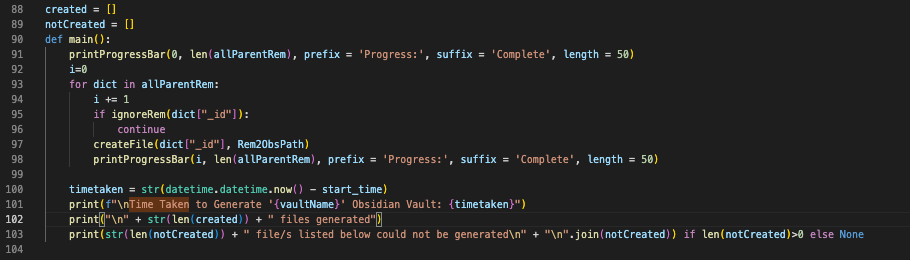
@steinar actually, the issue with the previous one was because I downloaded the wrong file. Now I do have the right file, but I still have this issue:
(The code above shows the file path, so I’ve covered it)
I don’t think the code ran successfully, but I’m not sure why. The code is:
# terminal code: "cd Remnote2Obsidian && python Remnote2Obsidian.py"
# print("Python execution started")
import sys, os, json, datetime, re
# Import modules from current project:
from progressBar import printProgressBar
# Custom Package installation
from dateutil.parser import parse as dateParse
start_time = datetime.datetime.now()
dir_path = os.path.dirname(os.path.realpath(__file__))
# user-input variables: ----------------------------------------
jsonFile = "../Data/rem.json"
# jsonPath = sys.argv[1]
RemLanguages = "../Data/RemLanguages.json"
langJsonPath = os.path.join(dir_path, RemLanguages)
vaultName = "Rem2Obs"
dailyDocsFolder = "Daily Documents"
indent = "\t" # " " # choose how are lines indented (tab ("\t") vs 4spaces(" ")) --> https://forum.obsidian.md/t/meta-post-common-css-hacks/1978/509?u=gangula
highlightToHTML = True # if False: Highlights will be '==sampleText==', if True '<mark style=" background-color: {color}; ">{text}</mark>'
previewBlockRef = True
delimiterSR = " -- " # Spaced Repetition Delimiter
re_HTML = re.compile("(?<!`)<(?!\s|-).+?>(?!`)")
re_newLine = re.compile("(\\n){3,}") # replace more than 2 newlines with only 2: https://regex101.com/r/9VAqaO/1/
re_remID = re.compile(r'\[\[')
# ---------------------------------------------------------------
pbr=""
if previewBlockRef:
pbr = "!"
jsonPath = os.path.join(dir_path, jsonFile)
if not os.path.isfile(jsonPath):
sys.exit("JSON file not found")
Rem2ObsPath = os.path.join(dir_path, vaultName)
os.makedirs(Rem2ObsPath, exist_ok=True)
remnoteJSON = json.load(open(jsonPath, mode="rt", encoding="utf-8", errors="ignore"))
RemnoteDocs = remnoteJSON["docs"]
ignoreKey = ["Remnote Default"]
ignoreID = ["9onq37x6PbsFxvRqu", "6sz2MJeFLZoTRQofZ"]
allParentRem = []
# allFolders = []
# topFolders = []
for x in RemnoteDocs:
if(x.get("n", False) == 1 and
x.get("_id", False) not in ignoreID and
x["key"] != [] and
x["key"][0] not in ignoreKey):
allParentRem.append(x)
if(x.get("rcrt", False) == "d"):
# Convert Daily Documents to folder
x["key"][0] = dailyDocsFolder
x["forceIsFolder"] = True
# if "forceIsFolder" in x and x["forceIsFolder"]:
# allFolders.append(x)
# if x["parent"] == None:
# topFolders.append(x)
def getAllDocs(RemList):
IDlist = []
for rem in RemList:
if rem.get("forceIsFolder", False):
childRem = []
for child in rem["children"]:
dict = [x for x in RemnoteDocs if x["_id"] == child][0]
childRem.append(dict)
IDlist.extend(getAllDocs(childRem))
if(len(rem["children"])>0
or (len(rem.get("portalsIn", []))>0)
or (len(rem.get("references", []))>0)
or (len(rem.get("typeChildren", []))>0)):
IDlist.append(rem["_id"])
else:
# print("REM not used anywhere")
pass
return IDlist
allDocID = getAllDocs(allParentRem)
allDocID = list(set(allDocID) - set(ignoreID))
# allDocID is used in textFromID function
created = []
notCreated = []
def main():
printProgressBar(0, len(allParentRem), prefix = 'Progress:', suffix = 'Complete', length = 50)
i=0
for dict in allParentRem:
i += 1
if ignoreRem(dict["_id"]):
continue
createFile(dict["_id"], Rem2ObsPath)
printProgressBar(i, len(allParentRem), prefix = 'Progress:', suffix = 'Complete', length = 50)
timetaken = str(datetime.datetime.now() - start_time)
print(f"\nTime Taken to Generate '{vaultName}' Obsidian Vault: {timetaken}")
print("\n" + str(len(created)) + " files generated")
print(str(len(notCreated)) + " file/s listed below could not be generated\n" + "\n".join(notCreated)) if len(notCreated)>0 else None
