I’m trying to sort text and tasks based on the assigned tag or tags, and have them listed in the order they appear in the file beneath the correct heading. I’ve read a bunch of forum posts here, watched a bunch of YouTube videos, and read the Dataview documentation, but I can’t get it to work properly.
Things I have tried
With the help from eightning in my last post I managed to come up with the following search query:
TASK
FROM "name of file"
WHERE contains(tags, "#example-tag")
GROUP BY header
There are two problems with this though:
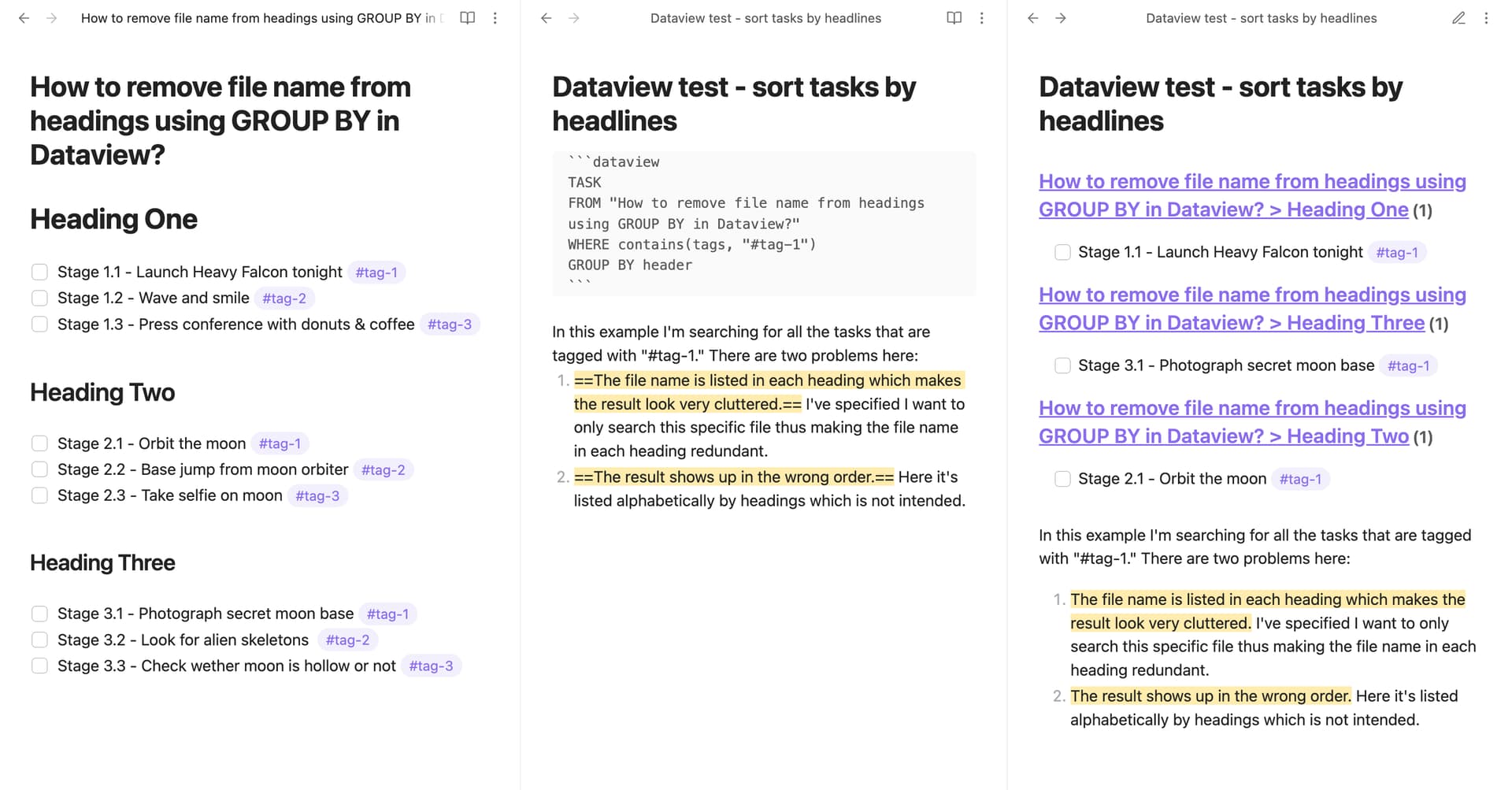
The file name is listed in each heading which makes the result look very cluttered. I’ve specified I want to only search this specific file thus making the file name in each heading redundant.
