I have imported my handwritten notes from goodNotes to obsidian and want to enable a search for handwritten notes.
Things I have tried
I have installed and enabled Omnisearch and Text Extractor plugin, PDF and Image Indexing are also enabled but when I am doing omnisearch, it’s not showing any handwritten notes in a search result.
Unfortunately, there’s virtually 0 chance that Text Extractor will be able to extract handwritten content.
PDFs are not OCRed, they’re just “read” by Text Extract, which tries to find embedded text.
Image files are OCRed with Tesseract, which is not trained for handwriting.
The only way that could work is if 1) your PDF has been “pre-OCRed” by another process (such as Adobe), 2) the resulting text is saved inside the PDF, and 3) Text Extractor can find that text.
I’ve not worked with the Text Extractor plugin, or the other tools you mention, but the text you provided as example in that last part, could that be stripped of all white space, and then be used in your search?
It seems like that text just introduces a lot of spaces where you didn’t intend for them to be, but other than that the text seems to be coherent enough for searching.
You could end up with some false positives if you search for something which happens to be the end of one word and the start of another. (Like if you searched the previous sentence for “fan”, it would render a hit on “oFANother”). But no sure if this in general would be a great issue.
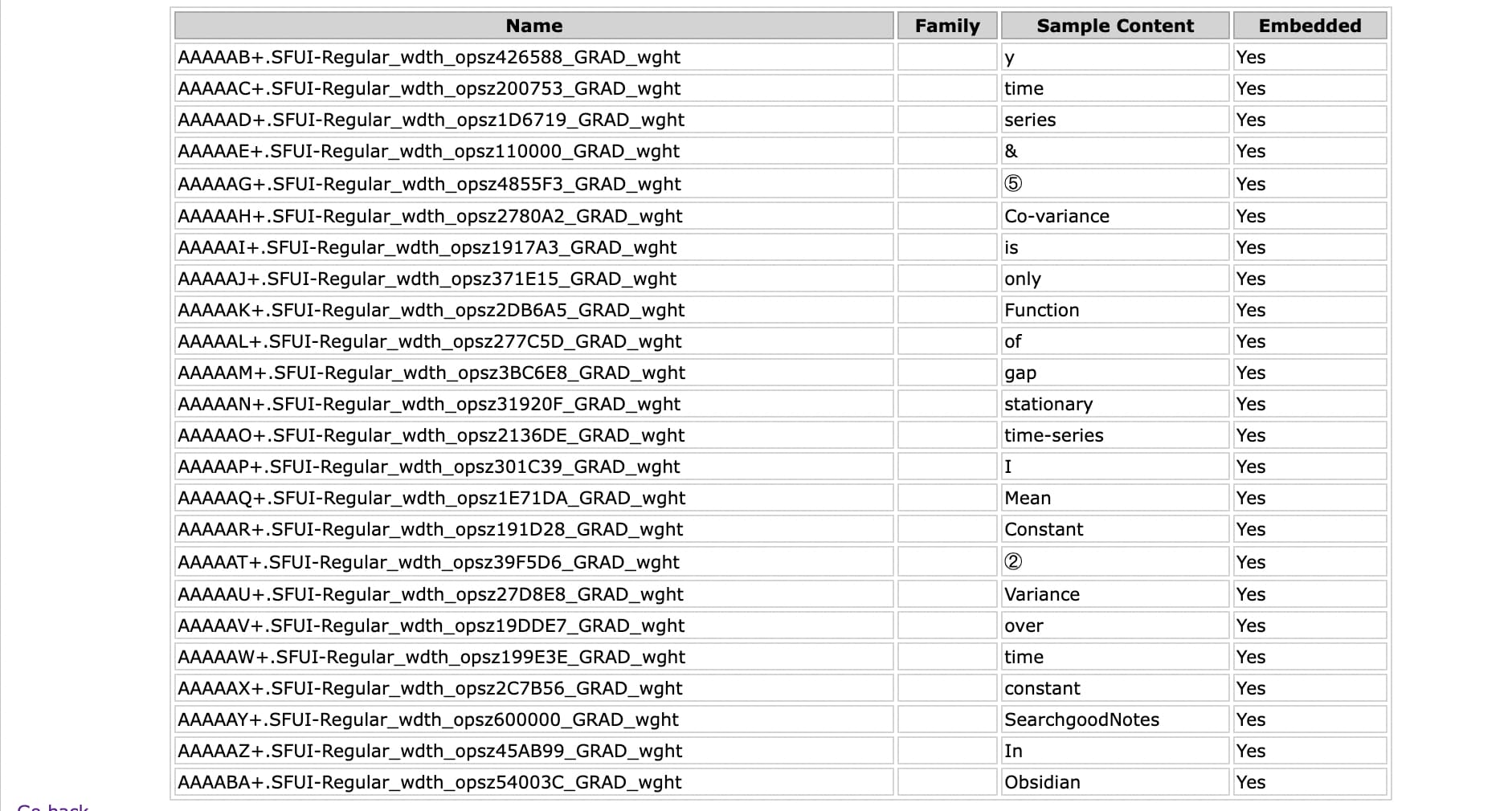
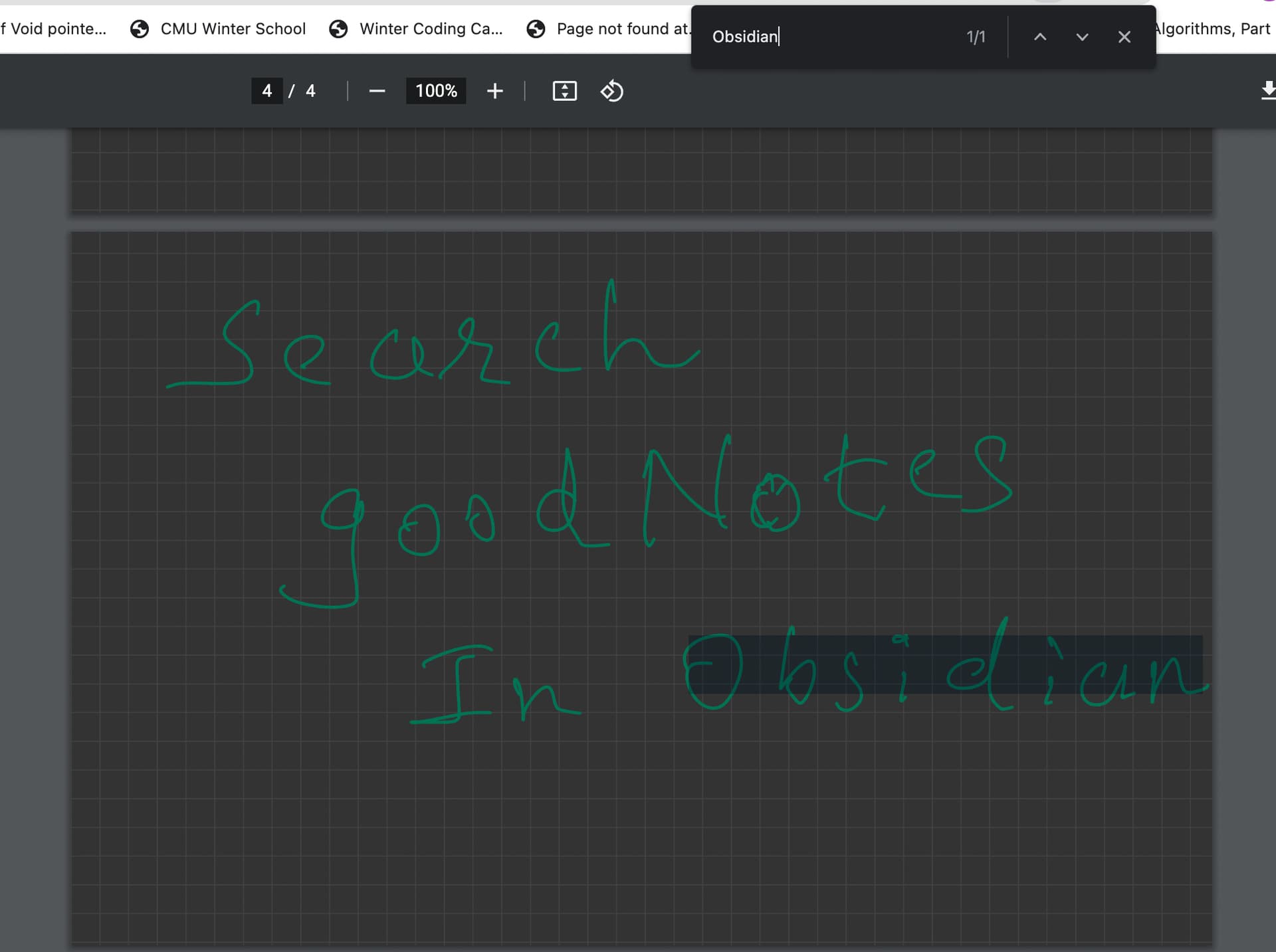
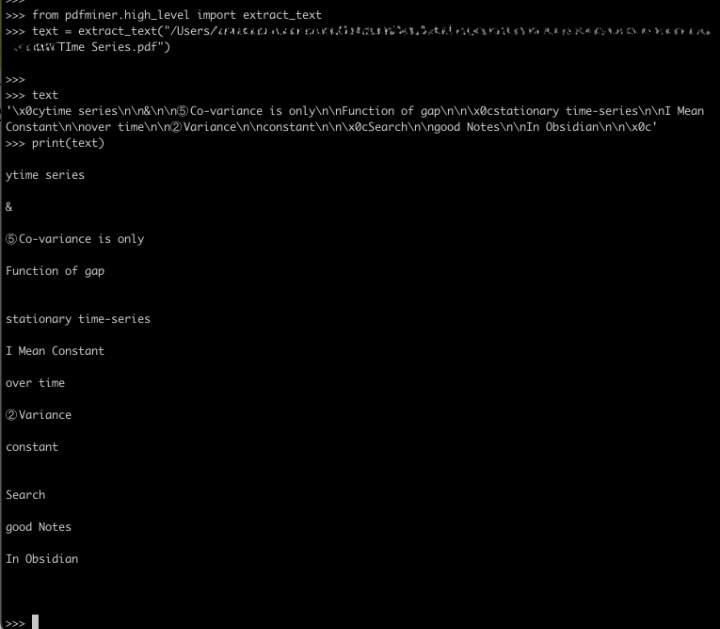
@holroy I was thinking on a similar line. If the extractor strips off all the white space, the text will be searchable though not correct 100%, it would be a temporary fix. The better option is to use the embedded text properly. I don’t see any space in the embedded text.
I tried pdfminer and the result is encouraging. As all the text is embedded in the PDF it was able to extract the text with quite a good accuracy. @scambier maybe text-extractor was not extracting these embedded texts but it was using tesseract to ORC the pdf, which is not very accurate. Is it possible to use these or any better API, I am ready to spend some time and contribute back.