Hi there, you found a way to get Wiki stuff into Obsidian? Thanks
This seems to apply to the Chromium browser, it does not work for Safari.
I love this clipper but am challenged with adding the {keywords:SEPARATOR} into a list property.
What should the separator be if I want to create a list property in the yaml?
Having thought about this a bit … keywords in the source html are in different formats with different delimiters. So this task might be left to do in Obsidian after the note is imported; if it even has keywords. That is a small price to pay.
Thank you for this extension, it is very useful.
However - after clipping perfectly 10 pages or so, it stops creating pages in Obsidian.
It still sends the markdown to the clipboard, and it opens Obsidian, but no new page is created.
What could be going on?
Chrome on Windows.
All the best,
Tord
Open the Developer Console in Obsidian (Ctrl + Shift + I). I just spent two hours dealing with the same issue. It turns out that the page title had a period at the end and that is not allowed in Obsidian, as the error message indicated.
Hope that helps ![]()
1 Like
Will there be support of {publishedate} in frontmatter in the upcoming update?
thanks
I’m usually able to grab the published date by using {article:published_time} in my template. it was the most common meta tag I came across when hunting for other variables in different sites’ source code.
1 Like
thank you so much, this is really awsome.
Did a little test. this mustache{} seem only work on meta tags not on div class.
yeah, I’m not really sure how you would pull from a div class given that the extension itself looks in the meta tags. I’ve definitely had to manually grab info from source code in some sites that don’t use the metadata tags (but I wish they would! huge fan of semantic web practices), at least until I figure out some easier way!
I don’t know why. But, I don’t see the same “Send text selection to Obsidian” option as you did. Is the Firefox Add-on still working the same way?
This is what I got after clicking on the Add-on button:
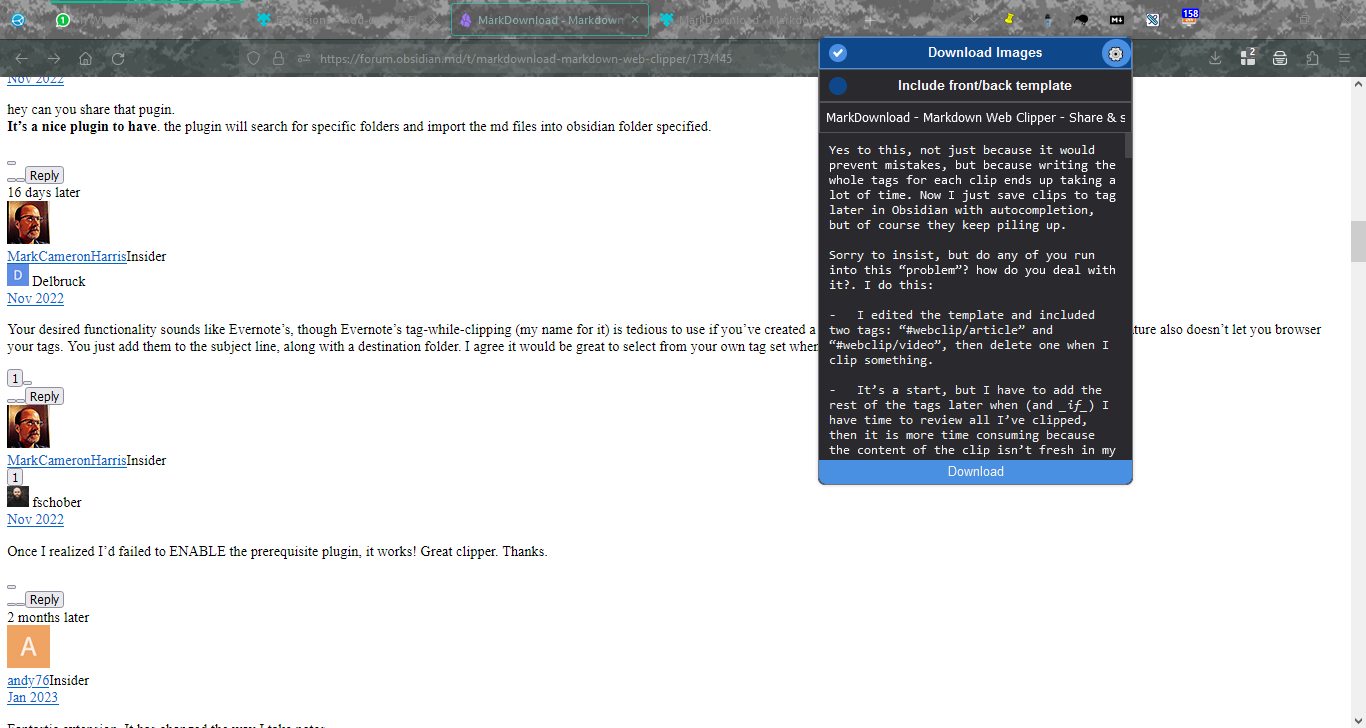
@althair Have a look here:
It’s not in the button at the top of the browser; it’s in the context menu (usually a right-click in the page).
