Things I have tried
every code variation I could think of
What I’m trying to do
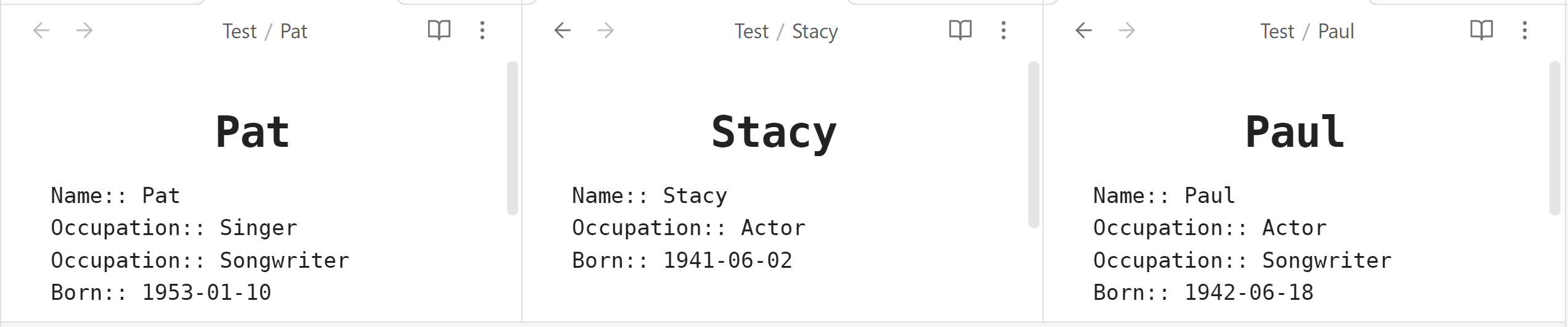
I have a very long list of people notes and a dataview table lists them alphabetically, which is great. But it would be nice to group them by occupation and then alphabetically under that. Not sure why it’s not working but here are some of the parameters of my people notes:
- There is no “Name” in YAML because the note name is the name. If necessary I could add a “Name” field to all my notes but it seems redundant. Maybe there are more reasons to go back and add this. I would like to list the