Obsidian’s potential for organization and linking:
I really like how Obsidian MOCs allow you the flexibility of links and the structure of folders so you can look at things from a bottom-up and top-down perspective depending on the need. Some great Obsidian Youtubers have put out amazing content on MOCs, so it inspired me to make my own spin on it.
A personal issue with Obsidian’s “limitations”:
I wondered how people always know what files belong in a MOC, because I find the backlinks functionality unusable. I type so much that certain keywords show up and give me a backlog of hundreds of backlinks. And the fact that I can’t go through each instance and either accept useful backlinks, leave semi-useful backlinks, or hide useless backlinks (for example, links from URLs) means I end up with way too many backlinks to realistically sort through and make good MOCs from. This feature suggestion (and this one, too) would solve the backlinks issue.
Another issue is just a personal quirk of mine. I apparently don’t create many internal links, which means MOCs don’t always show up organically. However, I do have specific topics of interest which I know will eventually become MOCs. I guess I’ll call them “proto-MOCs”.
My solution to my gripes:
I’m using dataview queries in conjunction with the templater plugin to find files that are related to a given proto-MOC. I can then process each link. If I think the link is relevant, I can manually link it, and that suggested link will disappear from the dataview query. If I think the link is irrelevant, I can mark it as irrelevant, and that suggested link will also disappear from the dataview query. Now I can truly look at just the links that need to be sorted!
In addition, I use a modified version of the Johnny Decimal system, so if I find that a file is relevant specifically to a proto-MOC, I can rename it with the appropriate ID. This is also theoretically compatible with infinite Luhmann’s Zettle ID if you append the JD ID with that sort of alternating alphanumeric stuff.
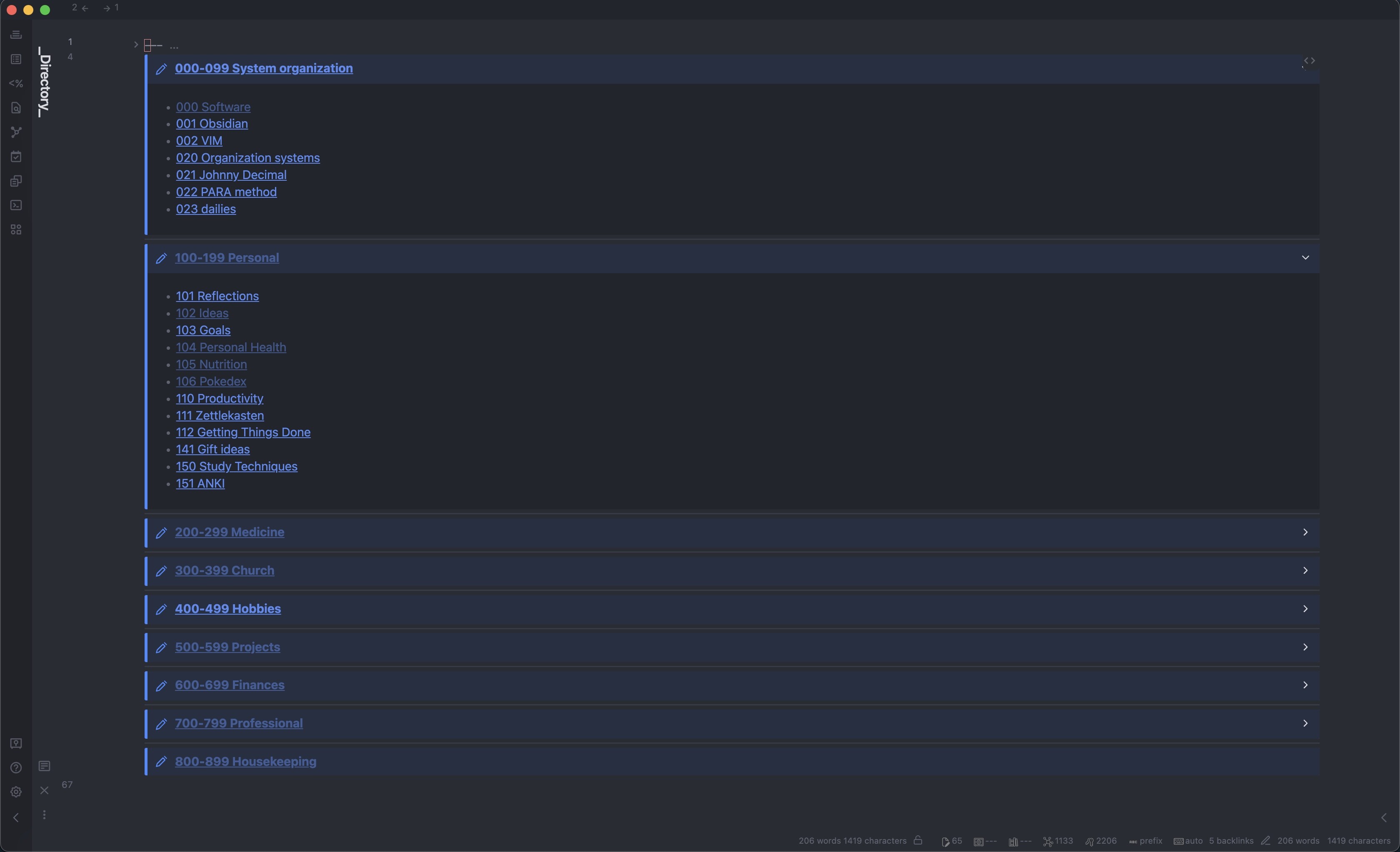
I’m using a central directory of proto-MOCs, based on the Johnny Decimal system:
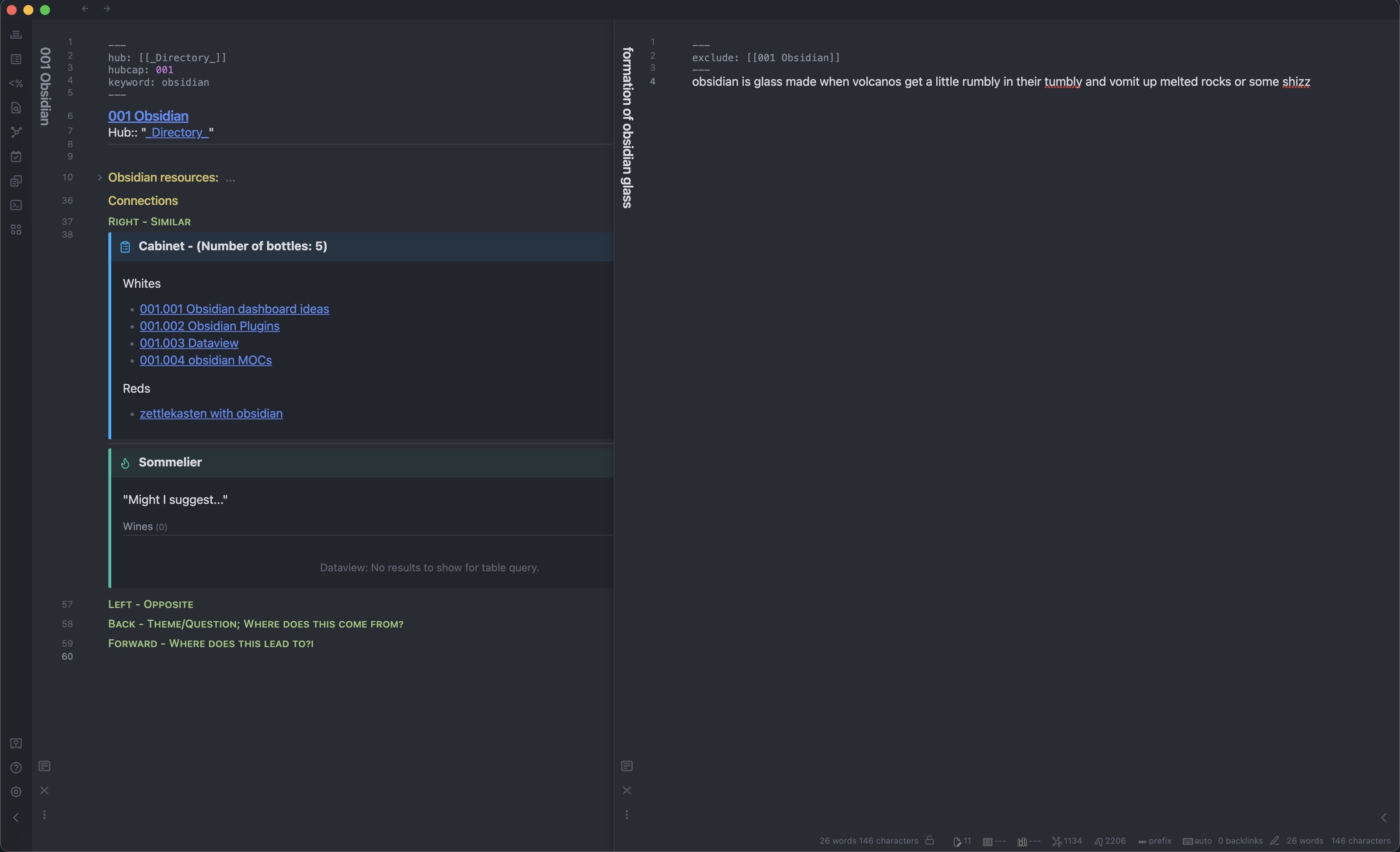
In the callout labeled “Sommelier”, you can see that files that matched the query. In the callout labeled “Cabinet”, you can see the files that were already processed, as well as a inline JS counter of how many files were processed.
