HLDDD: use file.lists where L.text consists of more than one DVIF
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
dic_20040306
---
Date: 2004-03-06
---
#Project/P03
Areas:: #research
##### input
###### milestones
- 2004-03-01 add this feature_A #Test/d01 [[Note J]] , [[Note K]]
- 2004-03-02 add this feature_B #Test/d02 [[Note J]]
- 2004-03-03 add this feature_C [[Note K]]
- 2004-03-04 add this feature_D #Test/d04
- 2004-03-05 add this feature_E #Test/d05 [[Note K]]
- 2004-03-06 add this feature_F #Test/d06
- 2004-73-07 add this feature_G #Test/d07
- 2004-03-08 add this feature_H [[Note J]] , [[Note K]]
- 2004-03-09 add this feature_I
- 2004-03-10 add this feature_J
- It is finished!
>case_FLST_HLSS: use file.lists where L.text contains one field separator like " "
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
###### some events
- 2004-03-01 | drinks | Black Coffee | 16 | #Test/d01 [[Note J]] , [[Note K]]
- 2004-03-02 | drinks | Black Coffee | 26 | #Test/d02 [[Note J]]
- 2004-03-03 | drinks | Black Coffee | 36 | [[Note K]]
- 2004-03-04 | drinks | Black Coffee | 46 | #Test/d04
- 2004-03-05 | drinks | Black Coffee | 56 | #Test/d05 [[Note K]]
- 2004-03-06 | drinks | Black Coffee | 66 | #Test/d06
- 2004-73-07 | drinks | Black Coffee | 76 | #Test/d07
- 2004-03-08 | drinks | Black Coffee | 86 | [[Note J]] , [[Note K]]
- 2004-03-09 | drinks | Black Coffee | 96
- 2004-03-10 | drinks | Black Coffee
- It is finished!
>case_FLST_HLSSS: use file.lists where L.text contains at least one field separator like "|"
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
###### other events
- info:: 2004-03-01 | drinks | Black Coffee | 17 | #Test/d01 [[Note J]] , [[Note K]]
- info:: 2004-03-02 | drinks | Black Coffee | 27 | #Test/d02 [[Note J]]
- info:: 2004-03-03 | drinks | Black Coffee | 37 | [[Note K]]
- info:: 2004-03-04 | drinks | Black Coffee | 47 | #Test/d04
- info:: 2004-03-05 | drinks | Black Coffee | 57 | #Test/d05 [[Note K]]
- info:: 2004-03-06 | drinks | Black Coffee | 67 | #Test/d06
- info:: 2004-73-07 | drinks | Black Coffee | 77 | #Test/d07
- info:: 2004-03-08 | drinks | Black Coffee | 87 | [[Note J]] , [[Note K]]
- info:: 2004-03-09 | drinks | Black Coffee | 97
- info:: 2004-03-10 | drinks | Black Coffee
- It is finished!
>case_FLST_HLDSS: use file.lists where L.text consists of one DVIF and field separators
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
>S: field separators
###### what happened today?
- [type:: "food"] [desc:: "dinner"] [cost:: 36] #Test/d03
- (type:: "food") (desc:: "dinner") (cost:: 46) #Test/d04
- (type:: "food") %%(desc:: "dinner")%% %%(cost:: 56)%% #Test/d05
- C1
- C2
- C3
- C4
- C5
- C6
>case_FLST_HLDDD: use file.lists where L.text consists of more than one DVIF
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
dic_20040401
---
Date: 2004-04-01
---
#Project/P04
Areas:: #mocap
## input
### main tasks
- [ ] 2004-04-01 add this feature_a #Test/d01 [[Note P]] , [[Note Q]]
- [ ] 2004-04-02 add this feature_b #Test/d02 [[Note P]]
- [ ] 2004-04-03 add this feature_c [[Note Q]]
- [ ] 2004-04-04 add this feature_d #Test/d04
- [x] 2004-04-05 add this feature_e #Test/d05 [[Note Q]]
- [ ] 2004-04-06 add this feature_f #Test/d06
- [ ] 2004-74-07 add this feature_g #Test/d07
- [ ] 2004-04-08 add this feature_h [[Note P]] , [[Note Q]]
- [ ] 2004-04-09 add this feature_i
- [ ] 2004-04-10 add this feature_j
- [ ] It is finished!