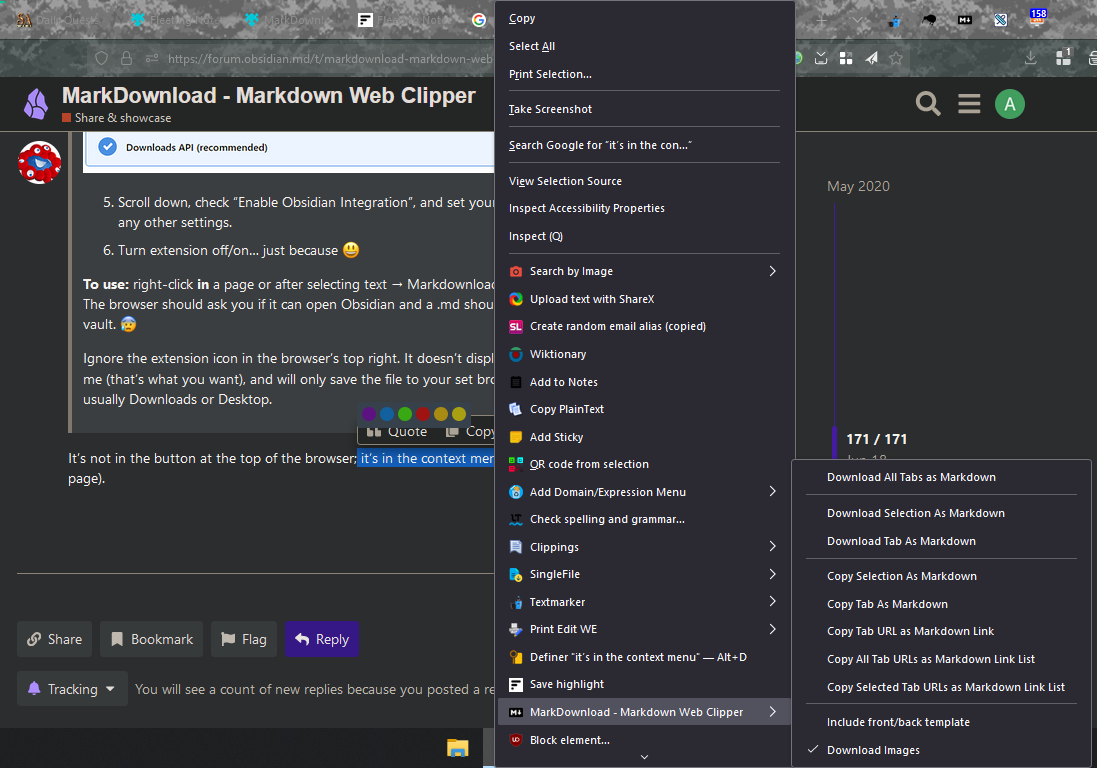
Maybe it’s broken because of Firefox recent update?
Thanks for the help. I’ll look for Vivaldi now.
The main problem for me is that everything works except that the files are downloaded without the .md extension - just the {filename} is used. This makes Obsidian not be able to open the file. I enabled the setting to view ALL files (instead of default just the supported files) in the navigation bar, and then I right click on the file, rename it by adding .md, and the rest works.
Can someone point me to a link where it says how to automatically add set the downloaded filename format as {filename}.md?
I did try to set the format as the filename format in Markdownload, but that didn’t help.
Had to sign up just to comment on this lovely solution! I had issues with several Firefox Obsidian extensions in Linux Mint, including this one and didn’t get how I could simply save the clips in my Obsidian vault, until this solution. Cheers!
1 Like
Me as well. It has replaced Readwise completely. I use MDL most every day and it just does its job, flawlessly.
Cheers MarkDownload !!!
Guys you can use Obsidian official web clipper now!
chrome extension:
web clipper
2 Likes
Regarding meta tags (@AND) and Open Graph formatting (@dryice), I’m happy to share my very chaotic, but mostly working code, evolving over my journey via numerous rounds of trial-and-error.
I’m not super familiar with using them, and I had to learn how to do it between doing my research, so it’s still very much a work in progress – any feedback, suggestions, or improvements are welcome!
So the problem – as death.au mentioned in his release documentation – is that not all websites respond with values for the meta tags listed in the MarkDownload Options. Ok, that’s fine, I thought, I’ll just find a nice list with the tags I need, and collate all of these into one template. Easy, right? Well, that brings us to two problems.
One, formatting them to work, especially if you want to combine them or get parts of them, or using things like {og:type} in your YAML tags.
Two, apparently standardisation is for rascals, so it turns out there are a bajillion different, sometimes very-specific meta tags across the different source types, with many of them relating to the same final YAML property.
