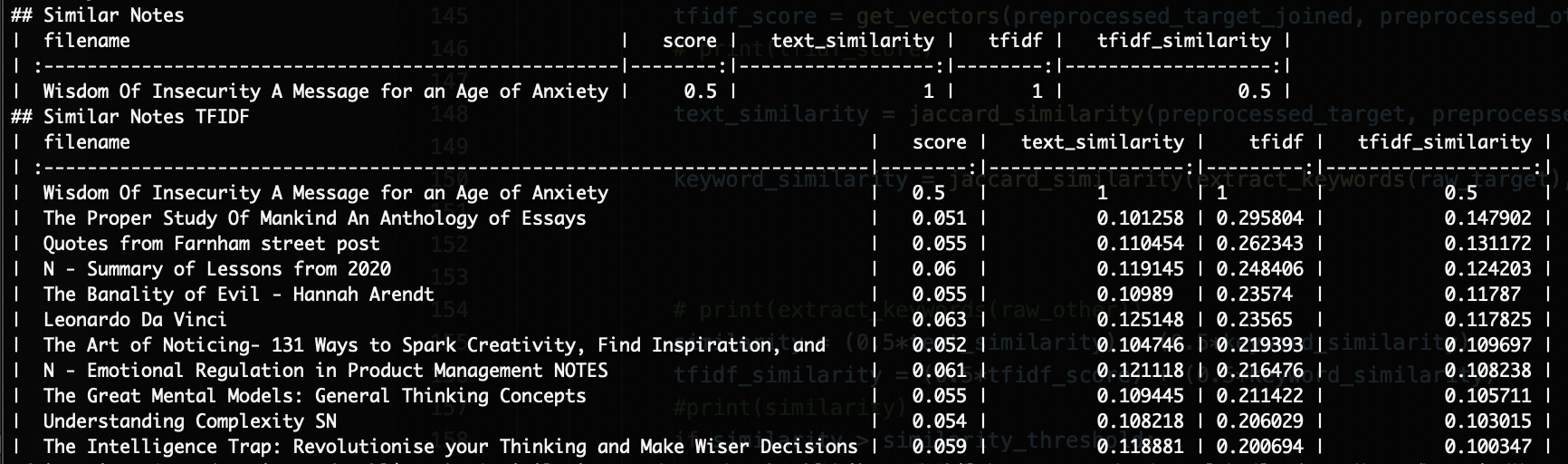
My first attempt used a Jaccard index algorithm. It was pretty basic, but didn’t need any external libraries.
When I included the feature in Obsidian Utilities, I refactored it to use TF-IDF, but then NLTK and Gensim became necessary. The packaging was a nightmare and the workflow went from a few hundred KB to more than 300 MB.
Finally, I refactored it again, this time to use the core SQLite package and do away with the dependencies.
Honestly, I didn’t notice any significant improvements from Jaccard to TF-IDF, but that may have something to do with the nature of my notes. Very disparate subjects, two languages, etc.