>case_FLST_HLSS: use file.lists where L.text contains one field separator like " "
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
### some tasks
- [ ] 2004-04-01 | drinks | Green Tea | 101 | #Test/d01 [[Note P]] , [[Note Q]]
- [ ] 2004-04-02 | drinks | Green Tea | 201 | #Test/d02 [[Note P]]
- [ ] 2004-04-03 | drinks | Green Tea | 301 | [[Note Q]]
- [ ] 2004-04-04 | drinks | Green Tea | 401 | #Test/d04
- [x] 2004-04-05 | drinks | Green Tea | 501 | #Test/d05 [[Note Q]]
- [ ] 2004-04-06 | drinks | Green Tea | 601 | #Test/d06
- [ ] 2004-74-07 | drinks | Green Tea | 701 | #Test/d07
- [ ] 2004-04-08 | drinks | Green Tea | 801 | [[Note P]] , [[Note Q]]
- [ ] 2004-04-09 | drinks | Green Tea | 901
- [ ] 2004-04-10 | drinks | Green Tea
- [ ] It is finished!
>case_FLST_HLSSS: use file.lists where L.text contains at least one field separator like "|"
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
### other tasks
- [ ] (info:: 2004-04-01 | drinks | Green Tea | 102) #Test/d01 [[Note P]] , [[Note Q]]
- [ ] (info:: 2004-04-02 | drinks | Green Tea | 202) #Test/d02 [[Note P]]
- [ ] (info:: 2004-04-03 | drinks | Green Tea | 302) [[Note Q]]
- [ ] (info:: 2004-04-04 | drinks | Green Tea | 402) #Test/d04
- [x] (info:: 2004-04-05 | drinks | Green Tea | 502) #Test/d05 [[Note Q]]
- [ ] (info:: 2004-04-06 | drinks | Green Tea | 602) #Test/d06
- [ ] (info:: 2004-74-07 | drinks | Green Tea | 702) #Test/d07
- [ ] (info:: 2004-04-08 | drinks | Green Tea | 802) [[Note P]] , [[Note Q]]
- [ ] (info:: 2004-04-09 | drinks | Green Tea | 902)
- [ ] (info:: 2004-04-10 | drinks | Green Tea)
- [ ] It is finished!
>case_FLST_HLDSS: use file.lists where L.text consists of one DVIF and field separators
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
>S: field separators
### what happened today?
- [ ] [type:: "food"] [desc:: "breakfast"] [cost:: 100] #Test/d01 [[Note P]] , [[Note Q]]
- [ ] [type:: "food"] [desc:: "breakfast"] [cost:: 200] #Test/d02 [[Note P]]
>case_FLST_HLDDD: use file.lists where L.text consists of more than one DVIF
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
dic_20040406
---
Date: 2004-04-06
---
#Project/P04
Areas:: #mocap
### input
#### main tasks
- [ ] 2004-04-01 add this feature_a #Test/d01 [[Note P]] , [[Note Q]]
- [ ] 2004-04-02 add this feature_b #Test/d02 [[Note P]]
- [ ] 2004-04-03 add this feature_c [[Note Q]]
- [ ] 2004-04-04 add this feature_d #Test/d04
- [x] 2004-04-05 add this feature_e #Test/d05 [[Note Q]]
- [ ] 2004-04-06 add this feature_f #Test/d06
- [ ] 2004-74-07 add this feature_g #Test/d07
- [ ] 2004-04-08 add this feature_h [[Note P]] , [[Note Q]]
- [ ] 2004-04-09 add this feature_i
- [ ] 2004-04-10 add this feature_j
- [ ] It is finished!
