I have created notes on various book that I have read with each note containing the following front matter:
Created: <% tp.file.creation_date(“dddd Do MMMM YYYY HH:mm:ss”) %>
Author:
Type: BookNote
Book_Title:
Tags:
Each note has a section where I have typed quotes from the book in the simple format:
“This is a quote” (Pg.1)
“This is a mother quote” (Pg.2)
I would now like to create a data view query on another note that will query all the book notes and return only quotes from a specific author. I would like the query to display the author, quote, book and page number of each quote in a table.
So far I can pull in the author and book but how can I pull in the quotes from the note. My query so far:
TABLE Author, Book_Title as "Book Title"
where author = “insert_name_of_author”
Dataview is not designed to pull out chunks of text from your file; Obsidian’s core Search plugin is a better fit for that. You can embed a search query just like a dataview. I do not know the exact syntax but if you search for line("Author: insert_name_of_author") that should get you the correct list of files.
Pinging @CawlinTeffid or one of the other forum residents with embedded search expertise!
Hi @cheesycrips ! Did you manage to do what you wanted? I’m trying to do something very similar. In my case, I have a tag I use to identify every question my professor makes in class and I type it right after the question, in the same line. I’d like to know if it’s possible to query only these lines of text in a separate document. I also have them numbered in the beginning, so I think it could be sorted.
---
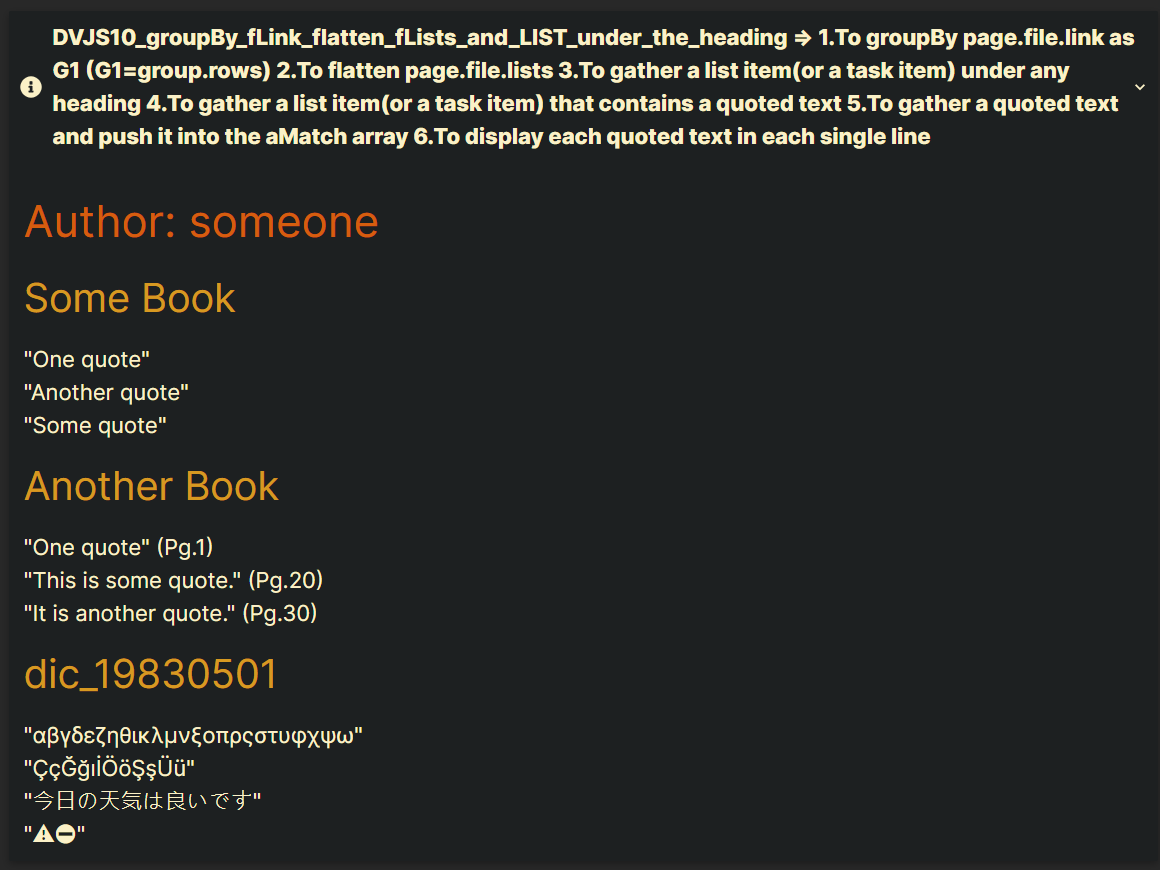
Date: 1983-03-01
Author: someone
Type: BookNote
Book_Title: Some Book
Tags:
---
### input_data
#### a
- a1 "One quote" test
- a2
#### b
- b1
- b2 "Another quote" test "Some quote" test
#### c
- [x] c1
- [ ] c2
#### d
- [ ] d1
- [x] d2
#### e
- [!] e1
- [ ] e2
#### f
folder: 04
filename : dic_19830401
---
Date: 1983-04-01
Author: someone
Type: BookNote
Book_Title: Another Book
Tags:
---
### input_data
#### a
- a1
- a2
#### b
- b1
- b2
#### c
- [>] c1
- [ ] c2 "One quote" (Pg.1) test
#### d
- [x] d1
- [ ] d2 "This is some quote." (Pg.20) test "It is another quote." (Pg.30) test
#### e
- [ ] e1
- [x] e2
#### f
folder: 05_Unicode
filename : dic_19830501
---
Date: 1984-05-01
Author: someone
Type: BookNote
Book_Title:
Tags:
---
### input_data
#### a
- a1 Greek Alphabet "αβγδεζηθικλμνξοπρςστυφχψω" test
- a2
#### b
- b1
- b2 Turkish characters "ÇçĞğıİÖöŞşÜü" test