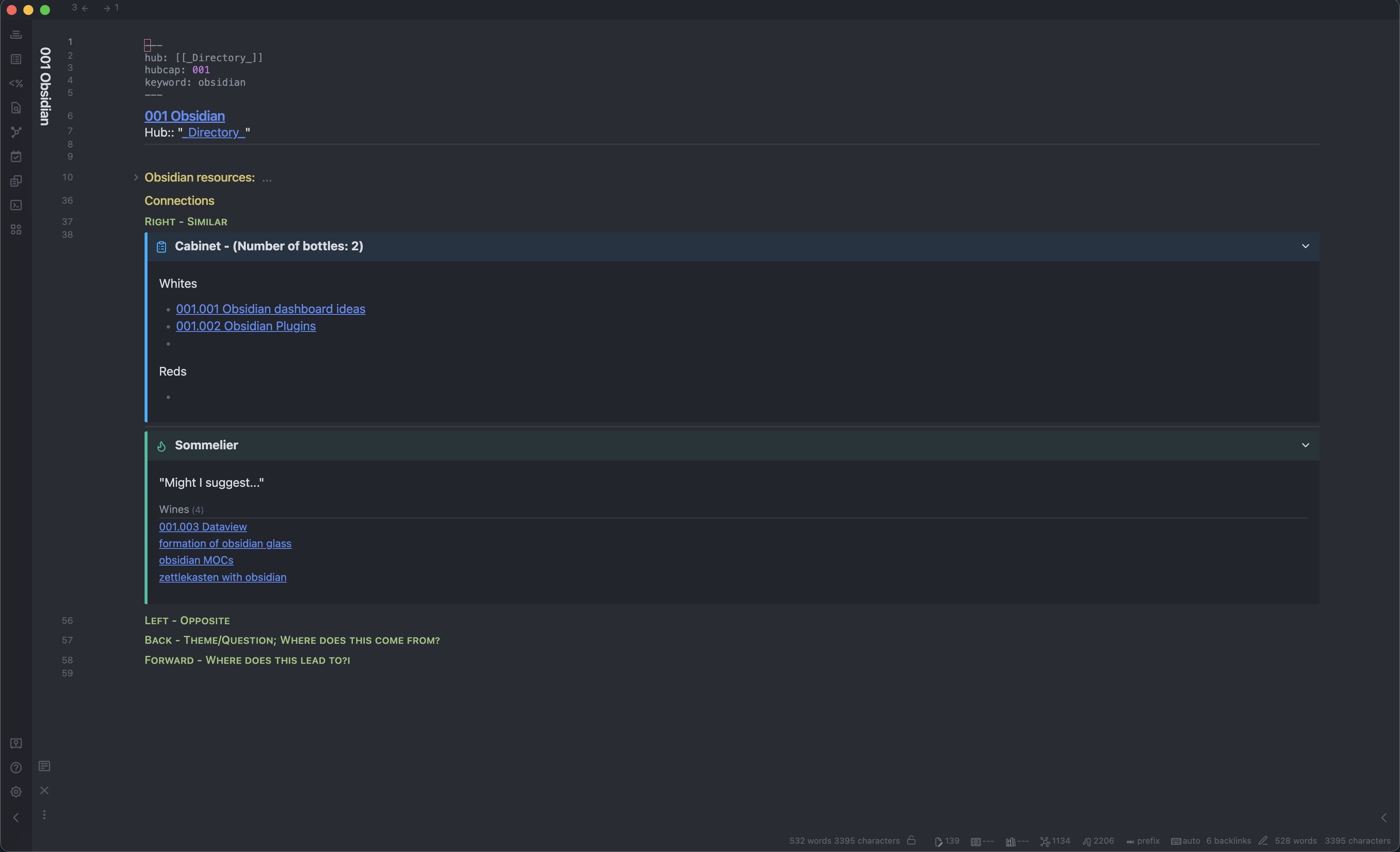
I decided that "101.003 Dataview belonged to “whites” because it exclusively relates to Obsidian. (Though I suppose I could have renamed it to “101.003a Dataview” to be more in-line with Luhmann). I added “obsidian MOCs” to “whites” for the same reason, and I also renamed it to the JD ID. I also decided “zettlekasten with obsidian” belonged to “reds” because it fits into another proto-MOC I have. Note how the counter and the Sommelier automatically update.