>case_FLST_HLSS: use file.lists where L.text contains one field separator like " "
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
#### some tasks
- [ ] 2004-04-01 | drinks | Green Tea | 101 | #Test/d01 [[Note P]] , [[Note Q]]
- [ ] 2004-04-02 | drinks | Green Tea | 201 | #Test/d02 [[Note P]]
- [ ] 2004-04-03 | drinks | Green Tea | 301 | [[Note Q]]
- [ ] 2004-04-04 | drinks | Green Tea | 401 | #Test/d04
- [x] 2004-04-05 | drinks | Green Tea | 501 | #Test/d05 [[Note Q]]
- [ ] 2004-04-06 | drinks | Green Tea | 601 | #Test/d06
- [ ] 2004-74-07 | drinks | Green Tea | 701 | #Test/d07
- [ ] 2004-04-08 | drinks | Green Tea | 801 | [[Note P]] , [[Note Q]]
- [ ] 2004-04-09 | drinks | Green Tea | 901
- [ ] 2004-04-10 | drinks | Green Tea
- [ ] It is finished!
>case_FLST_HLSSS: use file.lists where L.text contains at least one field separator like "|"
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
#### other tasks
- [ ] (info:: 2004-04-01 | drinks | Green Tea | 102) #Test/d01 [[Note P]] , [[Note Q]]
- [ ] (info:: 2004-04-02 | drinks | Green Tea | 202) #Test/d02 [[Note P]]
- [ ] (info:: 2004-04-03 | drinks | Green Tea | 302) [[Note Q]]
- [ ] (info:: 2004-04-04 | drinks | Green Tea | 402) #Test/d04
- [x] (info:: 2004-04-05 | drinks | Green Tea | 502) #Test/d05 [[Note Q]]
- [ ] (info:: 2004-04-06 | drinks | Green Tea | 602) #Test/d06
- [ ] (info:: 2004-74-07 | drinks | Green Tea | 702) #Test/d07
- [ ] (info:: 2004-04-08 | drinks | Green Tea | 802) [[Note P]] , [[Note Q]]
- [ ] (info:: 2004-04-09 | drinks | Green Tea | 902)
- [ ] (info:: 2004-04-10 | drinks | Green Tea)
- [ ] It is finished!
>case_FLST_HLDSS: use file.lists where L.text consists of one DVIF and field separators
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
>S: field separators
#### what happened today?
- [ ] [type:: "food"] [desc:: "dinner"] [cost:: 306] #Test/d03
- [x] (type:: "food") (desc:: "dinner") (cost:: 406) #Test/d04
- [ ] (type:: "food") %%(desc:: "dinner")%% %%(cost:: 506)%% #Test/d05
- [ ] C1
- [ ] C2
- [ ] C3
- [ ] C4
- [ ] C5
- [ ] C6
>case_FLST_HLDDD: use file.lists where L.text consists of more than one DVIF
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
dic_20040501
---
Date: 2004-05-01
---
#Project/P05
Areas:: #research
## input
### milestones
### some events
### other events
### what happened today?
dic_20040506
---
Date: 2004-05-06
---
#Project/P05
Areas:: #mocap
### input
#### main tasks
#### some tasks
#### other tasks
#### what happened today?
dic_20040601
---
Date: 2004-06-01
---
#Project/P06
Areas:: #research
#### input
##### milestones
- 2004-06-01 add this feature_P #Test/d01 [[Note J]] , [[Note K]]
- 2004-06-02 add this feature_Q #Test/d02 [[Note J]]
- 2004-06-03 add this feature_R [[Note K]]
- 2004-06-04 add this feature_S #Test/d04
- 2004-06-05 add this feature_T #Test/d05 [[Note K]]
- 2004-06-06 add this feature_U #Test/d06
- 2004-76-07 add this feature_V #Test/d07
- 2004-06-08 add this feature_W [[Note J]] , [[Note K]]
- 2004-06-09 add this feature_X
- 2004-06-10 add this feature_Y
- It is finished!