#### c
- [ ] c1 Japanese hiragana Alphabet "今日の天気は良いです" CJK Unified Ideographs
- [ ] c2 Warning Sign Emoji "⚠⛔" No Entry Emoji
#### d
- [ ] d1
- [ ] d2
#### e
- [ ] e1
- [ ] e2
#### f
folder: 08_excluding_case
filename : dic_19830801
---
Date: 1983-08-01
Author: somebody
Type: BookNote
Book_Title: One Book
Tags:
---
### input_data
#### a
- a1 "One quote" test
- a2
#### b
- b1
- b2 "Another quote" test "Some quote" test
#### c
- [x] c1
- [ ] c2
#### d
- [ ] d1
- [x] d2
#### e
- [!] e1
- [ ] e2
#### f
1.To groupBy page.file.link as G1 (G1=group.rows) 2.To flatten page.file.lists 3.To gather a list item(or a task item) under any heading 4.To gather a list item(or a task item) that contains a quoted text 5.To gather a quoted text and push it into the aMatch array 6.To display each quoted text in each single line
The DVJS10 is based on the DVJS10 in the following topic. - Solutions: by Justdoitcc
Notes
Summary
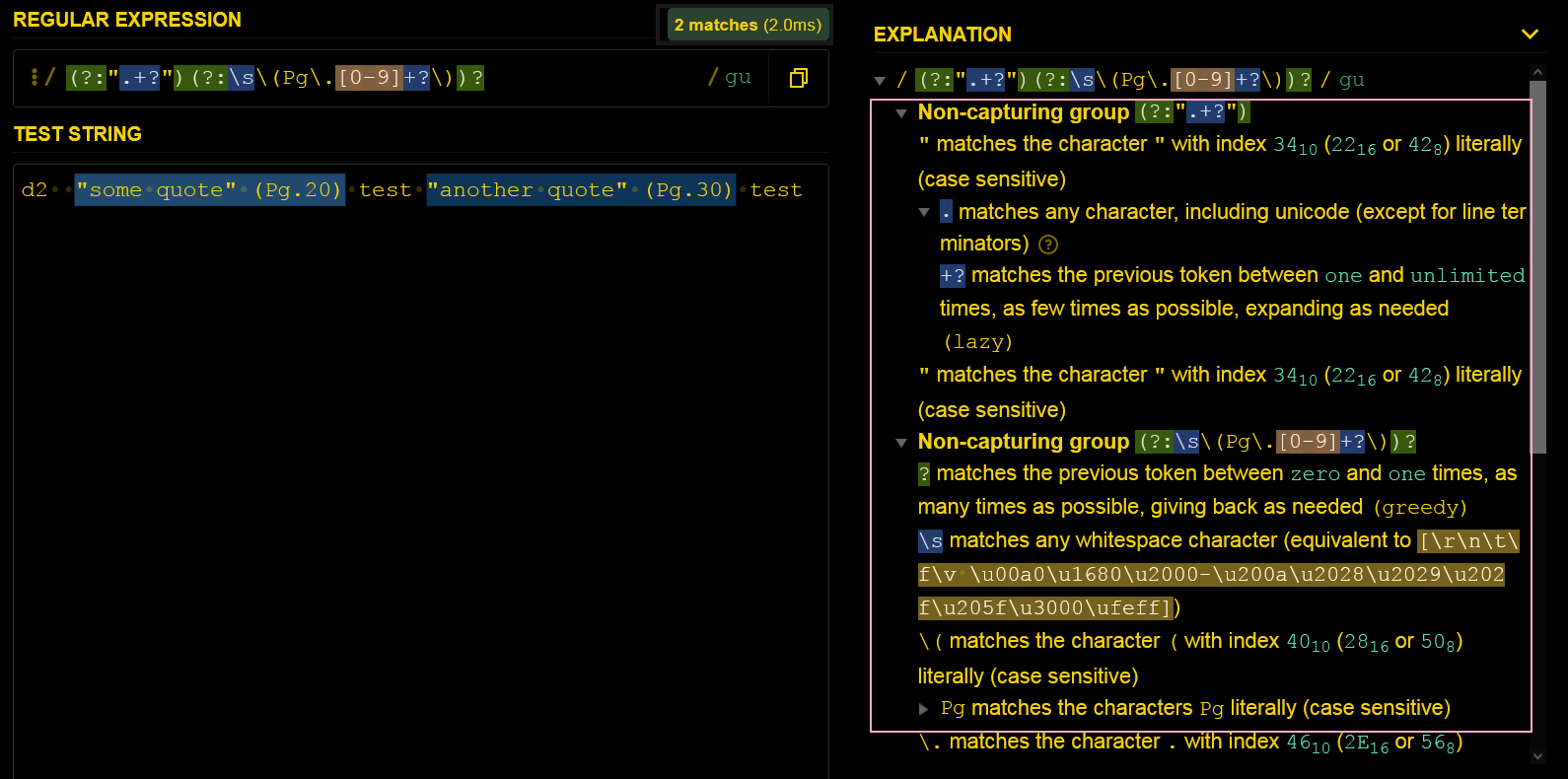
Q1: What does the following Regular Expression mean?(M31.FR10)
Summary_Q1
```JS
// M31.FR10 define REGEX_QUOTED_TEXT:
// The pattern matches quoted texts like `"One quote"` or `"One quote" (Pg.1)`
// Capturing Group (x) : Matches x and remembers the match.
// Non-Capturing Group (?:x) : Matches "x" but does not remember the match.