This means that depending on the way the website was set up, the tags often either
- (a) return no values despite the website type being similar – so the metadata is labelled differently,
- (b) overlap, resulting in duplicate values if you put various calls there to catch all possible tag options, or
- (c) catch only one instance of the tag (e.g. creators) despite modifications to try and catch all (creator1, creator2).
I’ve tried finding the meta tags that my different reference types use by looking at the website source codes, and then tested them out to see which works most consistently.
Accordingly, this list does not include all tags either, and doesn’t always work.
ISSUES
1 . Title
- can’t seem to get only the first creator’s last name, so just used
{byline}for now as it’s the most reliable - dates for various items work differently, and I only want the year, but can’t seem to get any of the meta tags modifiers to do so
- code:
{citation_publication_date}{article:published_time}{book:release_date}_{byline}_{pageTitle}
2 . Frontmatter
Choosing the correct template for the each data type.
Ideally, I would love for MarkDownload to have an option where I can choose specific templates, or code to do that based on an “if” function, but I’m not good enough with coding / have to finish my research so do not have enough time to fiddle with it to figure that out yet.
In the mean time I’ve made different “sections” in my code for the different source types to add their respective tags to their respective YAML properties, then delete the “sections” that don’t apply.
So it’s a bit annoying, but
- check that all details are captured in the title and appropriate section.
- if some info is lacking / extra info is caught by the other section’s meta tags, then I cut and paste them into the correct section’s YAML properties.
- delete the “section” heading, along with the rest of the unneeded sections (i.e. everything between the
=======parts)
Creators
- sometimes it’s either
{byline}or{creator}or{dc.Creator}, and sometimes the info is in both, causing duplicate values. - it doesn’t catch all of the authors – despite the website code defining authors as e.g.
{creator:1} {creator:2}(can’t remember the exact notation). Sometimes{byline}and{dc.Creator}is different so it catches two of them at least.
Reading status - delete manually, depending how far I’ve read before I saved it to MarkDowloader.
Summary - the idea was to make a linked .md note with my notes and summaries on the document that’s separate from the Markdownloaded one.
I also tried linking it as [[NOTES_{year}_{byline}_{pageTitle}]] or something later before the page text but that’s also been unsuccessful, so for now they are all just [[NOTES]].
Anyways, here’s my code.
====================
# section: JOURNAL ARTICLE
====================
---
year: {dc.Date}
published: {citation_publication_date}
author:
- {dc.Creator}
- {byline}
title: {citation_title}
DOI:
- {publication_doi}
- {doi}
source:
- {baseURI}
- {citation_pdf_url}
journal: {citation_journal_title}
volume: {citation_volume}
issue: {citation_issue}
pages: {citation_firstpage} - {citation_lastpage}
publisher: {citation_publisher}
abstract: {abstract} | {description}
full citation: {bibtex} {article_references}
created: {date:YYYY-MM-DDTHH:mm:ss} (UTC {date:Z})
tags: [{og:type},theory,methods,{keywords}]
date read: {YYYY-MM-DD}
reading_status: UNREAD,READING,READ
summary: NOTE_{citation_publication_date}_{byline}_{citation_title}
description:
---
====================
# source: WEBSITE
====================
---
year: {dc.Date}
published: {article:published_time}
author:
- {byline}
- {dc.Creator}
title: {pageTitle}
URL: {baseURI}
website: {hostname}
webpage: {pageTitle}
abstract: {description}
full citation: {bibtex}
created: {date:YYYY-MM-DDTHH:mm:ss} (UTC {date:Z})
tags: [{og:type},theory,methods,{keywords}]
date read: {YYYY-MM-DD}
reading_status: UNREAD,READING,READ
summary: NOTE_{article:published_time}_{byline}_{title}
description:
---
=================
# source: BOOK
====================
---
year: {dc.Date}
published: {books:release_date}
author:
- {dc.Creator}
- {byline}
title: {title}
ISBN: {books:isbn}
source: {baseURI}
edition: {edition}
pages: {pages}
publisher:
- {publisher}
- {hostname}
abstract: {abstract} | {description}
full citation: {bibtex}
created: {date:YYYY-MM-DDTHH:mm:ss} (UTC {date:Z})
tags: [{og:type},theory,methods,{keywords}]
date read: {YYYY-MM-DD}
reading_status: UNREAD,READING,READ
summary: NOTE_{books:release_date}_{byline}_{title}
description:
---
======================================
##### summary: [[NOTES]]
# {pageTitle}
> ## Excerpt
> {excerpt}
---
Backmatter
# %% header split %%
___
**BELONGS TO**
[[LITERATURE#{og:type}|{og:type}]] | [[MARKDOWNLOAD]] | [[LITERATURE]]
TLDR
In trying to create a nice template that can extract all the metadata properties I need, I realised that
(a) finding a single list of all workable meta tags and Open Graph formattings, and
(b) collating all of them in one neat base template that can cover various sources,
(c) while making them actually work in tandem,
is a bit trickier that I thought.
Hopefully some of my code can help ![]()