>case_FLST_HLSS: use file.lists where L.text contains one field separator like " "
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
##### some events
- 2004-06-01 | drinks | Hot Chocolate | 1001 | #Test/d01 [[Note J]] , [[Note K]]
- 2004-06-02 | drinks | Hot Chocolate | 2001 | #Test/d02 [[Note J]]
- 2004-06-03 | drinks | Hot Chocolate | 3001 | [[Note K]]
- 2004-06-04 | drinks | Hot Chocolate | 4001 | #Test/d04
- 2004-06-05 | drinks | Hot Chocolate | 5001 | #Test/d05 [[Note K]]
- 2004-06-06 | drinks | Hot Chocolate | 6001 | #Test/d06
- 2004-76-07 | drinks | Hot Chocolate | 7001 | #Test/d07
- 2004-06-08 | drinks | Hot Chocolate | 8001 | [[Note J]] , [[Note K]]
- 2004-06-09 | drinks | Hot Chocolate | 9001
- 2004-06-10 | drinks | Hot Chocolate
- It is finished!
>case_FLST_HLSSS: use file.lists where L.text contains at least one field separator like "|"
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
##### other events
- info:: 2004-06-01 | drinks | Hot Chocolate | 1002 | #Test/d01 [[Note J]] , [[Note K]]
- info:: 2004-06-02 | drinks | Hot Chocolate | 2002 | #Test/d02 [[Note J]]
- info:: 2004-06-03 | drinks | Hot Chocolate | 3002 | [[Note K]]
- info:: 2004-06-04 | drinks | Hot Chocolate | 4002 | #Test/d04
- info:: 2004-06-05 | drinks | Hot Chocolate | 5002 | #Test/d05 [[Note K]]
- info:: 2004-06-06 | drinks | Hot Chocolate | 6002 | #Test/d06
- info:: 2004-76-07 | drinks | Hot Chocolate | 7002 | #Test/d07
- info:: 2004-06-08 | drinks | Hot Chocolate | 8002 | [[Note J]] , [[Note K]]
- info:: 2004-06-09 | drinks | Hot Chocolate | 9002
- info:: 2004-06-10 | drinks | Hot Chocolate
- It is finished!
>case_FLST_HLDSS: use file.lists where L.text consists of one DVIF and field separators
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
>S: field separators
##### what happened today?
- [type:: "food"] [desc:: "breakfast"] [cost:: ] #Test/d01 [[Note K]]
- [type:: "food"] [desc:: "breakfast"] [cost:: 2000] #Test/d02 [[Note J]]
>case_FLST_HLDDD: use file.lists where L.text consists of more than one DVIF
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
dic_20040701
---
Date: 2004-07-01
---
#Project/P07
Areas:: #mocap
## input
### main tasks
- [ ] 2004-07-01 add this feature_p #Test/d01 [[Note P]] , [[Note Q]]
- [ ] 2004-07-02 add this feature_q #Test/d02 [[Note P]]
- [ ] 2004-07-03 add this feature_r [[Note Q]]
- [ ] 2004-07-04 add this feature_s #Test/d04
- [x] 2004-07-05 add this feature_t #Test/d05 [[Note Q]]
- [ ] 2004-07-06 add this feature_u #Test/d06
- [ ] 2004-77-07 add this feature_v #Test/d07
- [ ] 2004-07-08 add this feature_w [[Note P]] , [[Note Q]]
- [ ] 2004-07-09 add this feature_x
- [ ] 2004-07-10 add this feature_y
- [ ] It is finished!