// Quantifier +? : Matches the previous token between
// one and unlimited times, as few times as possible,
// expanding as needed (lazy)
// Modifier g : global. All matches (don't return after first match)
// Modifier u : unicode. Enable all unicode features and
// interpret all unicode escape sequences as such
// #####################################################################
// CASE_A:To match the quoted texts like "One quote"
// Capturing Group (x) + non-greedy y+?
// const REGEX_QUOTED_TEXT = /(".+?")/gu;
// CASE_B:To match the quoted texts like "One quote" (Pg.1)
// Capturing Group (x) + non-greedy y+?
// const REGEX_QUOTED_TEXT = /(".+?")(\s\(Pg\.[0-9]+?\))/gu;
// CASE_A or CASE_B:
// Capturing Group (x) + non-greedy y+?
// const REGEX_QUOTED_TEXT = /(".+?")(\s\(Pg\.[0-9]+?\))?/gu;
// Non-Capturing Group (?:x) + non-greedy y+? : (For better performance)
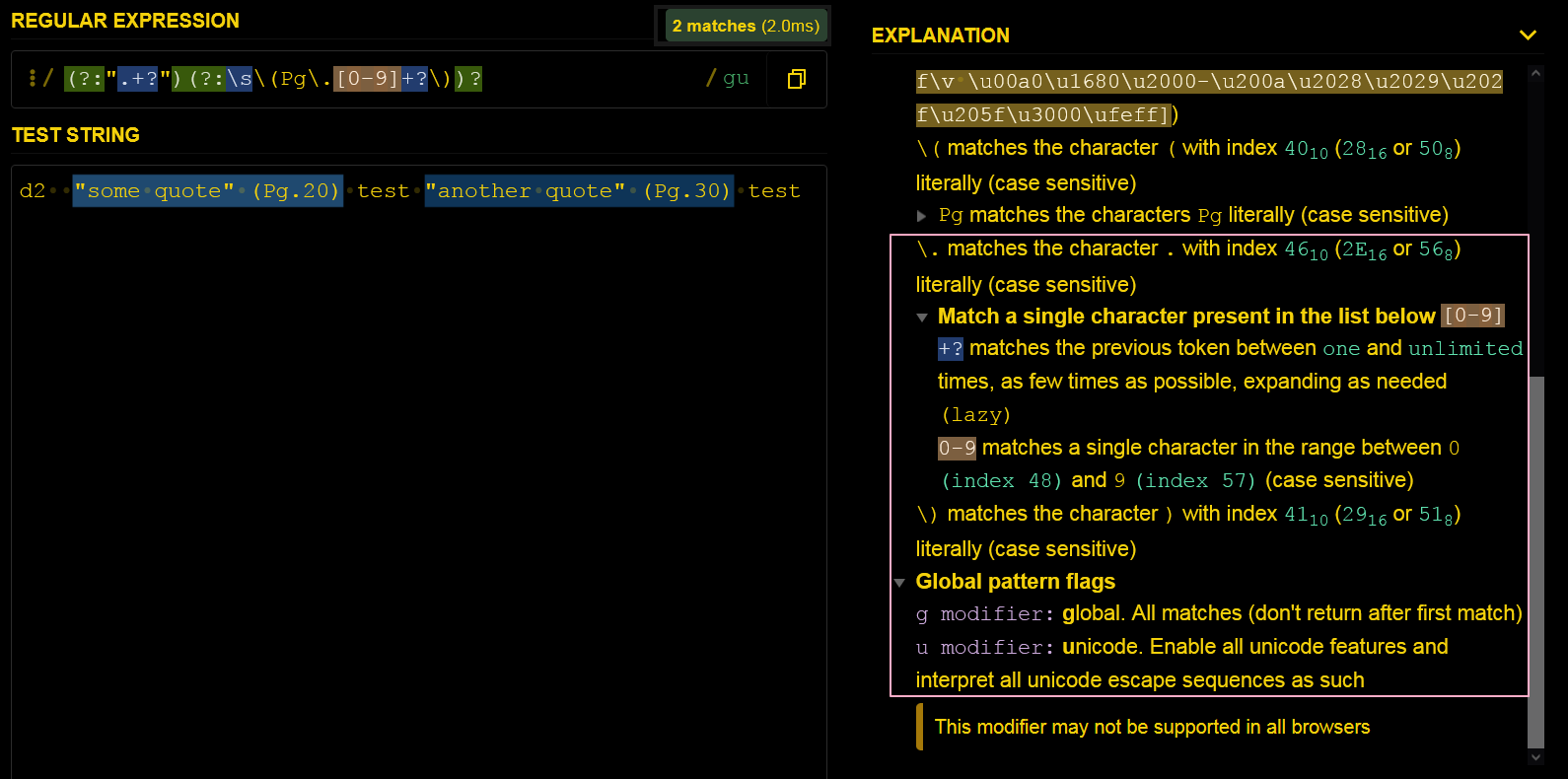
const REGEX_QUOTED_TEXT = /(?:".+?")(?:\s\(Pg\.[0-9]+?\))?/gu;
```
A1:
Non-Capturing Group (?:x) + non-greedy y+?