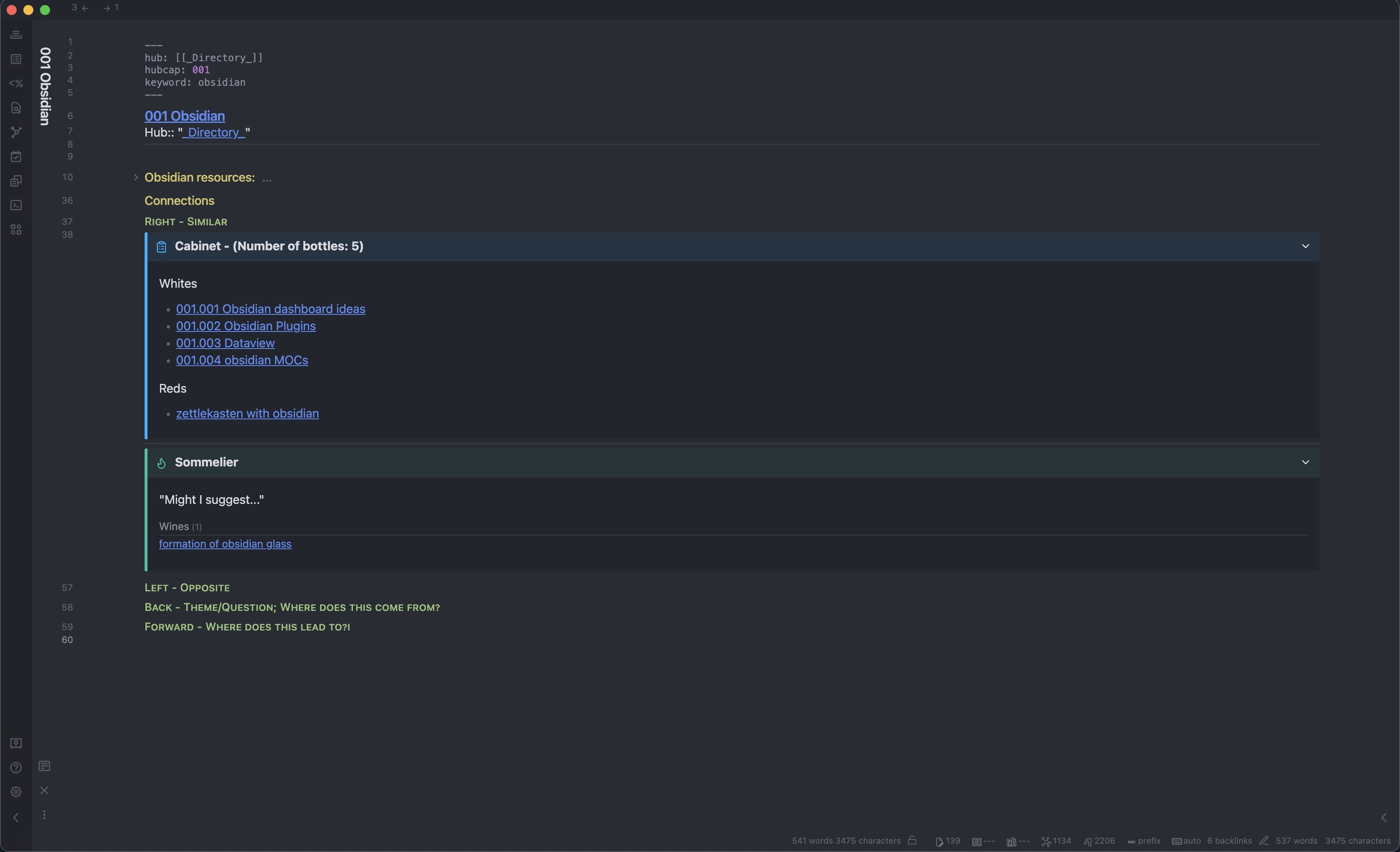
I then excluded “formation of obsidian glass” using metadata
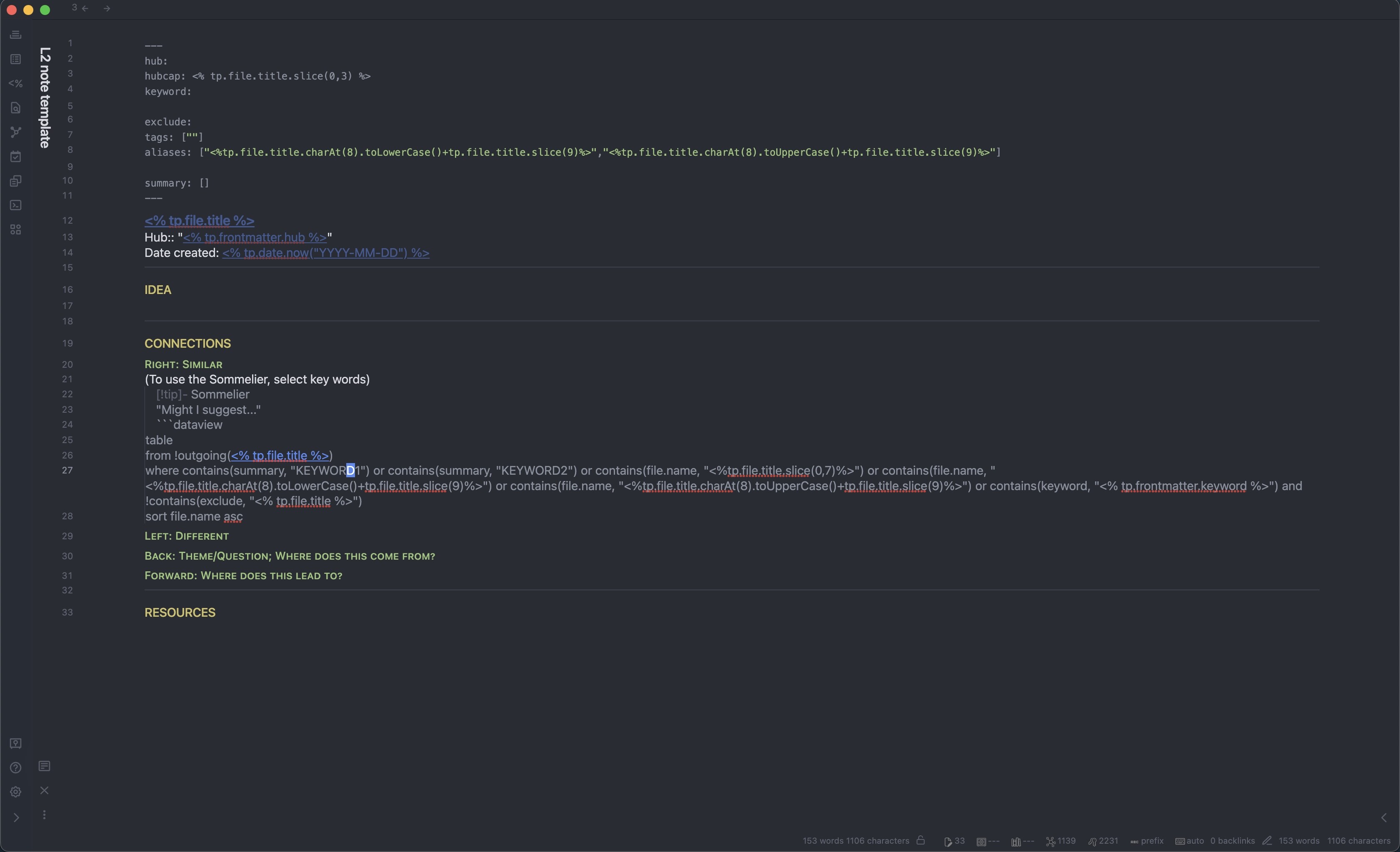
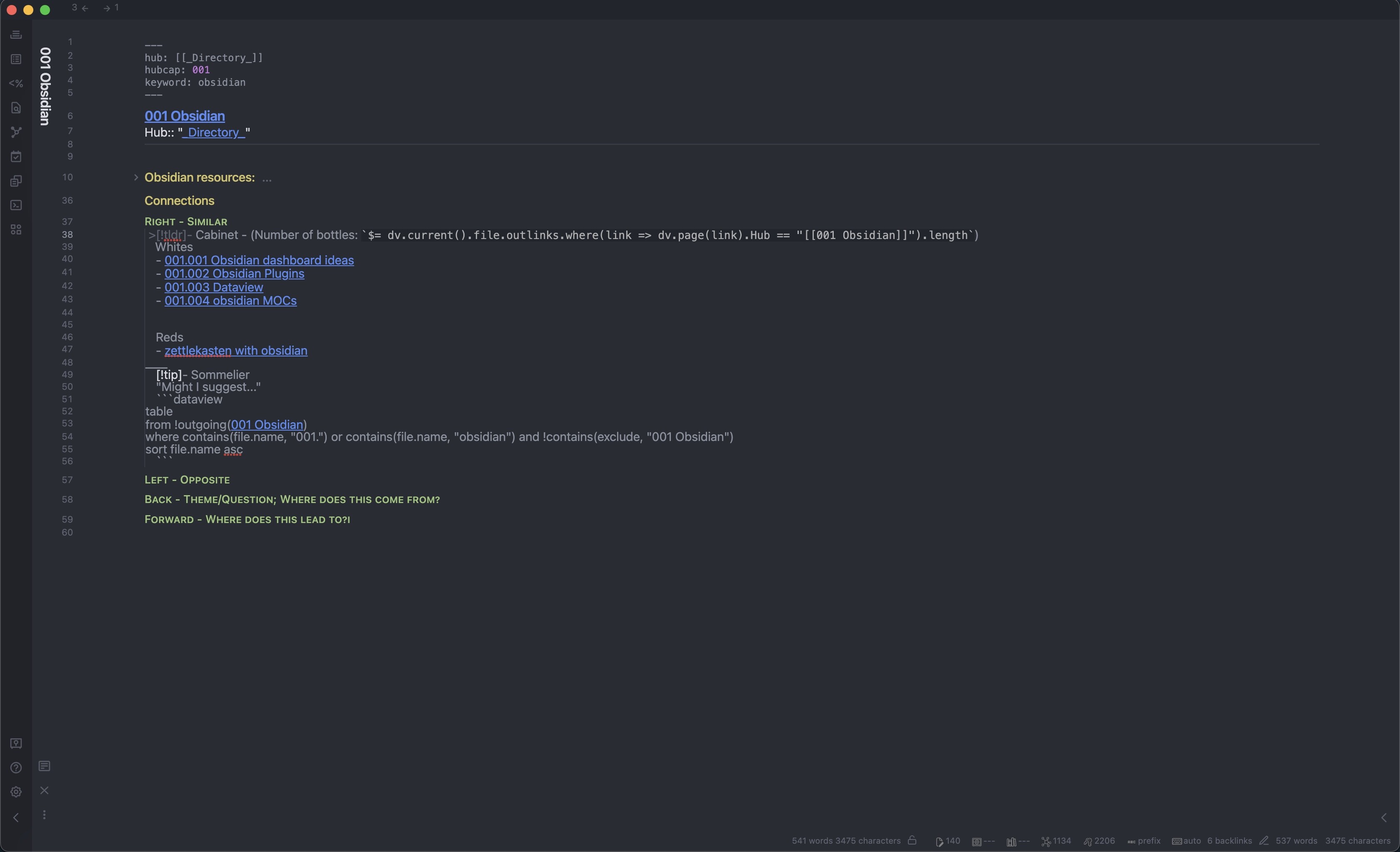
Here is the dataview query I used for my proto-MOCs
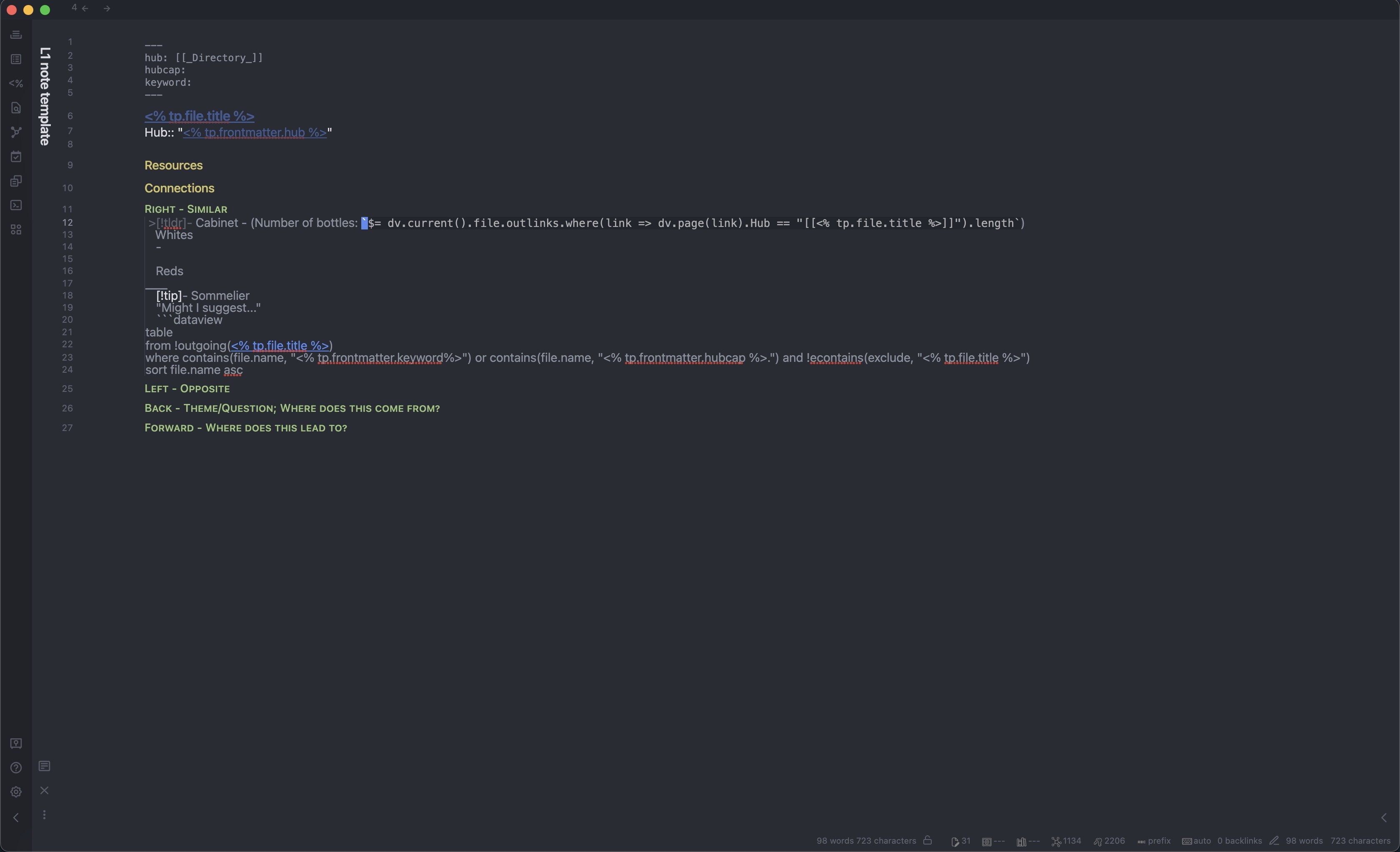