file name (or if not possible, the “Name” field) and use that as the link to that person’s note. I tried both with and w/o a Name field in YAML. Tried w/ and w/o ID.
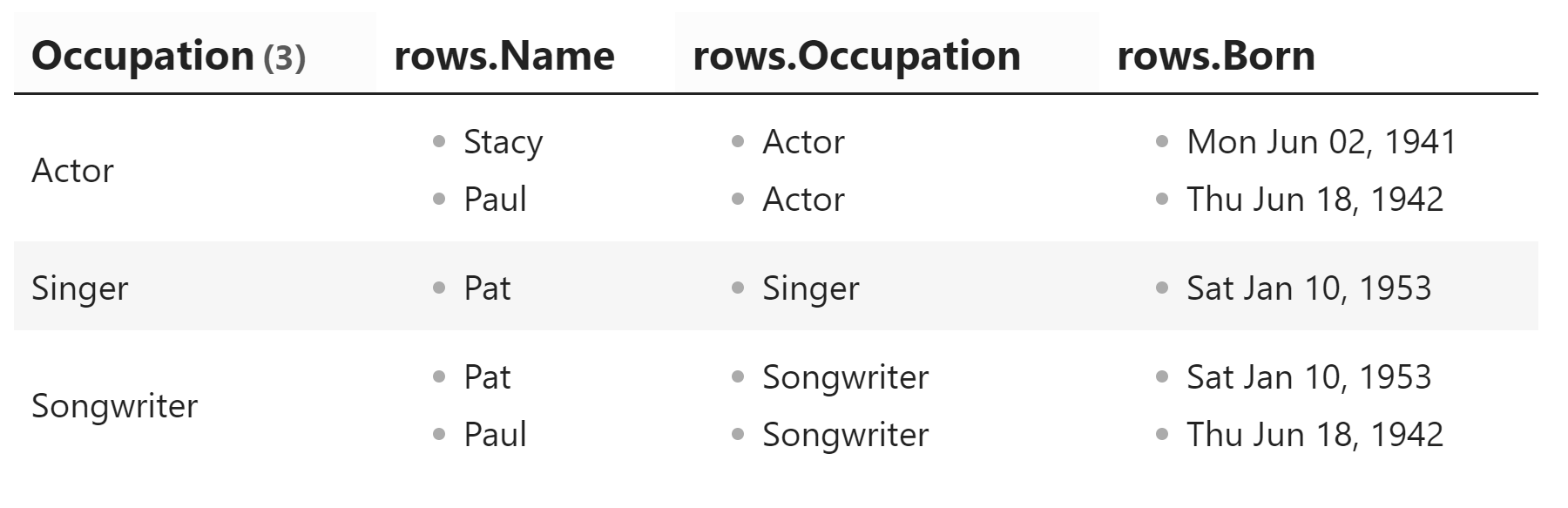
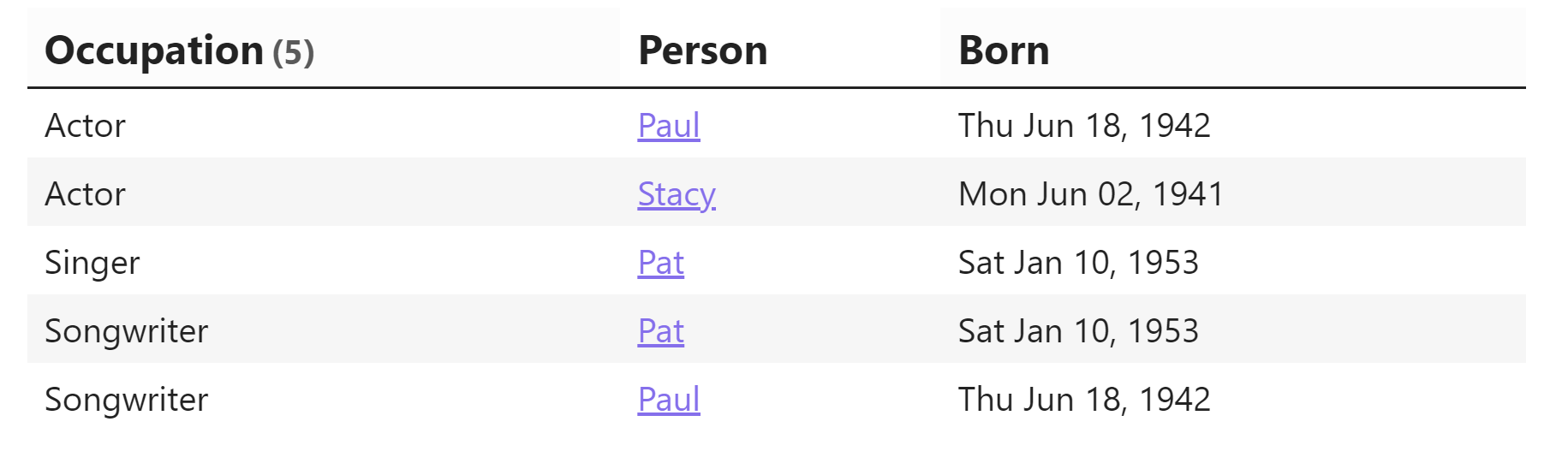
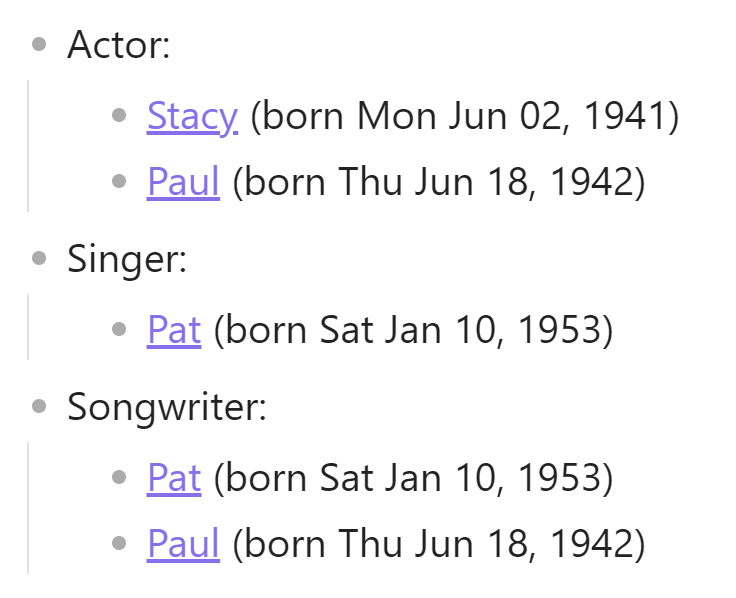
- What happens if someone has more than one occupation? E.g. Someone is a doctor and an author, etc? How does the grouping work and can that person be repeated in each group? In my case, however, the notes that have multiple Occupations in YAML dont show up as individual Occupations, but rather a long occupation with commas.