>case_FLST_HLSS: use file.lists where L.text contains one field separator like " "
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
### some tasks
- [ ] 2004-07-01 | drinks | Iced Chocolate | 10001 | #Test/d01 [[Note P]] , [[Note Q]]
- [ ] 2004-07-02 | drinks | Iced Chocolate | 20001 | #Test/d02 [[Note P]]
- [ ] 2004-07-03 | drinks | Iced Chocolate | 30001 | [[Note Q]]
- [ ] 2004-07-04 | drinks | Iced Chocolate | 40001 | #Test/d04
- [x] 2004-07-05 | drinks | Iced Chocolate | 50001 | #Test/d05 [[Note Q]]
- [ ] 2004-07-06 | drinks | Iced Chocolate | 60001 | #Test/d06
- [ ] 2004-77-07 | drinks | Iced Chocolate | 70001 | #Test/d07
- [ ] 2004-07-08 | drinks | Iced Chocolate | 80001 | [[Note P]] , [[Note Q]]
- [ ] 2004-07-09 | drinks | Iced Chocolate | 90001
- [ ] 2004-07-10 | drinks | Iced Chocolate
- [ ] It is finished!
>case_FLST_HLSSS: use file.lists where L.text contains at least one field separator like "|"
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>S: field separators
### other tasks
- [ ] (info:: 2004-07-01 | drinks | Iced Chocolate | 10002) #Test/d01 [[Note P]] , [[Note Q]]
- [ ] (info:: 2004-07-02 | drinks | Iced Chocolate | 20002) #Test/d02 [[Note P]]
- [ ] (info:: 2004-07-03 | drinks | Iced Chocolate | 30002) [[Note Q]]
- [ ] (info:: 2004-07-04 | drinks | Iced Chocolate | 40002) #Test/d04
- [x] (info:: 2004-07-05 | drinks | Iced Chocolate | 50002) #Test/d05 [[Note Q]]
- [ ] (info:: 2004-07-06 | drinks | Iced Chocolate | 60002) #Test/d06
- [ ] (info:: 2004-77-07 | drinks | Iced Chocolate | 70002) #Test/d07
- [ ] (info:: 2004-07-08 | drinks | Iced Chocolate | 80002) [[Note P]] , [[Note Q]]
- [ ] (info:: 2004-07-09 | drinks | Iced Chocolate | 90002)
- [ ] (info:: 2004-07-10 | drinks | Iced Chocolate)
- [ ] It is finished!
>case_FLST_HLDSS: use file.lists where L.text consists of one DVIF and field separators
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
>S: field separators
### what happened today?
- [ ] [type:: "food"] [desc:: "breakfast"] [cost:: ] #Test/d01 [[Note Q]]
- [ ] [type:: "food"] [desc:: "breakfast"] [cost:: 20000] #Test/d02 [[Note P]]
>case_FLST_HLDDD: use file.lists where L.text consists of more than one DVIF
>FLST: Use file.lists
>H: a header
>L : an element of file.lists
>D: DVIF
Oh, anytime!
DQL07_flatten_fLists_groupBy_fLink_and_display_list_items_and_task_items_under_the_heading in the following topic.
FROM source for best performance when using DQL?F_subpath to filter by the specific heading when using DQL?DVJS01_groupBy_fLink_flatten_fLists_and_taskList in the following topic.
WHERE contains(F_subpath, "what happened today") AND F_type = "header"
WHERE contains(F_subpath, "what happend") AND F_type = "header"
// M31.FR13 define a_filtered_lists:
// FLATTEN page.file.lists and gather them:
// get items under the heading "Summary"
// #####################################################################
let a_filtered_lists = group.rows
.flatMap((page) => page.file.lists)
.where(
(L) => dv.func.contains(L.header.subpath, "what happened today") &&
L.header.type === "header"
);
// M31.FR13 define a_filtered_lists:
// FLATTEN page.file.lists and gather them:
// get items under the heading "Summary"
// #####################################################################
let a_filtered_lists = group.rows
.flatMap((page) => page.file.lists)
.where(
(L) => dv.func.contains(L.header.subpath, "what happened") &&
L.header.type === "header"
);
That gets a little tricksy, but not hard to do.
