I kind of had given up on getting the complete lists of tags, and was about to write a post on how you would need to change into using inline fields to be able to gather all the various tags. Then I read this post where they utilise app.metadataCache.getFileCache().tags, which was a function I was wondering about existed but hadn’t located yet.
I then proceeded to build some test files, and in the main file I had these queries:
---
Tags: f75210
---
questionUrl:: http://forum.obsidian.md/t//75210
```dataview
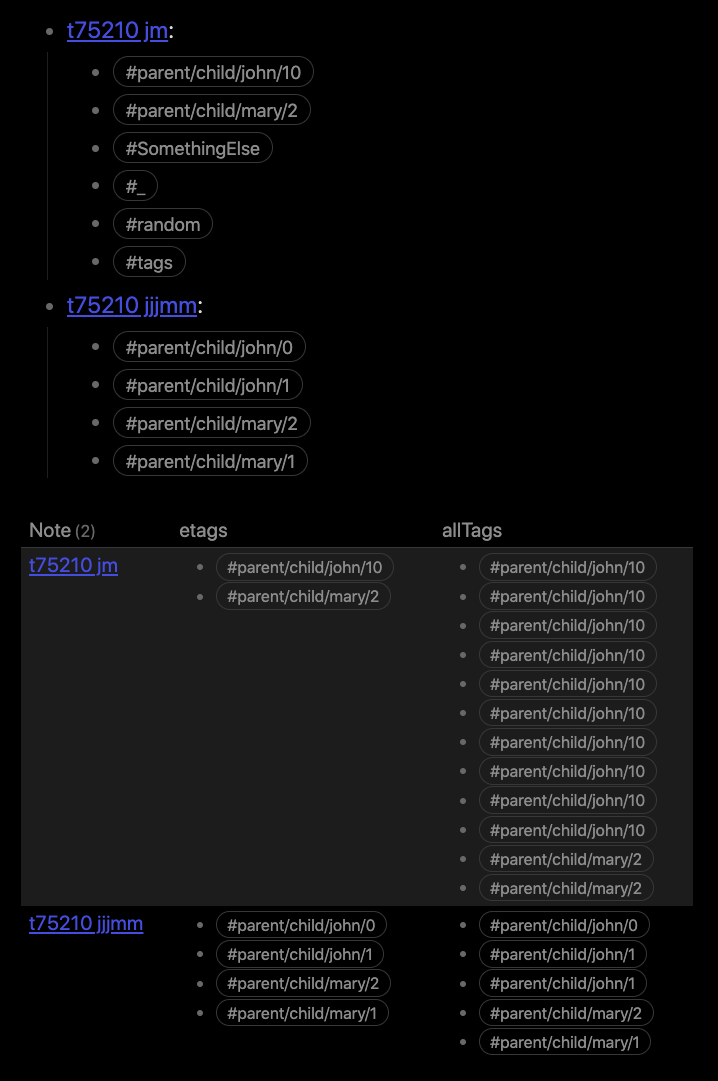
LIST file.etags
FROM #parent
```
```dataviewjs
const parentFiles = dv.pages("#parent")
.map(p => { return {
"file": p.file,
"etags": p.file.etags.filter(f => f.startsWith("#parent")),
"allTags": null }
})
.mutate(p => {
const tFile = app.vault.getAbstractFileByPath(p.file.path)
const allTags = app.metadataCache.getFileCache(tFile)
.tags
.filter(f => f.tag.startsWith("#parent"))
.map(m => m.tag)
p.allTags = allTags
})
.map(p => [p.file.link, p.etags, p.allTags])
dv.table(["Note", "etags", "allTags"], parentFiles)
```
Which produces this output in my test vault:
Here we can see that the first naive approach using file.etags shows the unique tags, but the second output shows each occurrence of the tags present in that file (filtered for #parent... tags).
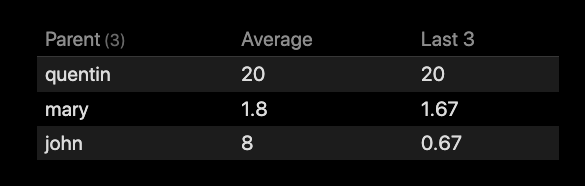
Based upon the latter query variation, it should be possible to achieve your goals of building a better average for the various cases. Will you be able to convert your existing script based upon this query?
A little explanation on the latter query. I start out by limiting our file set to those having any tags related to #parent (which happens to pick up all the nested tags as well). I then map the result to our specific needs mapping them to an object with the file, file.etags and allTags, where the latter is just a placeholder for stuff to be added later on.
In the mutate() below I then find the tFile for the file in question, and get the cache entries related to this, and filter out those related to #parent mapping only the tag to our temporary list (as we’re not interested in the positions as such). Then I do another map, just to make the output of the table even simpler… I’m a little lazy every now and then.