Is it possible to set up a Dataview query or embedded search that returns highlights (==text==) from a given date range? E.g. returning something like:
Note title 1:
Highlight 1
Highlight 2
Note title 2:
Highlight 3
Highlight 4
Is it possible to set up a Dataview query or embedded search that returns highlights (==text==) from a given date range? E.g. returning something like:
Note title 1:
Highlight 1
Highlight 2
Note title 2:
Highlight 3
Highlight 4
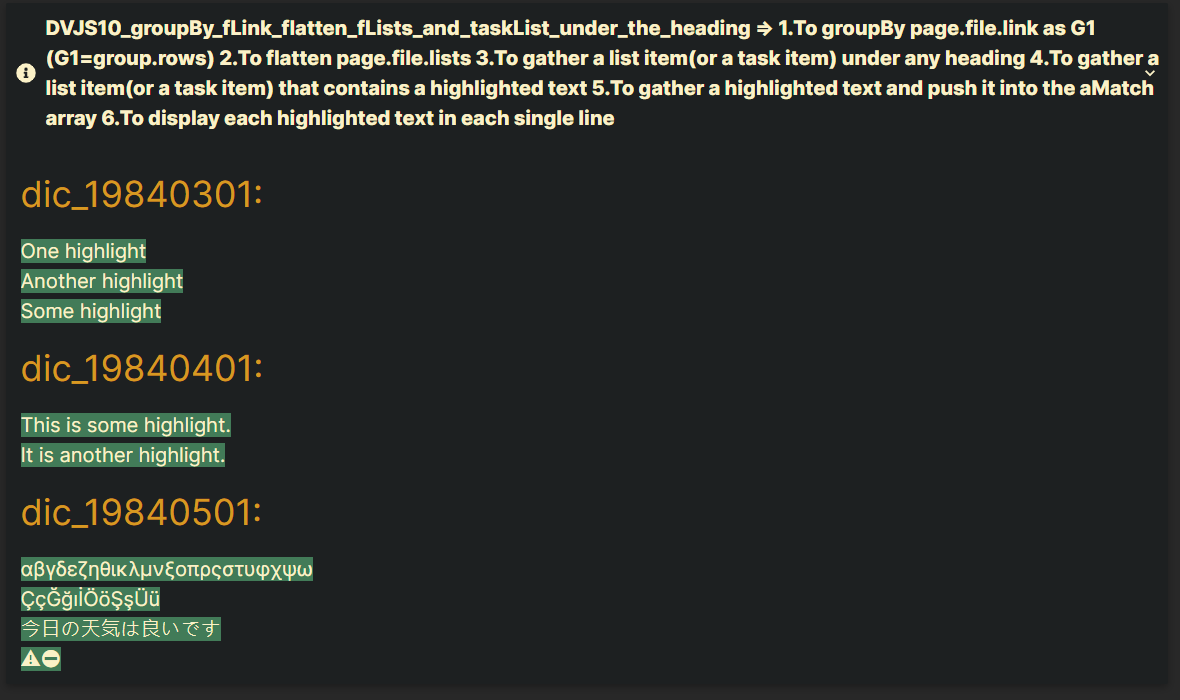
dic_19840301---
Date: 1984-03-01
---
### input_data
#### a
- a1 ==One highlight== test
- a2
#### b
- b1
- b2 ==Another highlight== test ==Some highlight== test
#### c
- [x] c1
- [ ] c2
#### d
- [ ] d1
- [x] d2
#### e
- [!] e1
- [ ] e2
#### f
dic_19840401---
Date: 1984-04-01
---
### input_data
#### a
- a1
- a2
#### b
- b1
- b2
#### c
- [>] c1
- [ ] c2 ==This is some highlight.== test
#### d
- [x] d1
- [ ] d2 ==It is another highlight.== test
#### e
- [ ] e1
- [x] e2
#### f
dic_19840501---
Date: 1984-05-01
---
### input_data
#### a
- a1 Greek Alphabet ==αβγδεζηθικλμνξοπρςστυφχψω== test
- a2
#### b
- b1
- b2 Turkish characters ==ÇçĞğıİÖöŞşÜü== test
#### c
- [ ] c1 Japanese hiragana Alphabet ==今日の天気は良いです== CJK Unified Ideographs
- [ ] c2 Warning Sign Emoji ==⚠⛔== No Entry Emoji
#### d
- [ ] d1
- [ ] d2
#### e
- [ ] e1
- [ ] e2
#### f
dic_19840801---
Date: 1984-08-01
---
### input_data
#### a
- a1 == Not highlight == test
- a2
#### b
- b1
- b2 == Not highlight == test == Not highlight == test
#### c
- [x] c1
- [ ] c2
#### d
- [ ] d1
- [x] d2
#### e
- [!] e1
- [ ] e2
#### f
| Code Name | Data type | Group By | Purposes | Remark |
|---|---|---|---|---|
| DVJS10 _groupBy_fLink _flatten_fLists _and_taskList _under_the_heading |
file.lists | yes groupIn:no |
1.To groupBy page.file.link as G1 (G1=group.rows) 2.To flatten page.file.lists 3.To gather a list item(or a task item) under any heading 4.To gather a list item(or a task item) that contains a highlighted text 5.To gather a highlighted text and push it into the aMatch array 6.To display each highlighted text in each single line |