The search is using what’s called a “regular expression”, or “regex”:
To find any headers that contain the text “what happened”, change the variable like so:
const header = '#+ [^\n]*?what happened'
This is looking for:
#+ match any line that starts with any number of hash symbols followed by a space, i.e. any header level[^\n]*? match any character that is NOT a new line characterwhat happened match your exact textJust check the Dataview docs, or any of the many threads on this forum talking about how to use Dataview:
https://blacksmithgu.github.io/obsidian-dataview/data-queries/
Here’s how you find only pages with a daily tag:
const pages = dv.pages('#daily')
Hi Alan,
thanks again for your tipps.
Unfortunately, they aren’t working yet.
This is my actual code (which I have from you), which searches all of my files and works pretty good, but needs some time, to load (the ``` at the beginning and the end of the code are not shown):
dataviewjs
const header = '## What happend today\\?'
// You can update this to filter as you like - filtering for just your daily notes would be good
const pages = dv.pages().sort(x => x.file.name, 'desc')
// This regex will return text from the Summary header, until it reaches
// the next header, a horizontal line, or the end of the file
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n#+ |\n---|$)`, 's')
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
// Read the file contents
const contents = await app.vault.read(file)
// Extract the summary via regex
const summary = contents.match(regex)
if (summary && summary[1].trim()) {
// Output the header and summary
dv.header(2, file.basename)
dv.paragraph(summary[1].trim())
}
}
And here’s my code, with your first tipp included:
dataviewjs
const header = '#+ [^\n]*?what happened'
// You can update this to filter as you like - filtering for just your daily notes would be good
const pages = dv.pages().sort(x => x.file.name, 'desc')
// This regex will return text from the Summary header, until it reaches
// the next header, a horizontal line, or the end of the file
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n#+ |\n---|$)`, 's')
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
// Read the file contents
const contents = await app.vault.read(file)
// Extract the summary via regex
const summary = contents.match(regex)
if (summary && summary[1].trim()) {
// Output the header and summary
dv.header(2, file.basename)
dv.paragraph(summary[1].trim())
}
}
Result:
Unfortunately, it doesnt show anything…
And here’s my code, with your second tipp included:
dataviewjs
const header = '## What happend today\\?'
// You can update this to filter as you like - filtering for just your daily notes would be good
const pages = dv.pages('#daily').sort(x => x.file.name, 'desc')
// This regex will return text from the Summary header, until it reaches
// the next header, a horizontal line, or the end of the file
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n#+ |\n---|$)`, 's')
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
// Read the file contents
const contents = await app.vault.read(file)
// Extract the summary via regex
const summary = contents.match(regex)
if (summary && summary[1].trim()) {
// Output the header and summary
dv.header(2, file.basename)
dv.paragraph(summary[1].trim())
}
}
Same here, no result…
I assume, I inserted your additions at the wrong place, or did something else wrong?
Thanks in advance!
kind regards,
Silias
Here’s a 100% working demo vault.
It looks for all notes with the #daily tag, and which have a heading that contains the words “what happened”.
Go to the Dataview code note.
Hi Alan,
wow, thanks!!! Your Demo vault works perfectly!
Now a few last question to your demo vault:
In your demo vault, the headers in all files with the hashtag #daily, are searched for the string “what happend”.
=> Questions:
How should I modify that search, if
Thanks ![]()
As in my previous message, I recommend that you have a look at a beginners Javascript course. There’s an amazing German instructor who I love, and this is where I learned Javascript:
https://www.udemy.com/course/javascript-the-complete-guide-2020-beginner-advanced/
It’s very easy, and it will open up a world of possibilities for you in Obsidian and so many other applications. The course should be around $10. If not, wait until Udemy has a discount (every other day basically).
Thanks for the code. I’ve got a Regex problem. As far as I understand Regex doesn’t recognize Turkish characters. Such as “şüğçöıİÜĞÇÖŞ”. I’ve got these characters in my heading. How can I get regex to find them?
I’ve found jquery - Javascript: RegExp Turkish Character Issue - Stack Overflow this. But didn’t understand how to solve it.
