Whenever you do a “GROUP BY” all the stuff you previous referred to as someField are now lists within rows.someField. And when someField is a list, this gets complicated in combination with stuff like filter and similar functions. Some of this issues can be countered by doing sum(rows.someField), but it’s a lot of trial and error to verify the results in either case.
I’ve compiled two variants for your request, one which FLATTEN all the tasks before grouping and calculating the various results, and one which is a little more similar to your original case without FLATTEN on the tasks.
Further more the two variants as slight differences in how to calculate the completed and uncompleted count, based on how you want to group queries.
Using FLATTEN on tasks
The FLATTEN query
```dataview
TABLE Count, Open as "` `", InProgress as "/", Complete as "x", Canceled as "`-`", UncompleteCount as UnC, CompleteCount as C,
join(rows.item.status, "|") as Statuses,
"<progress value='" + (UncompleteCount * 100 ) / Count + "' max='100' />" as "Uncompleted Progress",
"<progress value='" + (CompleteCount * 100) / Count + "' max='100' />" as "Completed Progress"
FROM "ForumStuff/f4x"
FLATTEN file.lists as item
WHERE item.task and contains(list(" ", "/", "-", "x"), item.status)
GROUP BY file.folder
FLATTEN length(rows.item.text) as Count
FLATTEN length(filter(rows.item.status, (s) => s = " ")) as Open
FLATTEN length(filter(rows.item.status, (s) => s = "/")) as InProgress
FLATTEN length(filter(rows.item.status, (s) => s = "x")) as Complete
FLATTEN length(filter(rows.item.status, (s) => s = "-")) as Canceled
FLATTEN Open + InProgress + Canceled as UncompleteCount
FLATTEN Complete as CompleteCount
```
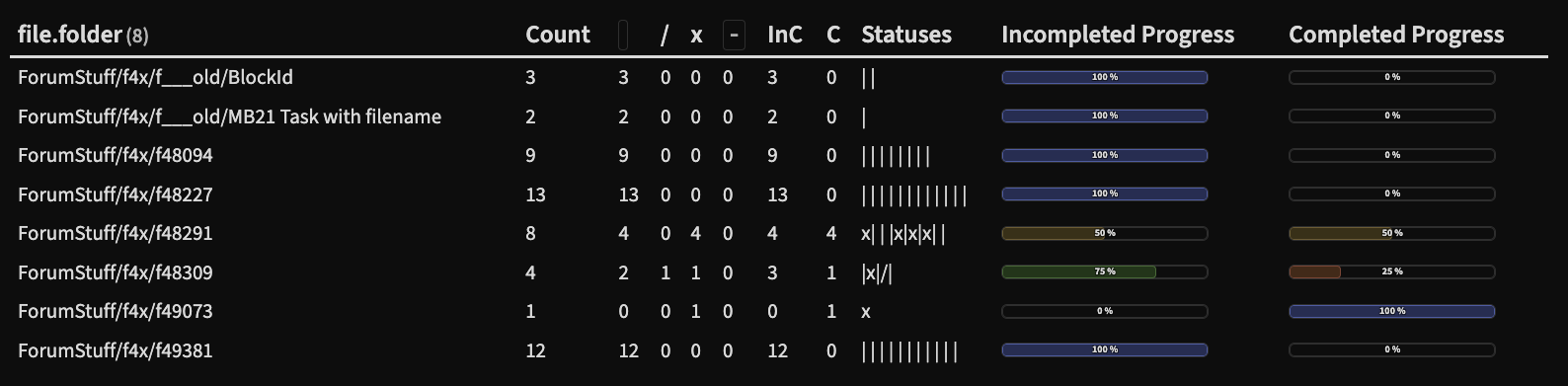
Output using FROM "ForumStuff/f4x" in my test vault:
The columns signify the count of the various statuses, named in the column header. InC and C indicate the Incompleted Count and Complete Count. Also note, that in this query I limited to only the “normal” task statuses: space, /, - and x.
In this query I count the various statuses up into their own variable, and then I sum the various statuses into another variable which is used to produce the progress bar. This is very easy to use and change into various groupings depending on whether you want to include canceled tasks into completed or uncompleted task count.
Notice that in both cases I’ve joined up the various statuses into a string separated by |, so if there are many spaces, there are also many |'s.
Not using FLATTEN on tasks
The non FLATTEN query
It’s kind of incorrect to say non-flatten query, as I’m still using FLATTEN to gather up stuff into variables, but it doesn’t flatten the file.tasks before grouping, similar to your original query.