The DVJS10 is based on the DVJS90 in the following topic. - Solutions: by Justdoitcc |
```JS
// M11. define pages: gather all relevant pages
// #####################################################################
let pages = dv
.pages('"100_Project/01_dataviewjs/01_by_example/Q21_Highlight/Q21_test_data"')
.where(
(page) =>
page.file.ctime >= dv.date("1984-03-01T00:00:00") &&
page.file.ctime <= dv.date("1984-05-31T23:59:59")
);
```
```JS
// M11. define pages: gather all relevant pages
// #####################################################################
let pages = dv
.pages('"100_Project/01_dataviewjs/01_by_example/Q21_Highlight/Q21_test_data"')
.where(
(page) =>
page.file.ctime.toFormat("yyyy-MM-dd HH:mm:ss") >=
dv.date("1984-03-01T00:00:00").toFormat("yyyy-MM-dd HH:mm:ss") &&
page.file.ctime.toFormat("yyyy-MM-dd HH:mm:ss") <=
dv.date("1984-05-31T23:59:59").toFormat("yyyy-MM-dd HH:mm:ss")
);
```
```JS
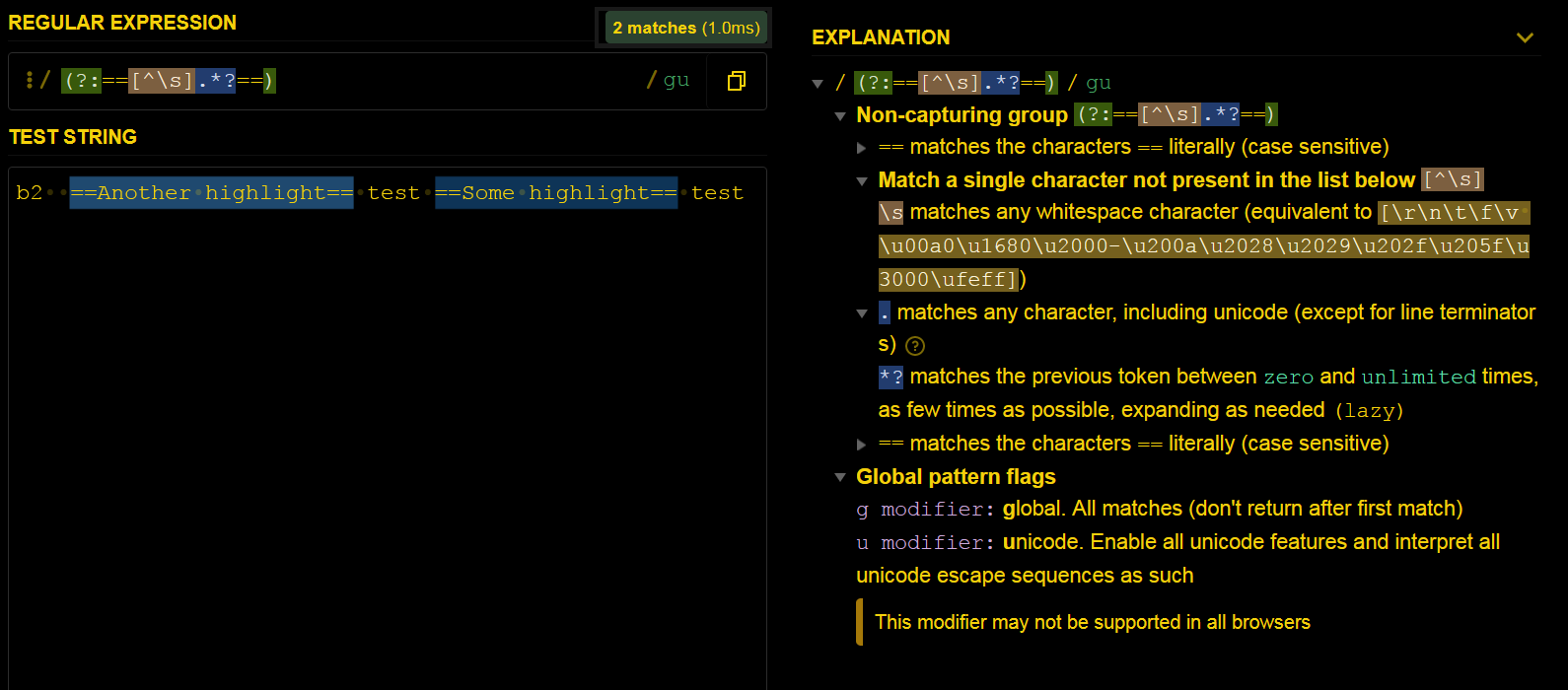
// M31.FR10 define REGEX_HIGHLIGHTED_TEXT:
// The pattern matches highlighted texts like `==text==` instead of `== text==`
// Capturing Group (x) : Matches x and remembers the match.
// Non-Capturing Group (?:x) : Matches "x" but does not remember the match.
// Quantifier *? : Matches the previous token between
// zero and unlimited times, as few times as possible,
// expanding as needed (lazy)
// Modifier g : global. All matches (don't return after first match)
// Modifier u : unicode. Enable all unicode features and
// interpret all unicode escape sequences as such
// #####################################################################
// Capturing Group (x) + non-greedy y*?
// const REGEX_HIGHLIGHTED_TEXT = /(==[^\s].*?==)/gu;
// Non-Capturing Group (?:x) + non-greedy y*? : (For better performance)
const REGEX_HIGHLIGHTED_TEXT = /(?:==[^\s].*?==)/gu;
```
(?:==[^\s].*?==)dic_19850301?```SQL
full_file_path = `=[[dic_19850301]].file.path`
```
//=>100_Project/01_dataviewjs/01_by_example/Q84_Contains/Q84_test_data/03/dic_19850301.md
From the result, you can copy the path as needs.