Non-Capturing Group (?:".+?")
Non-Capturing Group (?:\s\(Pg\.[0-9]+?\))?
Global pattern flags
g modifier: global. All matches (don’t return after first match)
u modifier: unicode. Enable all unicode features and interpret all unicode escape sequences as such
Q2: How to modify the code to output each quote as a list? (M31.FR35)
Summary_Q2
```JS
// M31.FR35 output aMatch:
// #####################################################################
// #####################################################################
// CASE_A: Output it as a list and
// display quoted texts that are from the same L.text in a single line
// #####################################################################
// dv.span(aMatch.join("<br>"));
// CASE_B: Output it as a list
// #####################################################################
// dv.el("span", aMatch);
// CASE_C: Output each quoted text in each single line
// #####################################################################
for (let e of aMatch) {
dv.el("span", e);
}
```
A2:
```JS
// M31.FR35 output aMatch:
// #####################################################################
// #####################################################################
// CASE_A: Output it as a list and
// display quoted texts that are from the same L.text in a single line
// #####################################################################
// dv.span(aMatch.join("<br>"));
// CASE_B: Output it as a list
// #####################################################################
dv.el("span", aMatch);
// CASE_C: Output each quoted text in each single line
// #####################################################################
// for (let e of aMatch) {
// dv.el("span", e);
// }
```
title: DVJS10_groupBy_fLink_flatten_fLists_and_LIST_under_the_heading => 1.To groupBy page.file.link as G1 (G1=group.rows) 2.To flatten page.file.lists 3.To gather a list item(or a task item) under any heading 4.To gather a list item(or a task item) that contains a quoted text 5.To gather a quoted text and push it into the aMatch array 6.To display each quoted text in each single line
collapse: close
icon:
color:
```dataviewjs
// M10. define sAuthor:
// #####################################################################
const sAuthor = "someone";
// M11. define pages: gather all relevant pages
// #####################################################################
let pages = dv
.pages('"100_Project/01_dataviewjs/01_by_example/Q22_Quotes/Q22_test_data"')
.where((page) => page.author === sAuthor);
// M21. define groups:
// To groupBy page.file.link AS G1 (G1=group.rows)
// #####################################################################
let groups = pages
.groupBy((page) => page.file.link);
//.sort((group) => group.key, "desc");
// M30. output sAuthor:
// #####################################################################
dv.header(2, "Author: " + sAuthor);
// M31. output groups:
// #####################################################################
for (let group of groups) {
// M31.FR10 define REGEX_QUOTED_TEXT:
// The pattern matches quoted texts like `"One quote"` or `"One quote" (Pg.1)`
// Capturing Group (x) : Matches x and remembers the match.
// Non-Capturing Group (?:x) : Matches "x" but does not remember the match.