The result shows up in the wrong order. Here it’s listed alphabetically by headings which is not intended.
Please take a look at the attached image to get a better understanding of what I’m trying to do. Apart from the file name in each heading, you can see that instead of listing the result as:
Heading One
Heading Two
Heading Three
it lists it alphabetically:
Heading One
Heading Three
Heading Two
Any ideas on how to fix this? Any help would be much appreciated!
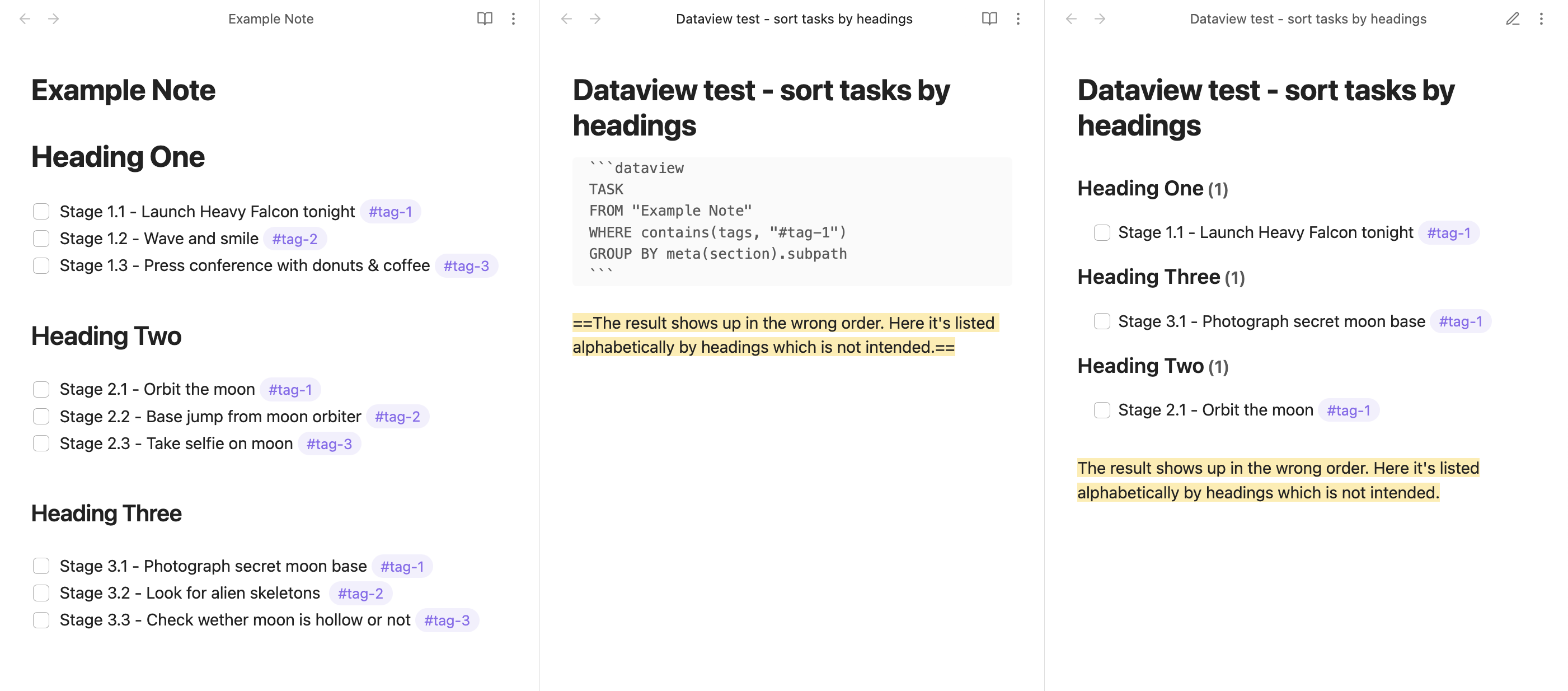
Hi sysbreaker! Thanks for taking the time! The query you suggested is identical to the one I listed apart from using “Group by header” The problem then becomes it doesn’t list the headings at all.