I think there’s a lot of room for improvement:
1. Better performance
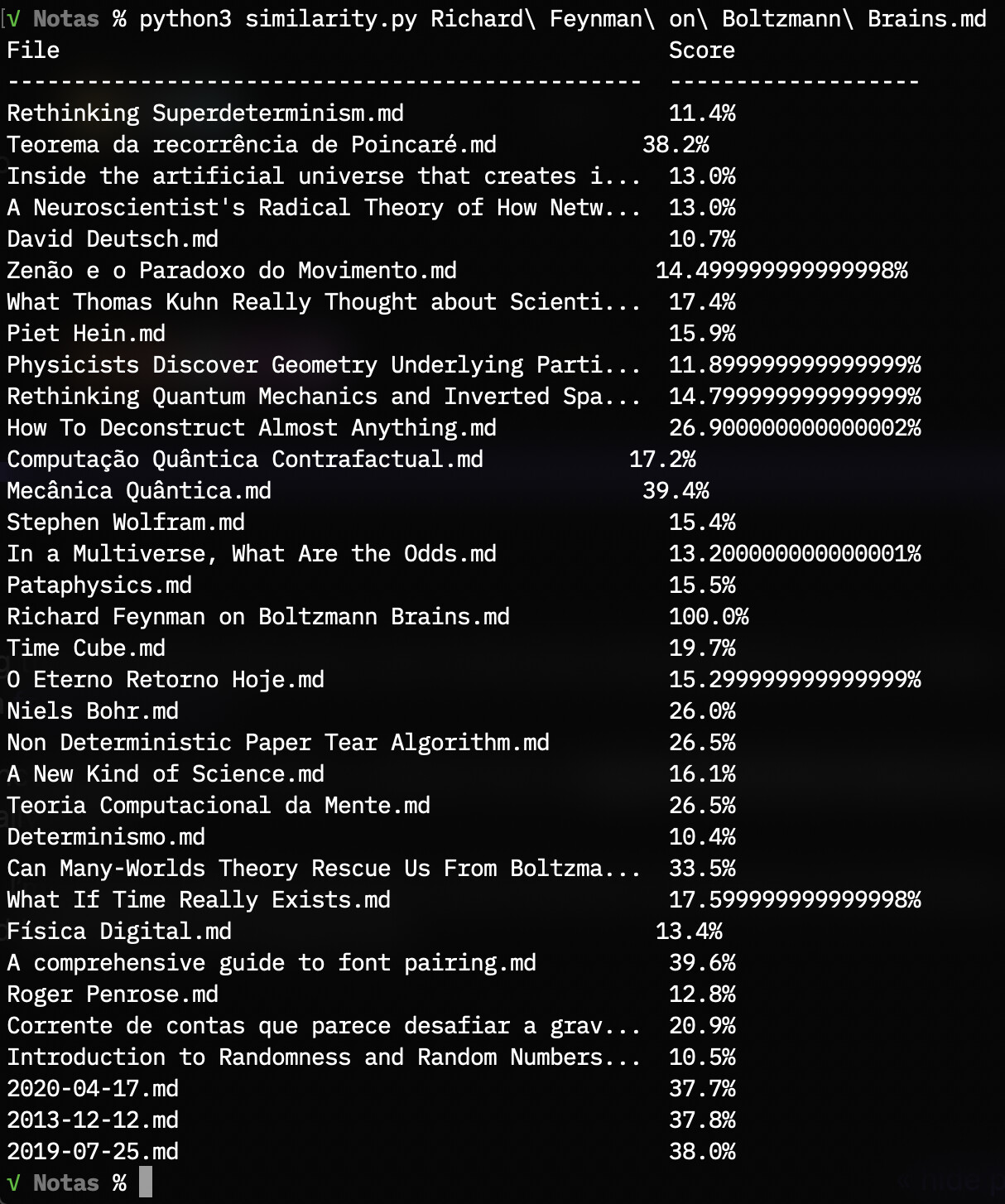
My vault has around 3k notes and the workflow takes around 15 seconds to run. All the notes are being processed at runtime and I had to refrain on the preprocessing in order not to make it even worse. I’d like to be able to lemmatize and remove stop words without degrading performance, and I guess that proper caching would do the trick. By proper, I mean a persistent cache with all the lemmatized words and their counts, all the notes neatly vectorized, and regular cache updates.
2. Better preprocessing
Like I said above, the current preprocessing is pretty basic and I believe it degrades the relevance of the matches. I’d like to remove numbers, punctuation, stop words, and then lemmatize the whole thing. Multiple language support would be a plus.
3. Different weights for title and keywords
There was actually a regression from my first standalone python script to the workflow versions: initially, it gave more weight to tags and wikilinks, which I believe makes sense, since they mean an intentional, active relationship between notes. Including titles in this logic might also work.
4. Turning it into a proper plugin
Alfred is great, but not everyone uses it. If an Obsidian plugin was available, that would mean better integration, probably better performance, and a much better UX. Just imagine a “Similar Notes” pane automatically populating like the Backlinks. I don’t know a thing about Typescript, so I’m not the one making that happen.

 )
)

 .
.