The concept of Personal Knowledge Graphs is relatively new but has its roots in the broader field of Knowledge Management Systems. These systems have evolved over the years, from simple note-taking apps to complex platforms that allow for the interlinking of information. The video mentions that the first personal knowledge graph system was designed by a German sociologist named Luman in the 1970s. He used a simple shoebox and pieces of paper to create a system of interlinked nodes, effectively creating the first Personal Knowledge Graph.
Why Personal Knowledge Graphs Matter
Personal Knowledge Graphs are not just for tech giants like Google or insurance companies that collect data to optimize their services. They are for individuals who want to take control of their data and information. The graphs allow for a more natural representation of knowledge, making it easier to find connections and derive new insights.
The Evolution of Tools
First Generation
The first generation of tools focused on note-taking but lacked the ability to create relations between notes. Information was siloed in different apps, making it difficult to see the bigger picture.
Second Generation
The second generation, exemplified by tools like Roam Research, introduced the concept of links and backlinks. This allowed for the creation of a more interconnected graph of nodes, revolutionizing the way we think about note-taking and information management.
Notable apps
Roam research
Obsidian
logseq
Third Generation
The third generation, which is still emerging, aims to leverage artificial intelligence to work directly with the graph. This will allow for more complex queries and the ability to derive new information from existing relations. We have a big hope for AI agent that will help to create and mantain a PKG for user from a endless data streams. We have a too technical tools for Knowledge Graphs
RDF and Linked data
SPARQL
Semantic data
All this is powerful instruments but to technical for user.
To turn a Obsidian to a Third generation tool we just need to make Links first class citizens and give posibility to create a metadata for links .
I think exploring the relationship between modern PKM tools and ideas from the semantic web (RDF, SPARQL) is a interesting.
The semantic web didn’t lift off as much as some people had hoped, maybe because it is hard to make schemas uniform across different organizations. That makes it difficult to exploit semantic data despite our best efforts. Natural language based strategies (ChatGPT) have proven much more effective at this and do not require manual annotations. Also, semantic triplet databases required to exploit data from the semantic web have trouble scaling up to very large databases.