My query:
TASK
FROM "name of file"
WHERE contains(tags, "#example-tag")
GROUP BY header
and your suggestion was:
TASK
FROM "name of file"
WHERE contains(tags, "#tag1")
I wrote “example-tag” in my post but if you look at the image you can see I used “#tag-1.” The problem still remains - without the “Group by header,” it lists the result in one massive list without breaks which can be quite overwhelming in large documents. However, with the “Group by header” it lists by heading which helps, but since it includes the file name in each listed heading it makes the result look very cluttered and difficult to navigate.
Some workarounds would be to:
Begin each header with a number, like “1) Heading One”
Use separate documents for what would otherwise be a separate heading and then list the folder in the “FROM” section.
However, there’s got to be a way to remove the file name from the heading in the results… Any ideas?
If it is listing the headings and putting them in order, the word Heading is the same for all the headings and then ‘One’ comes before ‘Two’ or ‘Three’, and ‘Three’ comes before ‘Two’ when listed alphabetically. Numbering the headings would work.
Don’t know how else to sort headings. Someone else might though.
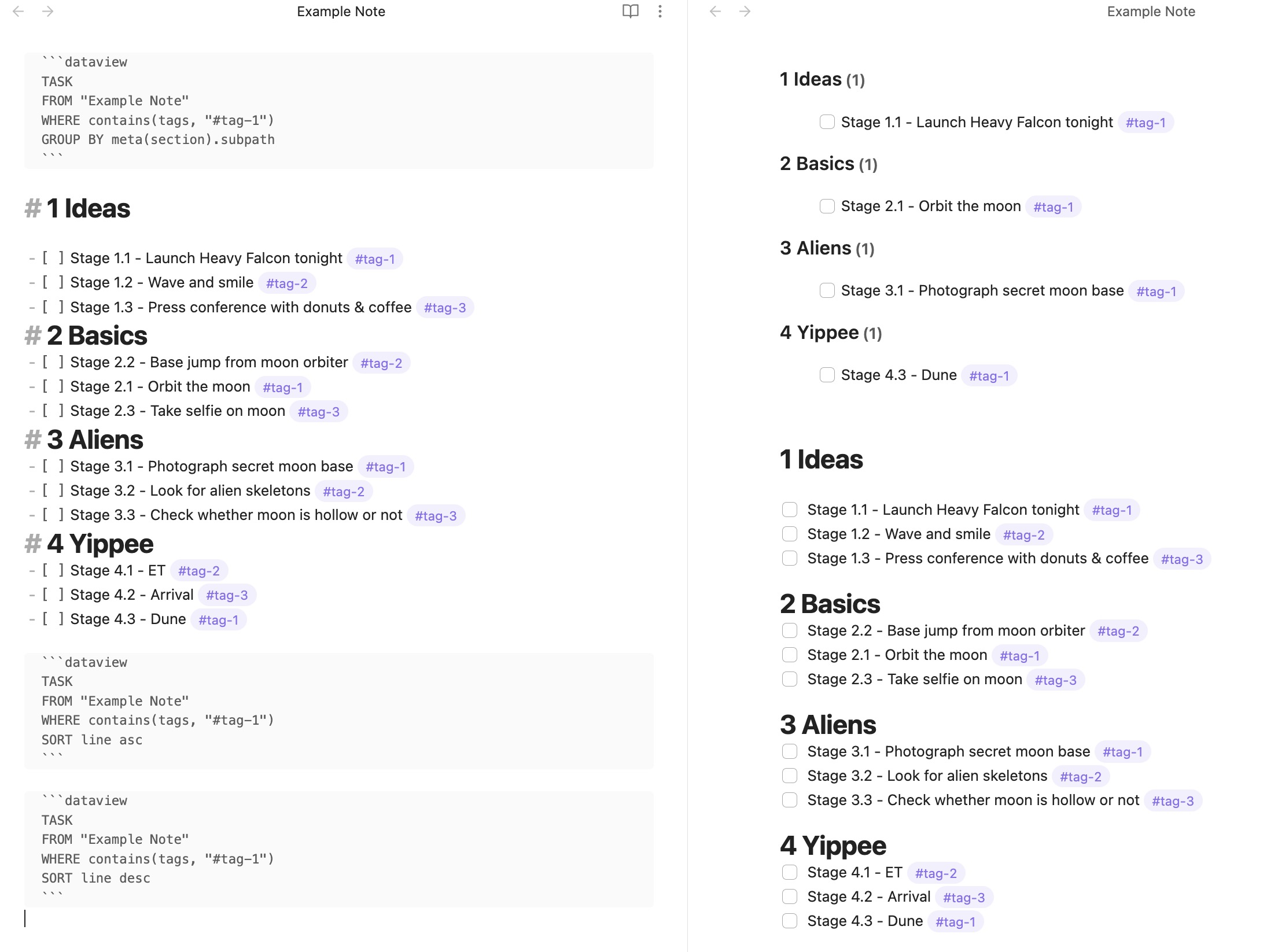
```dataview
TASK
FROM "Example Note"
WHERE contains(tags, "#tag-1")
GROUP BY meta(section).subpath
```
# 1 Ideas
- [ ] Stage 1.1 - Launch Heavy Falcon tonight #tag-1
- [ ] Stage 1.2 - Wave and smile #tag-2
- [ ] Stage 1.3 - Press conference with donuts & coffee #tag-3
# 2 Basics
- [ ] Stage 2.2 - Base jump from moon orbiter #tag-2
- [ ] Stage 2.1 - Orbit the moon #tag-1
- [ ] Stage 2.3 - Take selfie on moon #tag-3
# 3 Aliens
- [ ] Stage 3.1 - Photograph secret moon base #tag-1
- [ ] Stage 3.2 - Look for alien skeletons #tag-2
- [ ] Stage 3.3 - Check whether moon is hollow or not #tag-3
# 4 Yippee
- [ ] Stage 4.1 - ET #tag-2
- [ ] Stage 4.2 - Arrival #tag-3
- [ ] Stage 4.3 - Dune #tag-1
```dataview
TASK
FROM "Example Note"
WHERE contains(tags, "#tag-1")
SORT line asc
```
```dataview
TASK
FROM "Example Note"
WHERE contains(tags, "#tag-1")
SORT line desc
```
I don’t really know a proper solution, but I wanted to chime in with some thoughts. Part of the reason this is happening is that the GROUP BY needs to sort before grouping (it seems), so I’m wondering whether at whimsical SORT file.name (or another value which is identical for all values) would “restore” the original line ordering.