Here is the template I used for my proto-MOCs
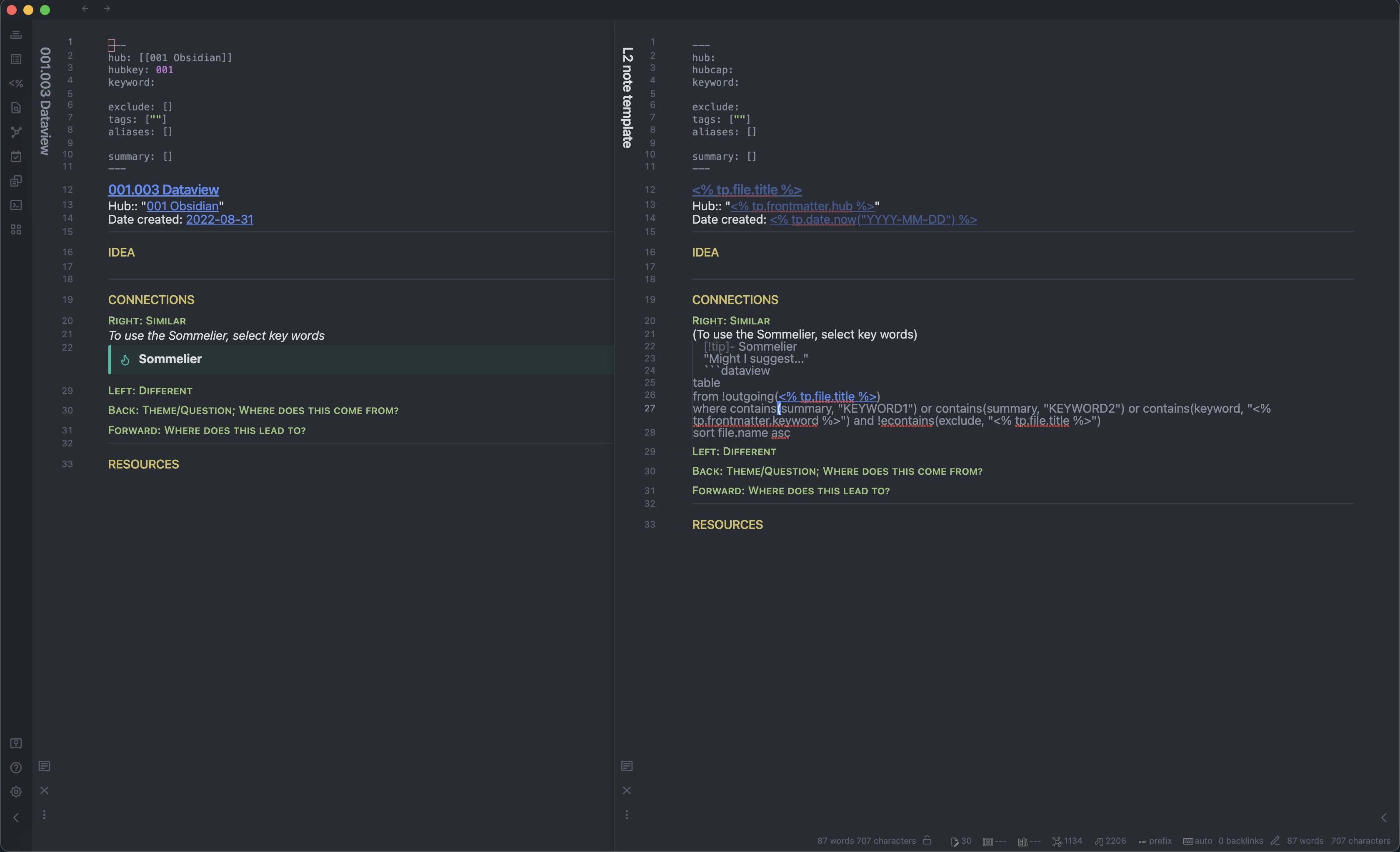
Here is a sub-note and its template (the sommelier needs manual editing of the KEYWORDs, and the summary needs to be filled out. Although this could probably be automated with YAML, I didn’t want to do that for some reason, probably because the YAML was already getting too cluttered)
The weakness of this workaround:
This workaround is limited because it has limited information. It only searches the file titles rather than the entire body of the file, which majorly reduces the number of possible returned queries. So I’m not going to be able to find every single occurance of relevant keywords. I rely on metadata, so I have to consciously think of keywords that might be relevant. Also, I am unable to make the query search for multiple keywords without making extra keyword fields (e.g. keyword1, keyword2 etc). I’m sure there’s a way around this but I don’t know how to do it. One way would be to use tags, but I want to minimize tag clutter and use it for things that I find especially relevant.