However, I agree that ideas from the semantic web could be useful within a vault. You see them popping up with the new frontmatter tools in Obsidian, as well as Tana and Anytype. They all add semantic labelling on top of notes.
One idea from the semantic web I tried to incorporate in my vault is the notion that a type is a URL. Lately I’ve been using the type key in my frontmatter that points to a note in my vault. That note describes what the type is, and how its content should be interpreted.
I disagree with your nomenclature: what you named Third generation tools have been around for much longer than the second generation tools, so using a temporal label could lead to confusion.
To turn a Obsidian to a Third generation tool we just need to make Links first class citizens and give posibility to create a metadata for links .
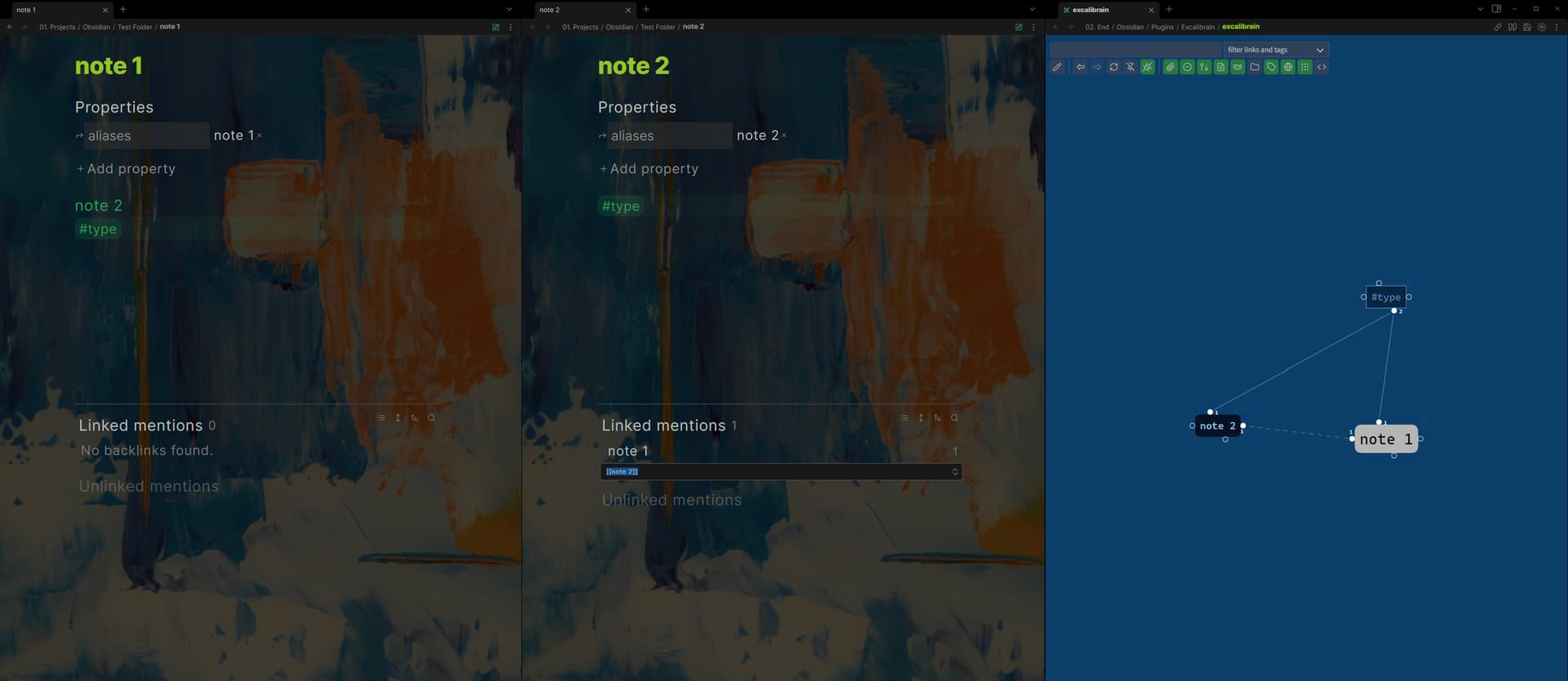
This is possible with some plugins. Typed links are a feature of the Jugl Plugin. However, for my purposes, I found that Excalibrain is sufficient and more accessible. You can acheive the effect of typed links by using tags.
#personalinowledgegraph is used for a long times in enterprise. We want to shift it closer to a user day today life and give user a new tools.
Unfortunately market do not have easy to use tools for pkg for non professionals.
Let’s see how #obsidian or #logseq could help to make a first steps in this journey.
My humble opinion - we need #ai for a graph construction .
At mykin.ai we use #ai agents in tandem with personal knowledge graphs . Try future today
I am about to publish an article How To that shows how I turned Obsidian into an open source intelligence analysis tool. The first part covers adding and using semantic data. It’s a limited use case but very powerful. For seasoned Obsidian geeks, you’ll be able to see how useful this can be and how flexible it is.
For those of you that don’t know, it’s possible to put simple metadata on links using Graph Link Types. The syntax is [property::[[link]]]. This creates a keypair looking bit of text… that’s how you know it works. I like this because you can store it directly in your notes like this.
The thing about Obsidian is that it’s just a simple markdown note tool. Files are in plaintext and stored not in the cloud but locally on the drive unless you load it on to a cloud server. That means you can literally do just about anything you want with it. In addition to the built in feature to build a graph using whatever query you want (ie tags, links, etc). You also get the ability to utilize any service or backend you want for your markdown files. The semantic web is just a way for web crawlers, search engines, & AI to make sense of the content being displayed on the web page. It’s not rendered in the browser. So users don’t see it.