def createFile(remID, remFolderPath):
# this is recursive function, so cannot be moved directly to main() function
if ignoreRem(remID):
return
remText = textFromID(remID)
remDict = dictFromID(remID)
textSplit = remText.split(delimiterSR)
filename = textSplit[0]
filename = replaceRemID(filename)
fileDesc = ""
if len(textSplit)>1:
fileDesc = "\nFile Description: " + textSplit[1]
if remDict.get("forceIsFolder", False):
newFilePath = os.path.join(remFolderPath, filename)
for child in remDict["children"]:
createFile(child, newFilePath)
else:
os.makedirs(remFolderPath, exist_ok=True)
fileTitle = filename
# filename = re.sub('[^\w\-_\. ]', '_', filename)
if(os.path.basename(remFolderPath) == dailyDocsFolder):
# dailyDocName = datetime.datetime.strptime(filename, "%B %dth, %Y").date()
try:
dailyDocName = dateParse(filename)
filename = dailyDocName.strftime("%Y-%m-%d")
except:
pass
# fileTitle += " (" + filename + ")"
filePath = os.path.join(remFolderPath, filename + ".md")
try:
with open(filePath, mode="wt", encoding="utf-8") as f:
child = expandChildren(remID)
fileMetadata = f'# '
expandBullets = "\n".join(child)
f.write(fileMetadata + fileTitle + fileDesc + "\n\n" + expandBullets)
# print(f'{filename}.md created')
created.append("ID: " + remID + ", Name: " + filename)
except Exception as e:
# print(e)
notCreated.append("ID: " + remID + ", Name: " + filename)
# print("\ncannot create file with ID: " + remID + ", Name: "+ filename + "\n")
def ignoreRem(ID):
# TODO: add more ignore ID's
dict = dictFromID(ID)
if(dict == []
or dict["key"] == []
or ("contains:" in dict["key"])
or ("rcrp" in dict)
or ("rcrs" in dict)
or ("rcrt" in dict and dict.get("rcrt") != "c" and dict.get("rcrt") != "d")
or (dict.get("type", False) == 6)):
return True
else:
return False
def expandChildren(ID, level=0):
childIDList = [x["children"] for x in RemnoteDocs if x["_id"] == ID][0]
filteredChildren = []
text = ""
childData = [x for x in RemnoteDocs if x["_id"] in childIDList]
for x in childData:
childID = x["_id"]
if not ignoreRem(childID):
text = textFromID(childID)
prefix = ""
if level >= 1:
prefix = indent * level
prefix += "- "
blankPrefix = prefix.replace("- ", indent)
# if text.startswith("```"): # not necessary - this is removing bullet in first line of code-block
# prefix = blankPrefix
text = prefix + text
if "references" in x and x["references"] != []:
text += f' ^{childID.replace("_", "-")}'
if "\n" in text:
text = text.replace("\r", "\n")
text = re.sub(re_newLine, r"\n\n", text)
text = text.replace("\n", "\n" + blankPrefix)
filteredChildren.append(text)
filteredChildren.extend(expandChildren(childID, level = level + 1 ))
return filteredChildren
def dictFromID(ID):
dict=[]
try:
dict = [x for x in RemnoteDocs if x["_id"] == ID][0]
except Exception as e:
# print(e)
# print(f"REM with ID: '{ID}' not found")
pass
return dict
def textFromID(ID, level = 0):
text = ""
if ignoreRem(ID):
return text
dict = dictFromID(ID)
key = dict["key"]
todoStatus = getTODO(dict)
if todoStatus == "Finished":
text += "[x] "
elif todoStatus == "Unfinished":
text += "[ ] "
text += arrayToText(key, ID)
# value = dict.get("value", [])
# if value and len(value) > 0:
# text += delimiterSR + arrayToText(value, ID)
if level == 0:
# level is used to disable recursive expansion, since tags don't need to be recursive
if ((len(dict.get("typeParents", []))>0)
and not ID in allDocID
and not(dict.get("forceIsFolder", False))):
text += convertTags(dict)
if text.startswith("```"):
text = text.replace("\r\n", "\n")
# in Windows - "\r\n" means end of line - https://stackoverflow.com/a/1761086/6908282
return text
def arrayToText(array, ID):
text = ""
for item in array:
if(isinstance(item, str)):