```JS
full_file_path = `$=dv.page("dic_19850301").file.path`
```
//=>100_Project/01_dataviewjs/01_by_example/Q84_Contains/Q84_test_data/03/dic_19850301.md
From the result, you can copy the path as needs.
title: DVJS10_groupBy_fLink_flatten_fLists_and_taskList_under_the_heading => 1.To groupBy page.file.link as G1 (G1=group.rows) 2.To flatten page.file.lists 3.To gather a list item(or a task item) under any heading 4.To gather a list item(or a task item) that contains a highlighted text 5.To gather a highlighted text and push it into the aMatch array 6.To display each highlighted text in each single line
collapse: close
icon:
color:
```dataviewjs
// M11. define pages: gather all relevant pages
// #####################################################################
let pages = dv
.pages('"100_Project/01_dataviewjs/01_by_example/Q21_Highlight/Q21_test_data"')
.where(
(page) =>
page.file.ctime >= dv.date("1984-03-01T00:00:00") &&
page.file.ctime <= dv.date("1984-05-31T23:59:59")
);
// M21. define groups:
// To groupBy page.file.link AS G1 (G1=group.rows)
// #####################################################################
let groups = pages
.groupBy((page) => page.file.link);
//.sort((group) => group.key, "desc");
// M31. output groups:
// #####################################################################
for (let group of groups) {
// M31.FR10 define REGEX_HIGHLIGHTED_TEXT:
// The pattern matches highlighted texts like `==text==` instead of `== text==`
// Capturing Group (x) : Matches x and remembers the match.
// Non-Capturing Group (?:x) : Matches "x" but does not remember the match.
// Quantifier *? : Matches the previous token between
// zero and unlimited times, as few times as possible,
// expanding as needed (lazy)
// Modifier g : global. All matches (don't return after first match)
// Modifier u : unicode. Enable all unicode features and
// interpret all unicode escape sequences as such
// #####################################################################
// Capturing Group (x) + non-greedy y*?