The problem in the linked post is that word boundaries (\b) don’t work with Turkish characters. That probably isn’t your issue, though.
Make sure you’ve rewritten this line to match the correct pages (e.g. using the right tag):
const pages = dv.pages('#daily').sort((x) => x.file.name, 'desc');
If that doesn’t fix anything, comment with your note’s markdown and your dataviewjs code. We can double-check your work with you.
I’ve changed it to #günlük. If I use a header that doesn’t contain Turkish characters there is no problem. But when I use Turkish chars it fails.
Below is my code and error I’ve got.
After seeing the post, I noticed Allah'a “a” was highlighted. So I changed the header to const header = '## Şükürler olsun ki: ' now it works. Maybe the problem was '.
Thanks for your interest. ![]()
```dataviewjs
const header = '## Allah'a şükürler olsun ki:'
// You can update this to filter as you like - filtering for just your daily notes would be good
const pages = dv.pages('#günlük').sort(x => x.file.name, 'desc')
// This regex will return text from the Summary header, until it reaches
// the next header, a horizontal line, or the end of the file
const regex = new RegExp(`\n${header}\r?\n(.*?)(\n#+ |\n---|$)`, 's')
for (const page of pages) {
const file = app.vault.getAbstractFileByPath(page.file.path)
// Read the file contents
const contents = await app.vault.read(file)
// Extract the summary via regex
const summary = contents.match(regex)
if (summary) {
// Output the header and summary
dv.header(2, file.basename)
dv.paragraph(summary[1].trim())
}
}
Evaluation Error: SyntaxError: Unexpected identifier
at DataviewInlineApi.eval (plugin:dataview:19669:21)
at evalInContext (plugin:dataview:19670:7)
at asyncEvalInContext (plugin:dataview:19677:16)
at DataviewJSRenderer.render (plugin:dataview:19701:19)
at DataviewJSRenderer.onload (plugin:dataview:19285:14)
at DataviewJSRenderer.e.load (app://obsidian.md/app.js:1:730611)
at t.e.addChild (app://obsidian.md/app.js:1:731035)
at t.addChild (app://obsidian.md/app.js:1:1646061)
at Object.addChild (app://obsidian.md/app.js:1:1645086)
at DataviewApi.executeJs (plugin:dataview:20210:19)
at DataviewPlugin.dataviewjs (plugin:dataview:20708:18)
at eval (plugin:dataview:20632:105)
at t.render (app://obsidian.md/app.js:1:1644987)
at enter (app://obsidian.md/app.js:1:1655590)
at e.iterate (app://obsidian.md/app.js:1:293053)
at ei.iterate (app://obsidian.md/app.js:1:1541428)
at e.update [as updateF] (app://obsidian.md/app.js:1:1652588)
at Object.update (app://obsidian.md/app.js:1:347440)
at e. (app://obsidian.md/app.js:1:358213)
at Pr (app://obsidian.md/app.js:1:351383)
at new e (app://obsidian.md/app.js:1:357239)
at e.applyTransaction (app://obsidian.md/app.js:1:358155)
at e.get (app://obsidian.md/app.js:1:353387)
at e.update (app://obsidian.md/app.js:1:495674)
at e._dispatch (app://obsidian.md/app.js:1:493593)
at e.dispatch (app://obsidian.md/app.js:1:495249)
at app://obsidian.md/app.js:1:1656774
at r (plugin:obsidian-kindle-plugin:333:35922)
Yes, the ' was causing your problem. You should be able to fix the issue without changing your header, then. Use double-quotes instead of single-quotes in the code, like so:
const header = "## Allah'a şükürler olsun ki:"
Cheers.