This is my current version of the code:
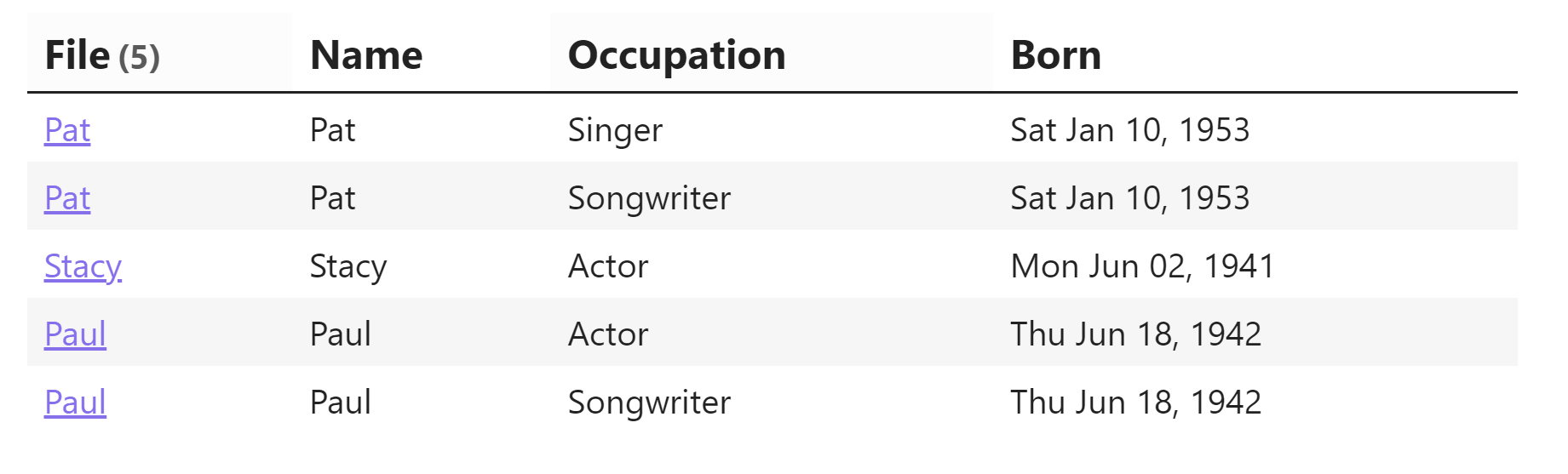
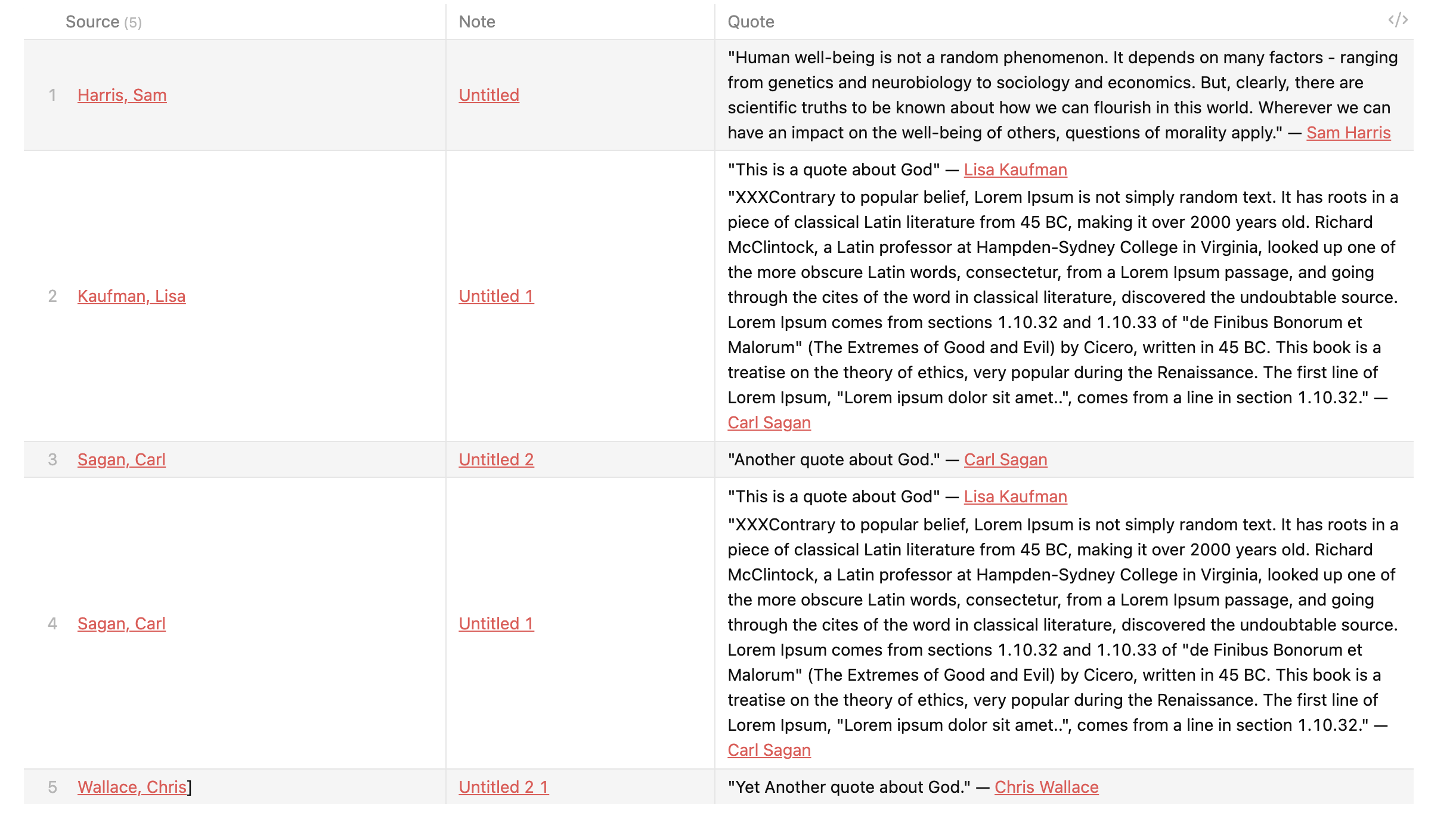
TABLE Name, Occupation, Employment, Born, Death, Birthplace, Note
FROM #note/type/person AND -"Templates"