```dataview
TABLE
Total, Incomplete, Complete,
join(sum(rows.file.tasks.status), "|") as Statuses,
"<progress value='" + ( Incomplete * 100) / Total + "' max='100'></progress>" AS "Incomplete Progress",
"<progress value='" + ( Complete * 100)/ Total + "' max='100'></progress>" AS "Complete Progress"
FROM "ForumStuff/f4x"
WHERE file.tasks
GROUP BY file.folder
FLATTEN length(sum(rows.file.tasks.status)) as Total
FLATTEN length(filter(sum(rows.file.tasks.status), (t) => t = " " or t = "/")) as Incomplete
FLATTEN length(filter(sum(rows.file.tasks.status), (t) => t = "A" or t = "x")) as Complete
```
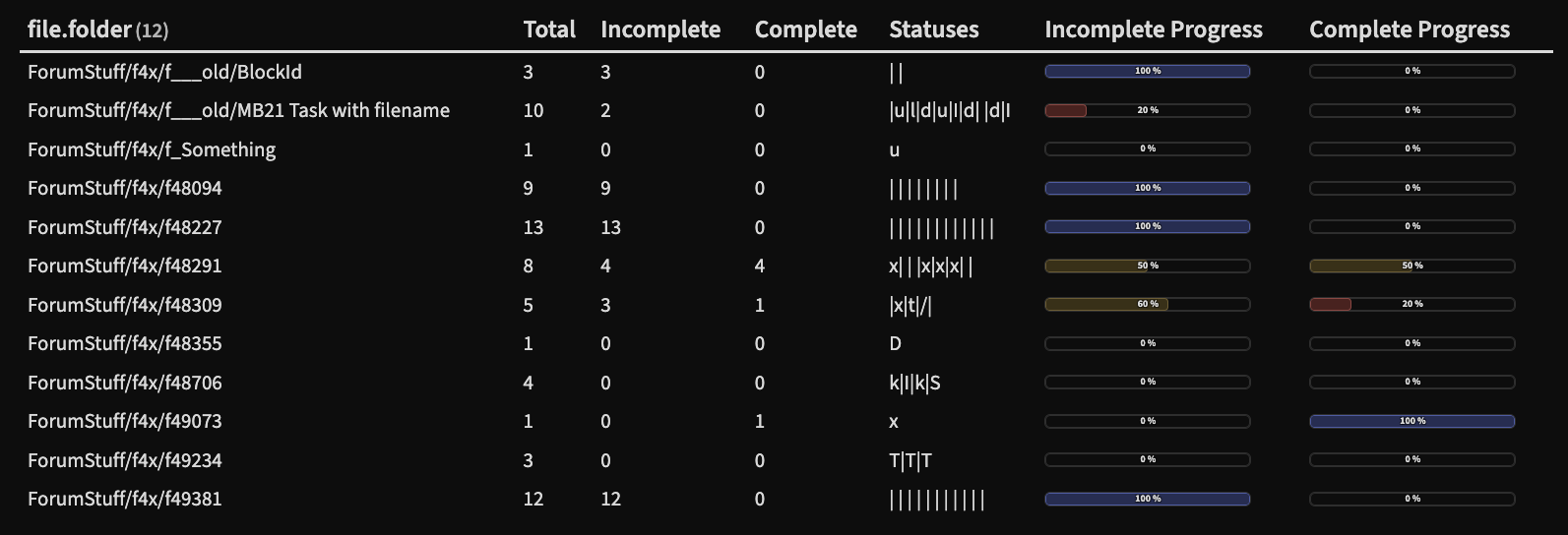
Which for the same folder in my test vaults now outputs:
In this query I selected just a few statuses to count, and used or to choose multiple of them. Could/should probably used contains(list(...), t) similar to how I selected which to focus on in the first query. Leaving that as an exercise for the reader… 
So in this query if the status is space or / it’s counted as incomplete, and if it’s x or A it’s counted as complete. One can also see that the status column is more diverse than in the first query since I opened up the query somewhat. (And also that the total doesn’t really match, as some of the tasks in my test set isn’t just the normal status variants)
In summary, the trick to getting this to work is to use FLATTEN ... as someVariable to collate calculated values, and that when using GROUP BY all the previously fields are now gathered under the rows.SOMETHING lists. And finally, that since we are grouping on files, we also need to do sum(rows...) in some cases to loose a level in the lists introduces by the GROUP BY.
I’ve not added a ton of explanation to these queries, but feel free to ask if there is something in particular being especially unclear.