text += fence_HTMLtags(item)
elif(item["i"] == "q" and "_id" in item):
newDict = dictFromID(item["_id"])
if newDict == []:
continue
newID = newDict["_id"]
parentPath = parentFromID(newID)
if newID in allDocID:
text += f'[[{parentPath}]]'
else:
text += f'{pbr}[[{parentPath}#^{newID}]]'
elif(item["i"] == "o"):
text += f'```{getOrgLanguage(item.get("language", "None"))}\n{item["text"]}\n```'
elif(item["i"] == "i" and "url" in item):
text += f''
elif(item["i"] == "m"):
currText = item["text"]
currText = fence_HTMLtags(currText)
if ("url" in item):
text += f'[{currText.strip()}]({item["url"]})'
elif (currText.strip() == ""):
text += currText
elif(item.get("q", False)):
text += f'`{currText}`'
elif(item.get("x", False)):
text += f'$${currText}$$'
elif(item.get("b", False)):
if(item.get("h", False)):
text += textHighlight(currText, item["h"], html = highlightToHTML)
else:
text += f'**{currText}**'
elif(item.get("h", False)):
text += textHighlight(currText, item["h"], html = highlightToHTML)
elif(item.get("u", False)):
text += currText
elif(item["i"] == "q" and "textOfDeletedRem" in item):
text += "#DeletedRem: " + "".join(item["textOfDeletedRem"])
else:
print("Could not Extract text at textFromID function for ID: " + ID)
return text
def replaceRemID(text):
text = re.sub(re_remID, ' #', text)
text = text.replace("]]", "")
text = text.replace("/", "") # replace "/" if added in parentFromID() function
text = text.strip()
return text
def convertTags(dict):
text = ""
for x in dict["typeParents"]:
if not ignoreRem(x):
textExtract = textFromID(x, level = 1).strip()
textExtract = re.sub(r'[^A-Za-z0-9-]+', '_', textExtract)
text += f' #{textExtract}'
return text
def textHighlight(text, colorNum, html = False):
if html:
# Switch-Case: https://stackoverflow.com/a/60211/6908282
def switch(x):
colorList = {
1 : "firebrick",
2 : "darkorange",
3 : "goldenrod",
4 : "seagreen",
5 : "rebeccapurple",
6 : "steelblue",
}
color = colorList.get(x, "")
return color
color = switch(colorNum)
text = f'<mark style=" background-color: {color}; ">{text}</mark>'
else:
text = f'=={text}=='
return text
def getTODO(keyDict):
if isinstance(keyDict["key"][0], dict) and keyDict["key"][0].get("i") == "o":
# Excludue "Custom CSS" Rem - Dont add Todo check-boxes from here
# Typically, CSS code-block has only one item in the key dictionary and all code-block have property `"i": "o"`
return False
todo = keyDict.get("crt")
if todo and "t" in todo:
todoStatus = todo["t"]["s"]["s"]
return todoStatus
else:
return False
def fence_HTMLtags(string):
# Reference: https://regex101.com/r/BVWwGK/10
if not string.startswith("```"):
# \g<0> stands for whole match - so we're adding backtick (`) as suffix and prefix for whole match
# reference: https://docs.python.org/3/library/re.html#re.sub
# \g<0> instead of \0 - reference: https://stackoverflow.com/q/58134893/6908282
string = re.sub(re_HTML, r"`\g<0>`", string)
return string
def parentFromID(ID):
fileName = ""
if ignoreRem(ID):
return fileName
dict = dictFromID(ID)
if(ID in allDocID):
filePath = getFilePath(ID)
filePath.reverse()
fileName = "/".join(filePath) + "/" + textFromID(ID)
else:
fileName = parentFromID(dict["parent"])
return fileName
def getFilePath(ID):
pathList = []
dict = dictFromID(ID)
if dict != [] and dict.get("parent", None) != None:
pathList.append(textFromID(dict["parent"]))
pathList.extend(getFilePath(dict["parent"]))
return pathList
def getOrgLanguage(lang):
lang = lang.lower()
langList = json.load(open(langJsonPath, mode="rt", encoding="utf-8", errors="ignore"))
try:
identifier = langList[lang]
except Exception as e:
identifier = langList[lang]
print(e)
print("cannot find org-language(syntax-highlight) for: " + lang)
return identifier
if __name__ == '__main__':
main()```