// Quantifier +? : Matches the previous token between
// one and unlimited times, as few times as possible,
// expanding as needed (lazy)
// Modifier g : global. All matches (don't return after first match)
// Modifier u : unicode. Enable all unicode features and
// interpret all unicode escape sequences as such
// #####################################################################
// CASE_A:To match the quoted texts like "One quote"
// Capturing Group (x) + non-greedy y+?
// const REGEX_QUOTED_TEXT = /(".+?")/gu;
// CASE_B:To match the quoted texts like "One quote" (Pg.1)
// Capturing Group (x) + non-greedy y+?
// const REGEX_QUOTED_TEXT = /(".+?")(\s\(Pg\.[0-9]+?\))/gu;
// CASE_A or CASE_B:
// Capturing Group (x) + non-greedy y+?
// const REGEX_QUOTED_TEXT = /(".+?")(\s\(Pg\.[0-9]+?\))?/gu;
// Non-Capturing Group (?:x) + non-greedy y+? : (For better performance)
const REGEX_QUOTED_TEXT = /(?:".+?")(?:\s\(Pg\.[0-9]+?\))?/gu;
// M31.FR11 define aMatch: to store quoted texts
// #####################################################################
let aMatch = [];
// M31.FR13 define a_filtered_lists:
// FLATTEN_CASE_10:To FLATTEN page.file.lists and gather them
// WHERE_CASE_11 :To gather a list item(or a task item) under any heading
// WHERE_CASE_12A :To gather a list item(or a task item) that contains a quoted text
// WHERE_CASE_12B :To gather a quoted text and push it into the aMatch array
// #####################################################################
let a_filtered_lists = group.rows
.flatMap((page) => page.file.lists)
.where(
(L) =>
// M31.FR13.WH11 gather a list item(or a task item) under any heading
// #####################################################################
L.header.type === "header"
)
.where((L) => {
// M31.FR13.WH12A: gather the L that contains a quoted text
// #####################################################################
// #####################################################################
// M31.FR13.WH12B : define aQuotations
// to store the quoted texts from the L.text temporarily
// #####################################################################
// str.match(/regex/g) returns all matches as an array, but capturing groups are not included.
let aQuotations = L.text.match(REGEX_QUOTED_TEXT);
if (aQuotations) {
// M31.FR13.WH12B.IFT10P: to push the aQuotations array into the aMatch array
// #####################################################################
aMatch.push(aQuotations);
// M31.FR13.WH12A.IFT10Q: to gather the L
// #####################################################################
return true;
} else {
// M31.FR13.WH12A.IFF10: Not to gather the L
// #####################################################################
return false;
}
});
// M31.FR15 check a_filtered_lists.length :
// #####################################################################
if (a_filtered_lists.length === 0){
continue;
}
// M31.FR21 output page.file.link with group.rows.Book_Title[0] :
// #####################################################################
// dv.header(3, group.key);
//dv.header(3, group.key + ": " + group.rows.Book_Title[0]);
if (group.rows.Book_Title && group.rows.Book_Title[0]) {
let sBookTitle = group.rows.Book_Title[0];
let sLink = dv.sectionLink(group.key.path, sBookTitle, false, sBookTitle); //=>a
dv.header(3, sLink);
} else {
dv.header(3, group.key);
}
// M31.FR33 output a_filtered_lists.text: [without the desired structure]
// #####################################################################
//dv.span(a_filtered_lists.text);
// M31.FR35 output aMatch:
// #####################################################################
// #####################################################################
// CASE_A: Output it as a list and
// display quoted texts that are from the same L.text in a single line
// #####################################################################
// dv.span(aMatch.join("<br>"));
// CASE_B: Output it as a list
// #####################################################################
// dv.el("span", aMatch);
// CASE_C: Output each quoted text in each single line
// #####################################################################
for (let e of aMatch) {
dv.el("span", e);
}
}
```