GROUP by Occupation
SORT Name ASC
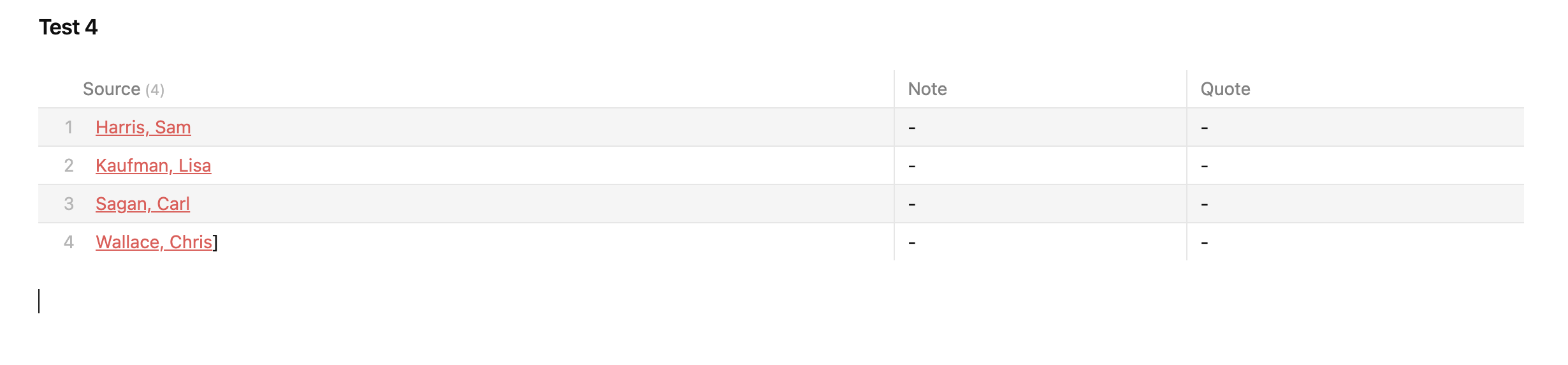
This is what my result looks like (occupation is in there 2x, there’s a blank line at the top, and there are no results in any of the other columns.

Thanks!