Another thought would be to access the line number of the heading, but I’m not sure that’s readily available. I know it’s available for the list/task items, but don’t think it’s exposed for headings.
A final thought would be to try adding the numbering in comments, so it won’t visually show but it’s included when sorting.
Morning @Albus
sadly … still no luck on sorting if using TASK … but, if you are able to accept less readable solution (with TABLE), this is i came up with:
TABLE WITHOUT ID
T.section as Heading,
T.text as Text
FROM "Example Note"
FLATTEN file.tasks as T
WHERE contains(T.text, "#tag-1")
this will give me output like this (i know its ugly):
The thing is that this isn’t sorted at all, since it doesn’t do the grouping. As such this’ll present the task in the default order. The same applies to the task query without the grouping.
So actually there is one solution where one could take the original query (without the grouping), and run that from within dataviewjs, and then let the javascript insert headers whenever they change for any given task. This should produce the wanted output, but it does require a little bit of coding.
This is the listed solution in that thread provided by user ces3001:
const summary = true
const includeSection = true
let taskList = dv.current().file.tasks
.where(t => !t.completed && dv.date(t.start) <= dv.date('today'))
taskList = taskList
.sort(t => t.line)
.sort(t => t.path)
if (summary) { dv.span("*" + taskList.length + " tasks*\n") }
if (includeSection) {
const regex = /> ([^\]]+)/;
let section = null
let page = null
let sectionTaskList = []
for (let t of taskList) {
if ((sectionTaskList.length > 0) &&
((page != t.path) || (section != t.section.toString()))) {
dv.taskList(sectionTaskList,false)
}
if (page != t.path) {
dv.header(2,t.path.replace(/\.md$/, ''))
page = t.path
}
if (section != t.section.toString()) {
section = t.section.toString()
dv.header(3, section.match(regex)[1])
sectionTaskList = []
}
sectionTaskList = sectionTaskList.concat(t)
}
dv.taskList(sectionTaskList,false)
} else {
dv.taskList(taskList,true) // true = divide by file
}
Now, I don’t know anything about JavaScript, this is a bunch of gibberish to me. However, if anyone here knows about javascript and how to use dataviewjs, is it possible we could use this as a template and get it working in my use case?