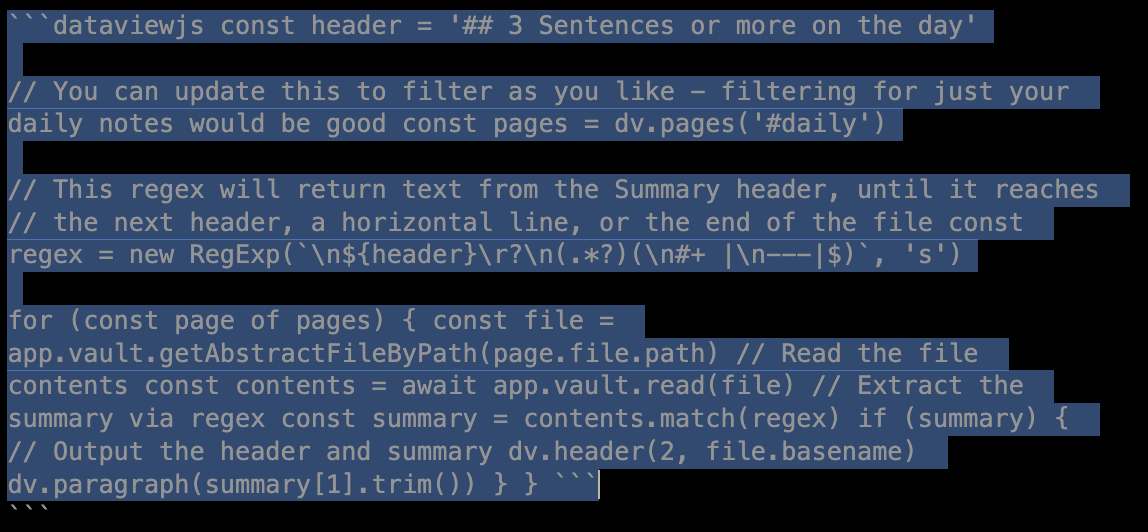
I’m trying to get this working with my daily notes. I have my daily notes tagged #daily and I’m trying to compile the section 3 Sentences or more on the day to another note.
This is what the code I have in there looks like:
I get the error message below, any tips?
Evaluation Error: SyntaxError: Unexpected end of input
at DataviewInlineApi.eval (plugin:dataview:19669:21)
at evalInContext (plugin:dataview:19670:7)
at asyncEvalInContext (plugin:dataview:19677:16)
at DataviewJSRenderer.render (plugin:dataview:19701:19)
at DataviewJSRenderer.onload (plugin:dataview:19285:14)
at DataviewJSRenderer.e.load (app://obsidian.md/app.js:1:730611)
at t.e.addChild (app://obsidian.md/app.js:1:731035)
at t.eval (plugin:obsidian-query-control:6:6224)
at t.n [as addChild] (plugin:obsidian-query-control:6:1118)
at t.addChild (app://obsidian.md/app.js:1:1646061)
You should reformat your code block to look like the other ones in this thread.
Hi Alan,
I tried a few things in the code from above. I also read the dataviewjs-docu, but didn’t learn enough, to succesfully modify the code from above, the way I want to.
The first 2 bullet points from my post from Sept. 13th can be solved with the dataviewjs-docu, the last one unfortunately not.
So I have to ask you a last time for your help for the third bullet point: ![]()
This usecase now isn’t a daily notes summary, but a summary of all headers and its content, with the word “frank” in the header. Dataviewjs should just search one specific file.
When I insert the filename “file.md” in your code here …
const pages = dv.pages('"folder/file.md"').sort(x => x.file.name, 'desc')
I realised, that the dataviewjs-query stopps after it encounters the first match.
=> … would it be possible to modify that code, that all headers (with their contents) in one file, that contain the search-word, are returned?
Thank you so much!
You just need to update the regex to do a global search first ('sg'), and then loop through the results.
You can download the demo vault and copy the method used in this post:
Hi, I want to turn the file name in the result into a link that can be clicked to jump, so I changed dv.header(2, file.basename) to dv.header(2, file.link) or dv.header(2, file. filelink), but it failed. Am I missing something?
Best regards.
page.file.link or '[[' + file.basename + ']]'
Thank you!