There’s different ways to semantically make web pages. You can make semantic markup that describe the relationships between the different parts of the document. You also are able ascribe MEANING or CONNECTION to the parts of the web page that is isn’t displayed in the browser. These things are usually for computers that are looking for those things. We have HTML for starters. To semantically define structure and “mark up” the web page into structural elements. These tags already exist and you don’t have to make any modifications or utilize any technology to use it. You just literally need to add tags within the elements to describe what they are doing.
There’s different types of ways to markup the documents that are usually domain specific but easy to understand and follow. There’s also, ones for classifying all types of knowledge that are like way beyond what is required for obsidian. But each type of tag scheme for lack of a better word has a schema that can be referenced by using its schema. The schema validates the documents definitions and types used via a link to the schema version link or meta tag. So it’s all automatic and even defines types for you so you don’t have to.
The type of schema design that you use can be modeled in a graph database. There’s a few things that are needed for a graph database and they are basically all covered by the usage of the tags. The provide enough detail to create instances of the objects and create vertices that connect each node.
In aggregate, the graph database allows you to see the connections between each of the tags used. You have to choose how to tag your data and make sure it’s sound in design because the data has to be queried. Traversing the tree is a hassle if you have too many tags or under utilize them. Using a good PKM system which is technology agnostic btw. It’s about how you set up your organization and structure your data. Not unlike the difference between a graph db and a relational one. They are both databases but with different goals and use cases. Each structuring their data in different logical configurations that allows for new types of queries and data analysis. Search times are also impacted by the setup too which is why careful consideration of use cases is essential for understanding which one is best suited for you.
Obsidian also allows for linking to notes, tags, urls, backlinks, and other types of properties that all can be used to create substantial graph database that visually seeing how ideas are literally linked together (if carefully planned and implemented) can truly help you to understand unusual patterns or 2 ideas that don’t see similar can easily have a few connections. Seeing them connected can help you fill in the missing piece or take a new approach to your work or PKM.
** Side question: Truly there’s nothing about 3rd gen to me that separates it from the other generation other than the AI tools? Is the question about getting to the nature of one’s own inner processes and understanding? Or a genuine question about the usefulness of making your data AI compatible? I think the point is to create a searchable and easy way to query your own notes or knowledge base. AI tools can definitely facilitate that functionality but not the standard consumer chatbots. You have to run your own agents with access to your data structure not like a file upload to ChatGPT. **
i like this and totally agree with it vop , our data is the most valuable thing we have these days , and this visualization approach really helps to understand that concept , might even try this for myself !
I assume that contextualization and the representation of ambivalence constitute the fourth generation of PKGs. They turn relationships into first‑class citizens.
I have been developing and using a Personal Knowledge Graph since 2008, in the sense of network‑based knowledge modeling and for storing, reusing, extending, communicating, and automating my personal thoughts and conceptual connections. From the very beginning, I did not work with a graph in the conventional sense—an edge connecting two nodes—but with a hypergraph in which a single edge can connect any number of nodes. In addition, I work with three layers of knowledge.
On the first knowledge layer, expectations and rules are defined, similar to RDF and Ontologies with axioms. However, this is done using property‑less classes that are connected to each other via a directed hyperedge. The hyperedge also links a relationship-type that classifies the relationship. The axioms are also connected via the hyperedge. This contextualizes expectations and rules, because they are no longer attached to the classes themselves but to their relationships (first class citicens).
On a second knowledge layer, property‑less objects are connected to each other via a directed hyperedge. Through this edge, the objects are also connected to their classes. The hyperedge also links a relationship type. This contextualizes the classification of the objects. It creates also a connection between the class layer and the object layer, enabling the object relationships to be checked against the axioms. Since the objects can enter into arbitrary additional relationships, the problem found in RDF, OWL, or the Semantic Web in general is resolved: the formal rigidity of the class layer, does not need to be maintained at the object layer, but can be applied by the third layer.
In my concept, there are also context nodes on the third layer, that can be connected to the hyperedges, allowing arbitrarily fine‑grained and evolving contextualization. As a result, logical rigor emerges organically during the work with knowledge and remains limited to the chosen perspective, which drastically reduces complexity.