That’s such a nicer solution. 
1 Like
Downloading images now fails for me. Does anyone have the same problem?
I’ve made a python script that tags the downloads according to their content, and then moves some of them to a particular Obsidian vault because I have to write something on them every Tuesday morning
1 Like
That sounds awesome! Do share the script when you feel like it.
It will need a bit of cleaning up because my tagging system is rather idiosyncratic, and reflects the subjects I write about, but, yes. I’ll post a version. The central trick, where it tags from keywords, I stole from a clipper for the pinboard.in bookmark manager.
import re,os.path
from datetime import datetime as dt
from datetime import timedelta
from pathlib import Path, PurePath
# TODO possibly replace print statements with logging to a file now that stuff more or less works
# TODO possibly confine operations to metadata
# TODO test the urlcleaner
# TODO (possibly really hard) write and test the byline cleaner
# These need to be adjusted for the mac, which is why they are in this form
Markdowndir="${YOURMARKDOWNDIR}"
ObsidianDir="${YOURCLIPSTOWRITEABOUTVAULT}"
md=Path(Markdowndir)
# obsidiandir is date-dependent, which is why it is not declared at the top of the file — see next function
d=dt.now()
def nextTuesday(d):
'''returns a string, not a date object'''
while d.weekday()!=1:
d += timedelta(1)
return d.isoformat()[:10]
def addMyTags(filename,isPC):
'''returns a list of tagging strings for use in metadata'''
bigstring=filename
foundtaglist=['isTagged']
if isPC:
foundtaglist.append('Press_Column')
triggerwords={
"javascript|js|python|android|github": ['nerd'],
'Pope|Cardinal|Francis|Vatican': ['Press_Column', 'Catholic', 'Schism'],
'Bishop|Archbishop|Church|Vicar|Priest|Christian|Cathedral': ['Press_Column', 'Christianity'],
"Trump": ['Politics', 'USA', 'neofash'],
'Islam"Fatwa|Muslim|mosque': ['Press_Column','Islam', 'religion', 'Race/Immigrants'],
'Online|youtube|twitter|facebook|troll|Google': ['culture_of_online_life','Adtech','security','privacy','journalism'],
'dn.se|expressen|svd.se|ö|ä|å|Sverige|Svenska': ['Sweden', 'Swedish'],
'Akademien|Engdahl|Frostenson|Arnault': ['Akademien','Nobel'],
"github": ['techie'],
'machine learning|GPT-3': ['AI'],
'asylsökande|ensamkommande|migrants': ['Race/Immigrants'],
"transphobic|transphobia|gender": ["terf"]
}
for k,v in triggerwords.items():
if re.search(k,bigstring,re.I):
foundtaglist.extend(v)
return sorted(set(foundtaglist)) # set eliminates duplicates; sorted returns a fresh list
# this is not yet written
def cleanauthorfield():
pass
# this is not yet called
def cleansourceURL(metadata):
messyUrl=re.search("https?\w+",metadata)
return messyUrl.group.split('?',1)
def GetCurrentPressColumndir():
''' returns a Path object representing next Tuesday's subdirectory'''
targetdir=os.path.join(ObsidianDir,nextTuesday(d))
td=Path(targetdir)
# print(td)
if not td.exists():
td.mkdir()
return td
def MoveFileToObsidian(filetomove):
td=GetCurrentPressColumndir()
movedName=td.joinpath(filetomove)
files.rename(movedName)
print("File moved to {}".format(movedName))
def cleanTags(tagstring):
''' takes a string of variously separated tags and returns a comma-separated list of strings'''
taglist=tagstring[1:-1].split(',') # to get rid of the brackets
tagstring=" ".join(taglist) # to get rid of commas
taglist=tagstring.split()
print("Taglist is now {}".format(taglist))
return taglist
def MoveToPressColumn():
pass
mydir=md.iterdir()
for files in mydir:
if files.is_file():
f=open(files,mode='r',encoding='utf8')
bigstring=f.read()
filename=f.name
f.close()
l=bigstring.splitlines()
if "isTagged" in bigstring:
print("{} has been tagged already; ignoring".format(files.name))
continue
try:
metadata=bigstring.split('---')[1] # this is a placeholder for the clean* stubs above to operate on
except IndexError: # there may be no metadata block
continue
isPressClip=False
print("\n\n\nProcessing {}".format(files.name))
for t in l:
if re.match("tags: ",t):
print("Tagging {} ".format(files.name))
tagstring=(t[6:])
taglist= cleanTags(tagstring)
# so taglist is now a comma-separated list of strings, whether or not originally space separated.
# parsing whole file stuff goes here
if "Press_Column" in taglist:
isPressClip=True
mytags=addMyTags(bigstring,True)
else:
mytags=addMyTags(bigstring,False)
if mytags:
if "Press_Column" in mytags:
isPressClip=True #(did the autotagger find a press column subject?)