// const REGEX_HIGHLIGHTED_TEXT = /(==[^\s].*?==)/gu;
// Non-Capturing Group (?:x) + non-greedy y*? : (For better performance)
const REGEX_HIGHLIGHTED_TEXT = /(?:==[^\s].*?==)/gu;
// M31.FR11 define aMatch: to store highlighted texts
// #####################################################################
let aMatch = [];
// M31.FR13 define a_filtered_lists:
// FLATTEN_CASE_10:To FLATTEN page.file.lists and gather them
// WHERE_CASE_11 :To gather a list item(or a task item) under any heading
// WHERE_CASE_12A :To gather a list item(or a task item) that contains a highlighted text
// WHERE_CASE_12B :To gather a highlighted text and push it into the aMatch array
// #####################################################################
let a_filtered_lists = group.rows
.flatMap((page) => page.file.lists)
.where(
(L) =>
// M31.FR13.WH11 gather a list item(or a task item) under any heading
// #####################################################################
L.header.type === "header"
)
.where((L) => {
// M31.FR13.WH12A: gather the L that contains a highlighted text
// #####################################################################
// #####################################################################
// M31.FR13.WH12B : define aHighlights
// to store the highlighted texts from the L.text temporarily
// #####################################################################
// str.match(/regex/g) returns all matches as an array, but capturing groups are not included.
let aHighlights = L.text.match(REGEX_HIGHLIGHTED_TEXT);
if (aHighlights) {
// M31.FR13.WH12B.IFT10P: to push the aHighlights array into the aMatch array
// #####################################################################
aMatch.push(aHighlights);
// M31.FR13.WH12A.IFT10Q: to gather the L
// #####################################################################
return true;
} else {
// M31.FR13.WH12A.IFF10: Not to gather the L
// #####################################################################
return false;
}
});
// M31.FR15 check a_filtered_lists.length :
// #####################################################################
if (a_filtered_lists.length === 0){
continue;
}
// M31.FR21 output page.file.link :
// #####################################################################
dv.header(3, group.key + ":");
// M31.FR33 output a_filtered_lists.text: [without the desired structure]
// #####################################################################
//dv.span(a_filtered_lists.text);
// M31.FR35 output aMatch:
// #####################################################################
// #####################################################################
// CASE_A: Output it as a list and
// display highlighted texts that are from the same L.text in a single line
// #####################################################################
// dv.span(aMatch.join("<br>"));
// CASE_B: Output it as a list
// #####################################################################
// dv.el("span", aMatch);
// CASE_C: Output each highlighted text in each single line
// #####################################################################
for (let e of aMatch) {
dv.el("span", e);
}
}
```
Thank you for sharing! I can logically follow most of the code, but I’m unsure of how to modify the quoted line with the path to instead skim the “Sources” folder of my vault. I tried the following:
.pages(‘“C:\Users\user.name\Documents\98 Sources\Sources”’)
Where 98 Sources is the top folder for this vault.
and received this error:
Evaluation Error: SyntaxError: \8 and \9 are not allowed in strict mode.
at DataviewInlineApi.eval (plugin:dataview:19673:21)
at evalInContext (plugin:dataview:19674:7)
at asyncEvalInContext (plugin:dataview:19684:32)
at DataviewJSRenderer.render (plugin:dataview:19705:19)
at DataviewJSRenderer.onload (plugin:dataview:19289:14)
at DataviewJSRenderer.e.load (app://obsidian.md/app.js:1:852364)
at t.e.addChild (app://obsidian.md/app.js:1:852765)
at t.addChild (app://obsidian.md/app.js:1:1246250)
at Object.addChild (app://obsidian.md/app.js:1:1245275)
at DataviewApi.executeJs (plugin:dataview:20214:19)
Happy to send a kofi etc your way once I get this working - will be a huge help for my flow.
```JS
// M11. define pages: gather all relevant pages
// #####################################################################
let pages = dv
.pages('"98 Sources/Sources"');
```
```SQL
full_file_path = `=[[dic_19850301]].file.path`
```
//=>100_Project/01_dataviewjs/01_by_example/Q84_Contains/Q84_test_data/03/dic_19850301.md
From the result, I will copy the path as needs.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.