# print("addMyTags returned: {}".format(mytags))
properlyTaggedString=bigstring.replace(tagstring,', '.join(mytags))# this would be where to add hashmarks for tags
f=open(files,mode='w',encoding='utf8')
f.write(properlyTaggedString)
f.close()
if isPressClip:
MoveFileToObsidian(files.name)
else:
print("Nothing changed in this file by me: original tags were ...")
print(','.join(taglist)) # see notes below
break
if not taglist and not mytags:
print("No tags at all found in {}".format(files.name))
# Clean up the author field in the metadata(factored out into a routine)
# Clean up the source URLs, by deleting everything after the question mark
# clean up the bylines, keeping only the first line — needs to be in a routine of its own
Extremely clunky coding style no doubt. I write so I can still understand it two years (or two weeks) after I have first got it working.
2 Likes
That’s really something I will explore more. Love the topics as well.  Thanks for sharing!
Thanks for sharing!
Love that solution – so elegant! Thanks for bringing this idea here. Great discussion, so many insightful post. 
For some reason a MacOS alias didn’t work for me and Firefox reported a failed download.
That said, a symlinked folder worked just fine. Thanks for the idea.
Every time I download with this plugin it fails to download images. Any idea what this is happening for me?
I usually had failed download when I changed name of linked folder in Obsidian, the alias became broken and it fails
My settings (images aren’t download, I had links to images in notes)
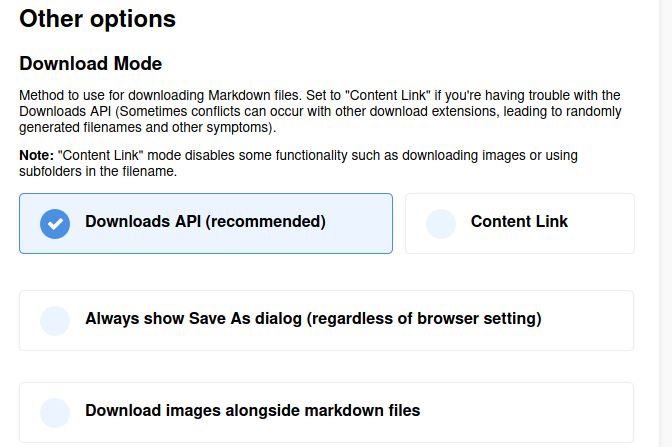
1 Like
I have used this extension a long time ago with no problem. Now It shows downloading the files but all the image downloads fail. I guess it should be a kind of bug.
what do you think folks?
Did you change your download folder/browser settings? I have similar error when the plugin cannot save to chosen location on firefox (what browser do you use?)
Hi everyone,
I am really loving this extension!
It was working perfectly until today.
For some website the images’ url are broken:

An example of webpage having the issue is this page Full Page Reload
I’ll post an issue on Github later.
1 Like
The clipper is working well on Microsoft Edge. Thanks so much for this!
This is a minor quibble but it seems to place all the attachments in my Downloads folder, regardless of where I choose to put the note.
If the browser is set to “ask me where to download each file” then you must manually select where to download the (potentially dozens of) image files. If you have the browser set to automatically download to your downloads folder, but the extension set to select a folder, then the extension will auto-populate the attachments folder into the folder selection window (which is set to Downloads) and place all the images there.
It’s easy enough to move these attachments to the proper place however.
Thank you for this web clipper. I have tried many other ones for Notion, Evernote and others and was utterly disappointed. This is particularly for the Show Notes from a podcast by Dr. Peter Attia (The Drive). Every other web clipper would only download up to the free preview part no matter whether I am logged on to the Members site.
Markdownload worked like a charm.
Many thanks!
– Sai
1 Like
Edit it is working now. Wasn’t before restart.
Wonderful web clipper, and I’ve tried many of them.
One question, though: where can I find a list of all supported meta tags? I am trying to achieve something, but some meta tags that I discovered online weren’t supported, some don’t work as expected.
What I’m trying to achieve here is extract the top level domain of a website so that I can create a folder where I will keep all the images from that website. Something like bbc.co.uk, so all images from BBC will be kept under that same folder automagically.
Is this possible? baseURI extracts the whole url.
I love this extension!
I have one want - tag completion.
I like to to add tags each time I clip a web page. That helps me find those clipped pages later.
I can add tags with this extension, but it’s totally free-form - there’s no connection with my existing obsidian tags. I’d like it to show me a list of my obsidian tags as soon as I type # and then narrow down that list of tags as I continue to type.
In this example below I typed #bookmark but there’s nothing to guide me away from typing #bookmarks. And I’ll end up with many near-duplicate bookmarks that will be a mess.
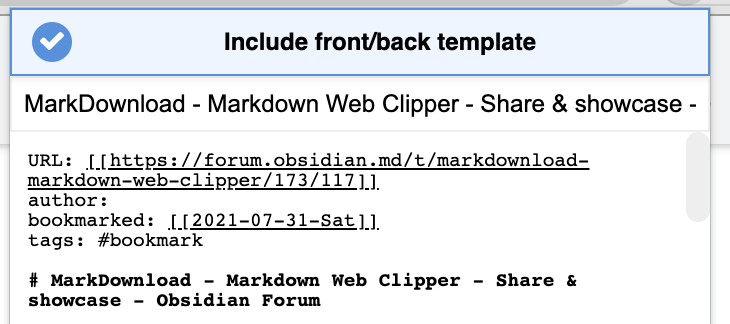
I’m guessing that this would be difficult for a browser extension alone, and some sort of Obsidian plugin would be needed?
Any alternatives or ideas to help me get where I want to go?
2 Likes