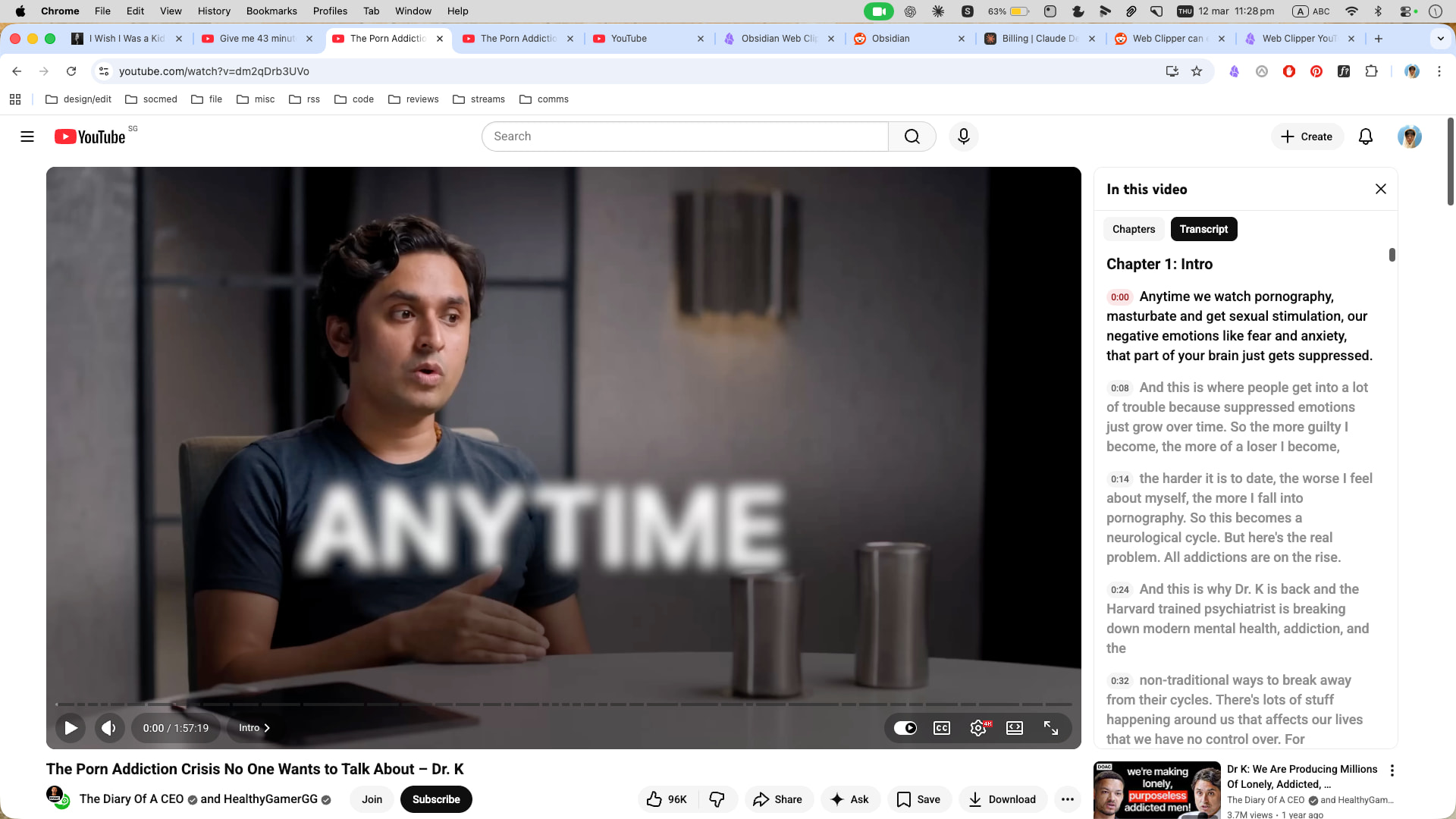
After getting extremely frustrated this morning and working with Claude for a while, I finally found that the CSS selector hasn’t changed, but the target-id changed, for YouTube transcripts due to their February 2026 UI update.
Here is an updated template you can use for anyone else that’s been fighting this recently.
{
"schemaVersion": "0.1.0",
"name": "YouTube with transcript (2026 fix)",
"behavior": "create",
"noteContentFormat": "## About\n\ntype:: #type/video/youtube\n\n\n\n## Description\n\n{{schema:@VideoObject:description}}\n\n## Notes\n\n\n\n## Transcript\n\n{{selectorHtml:ytd-engagement-panel-section-list-renderer[target-id=\"PAmodern_transcript_view\"] span.yt-core-attributed-string|replace:\" \":\" \"|join|markdown}}",
"properties": [
{
"name": "created",
"value": "{{time|date:\"YYYY-MM-DDTHH:mm:ssZ\"}}",
"type": "datetime"
},
{
"name": "url",
"value": "{{schema:@VideoObject:embedUrl|replace:\"embed/\":\"watch?v=\"}}",
"type": "text"
},
{
"name": "title",
"value": "{{schema:@VideoObject:name}}",
"type": "text"
},
{
"name": "channel",
"value": "{{schema:@VideoObject:author}}",
"type": "text"
},
{
"name": "published",
"value": "{{schema:@VideoObject:uploadDate|date:\"YYYY-MM-DD\"}}",
"type": "datetime"
},
{
"name": "thumbnailUrl",
"value": "{{schema:@VideoObject:thumbnailUrl|first}}",
"type": "text"
},
{
"name": "duration",
"value": "{{schema:@VideoObject:duration|replace:\"PT\",\"\",\"S\",\"\"}}",
"type": "text"
}
],
"triggers": [
"https://www.youtube.com/watch"
],
"noteNameFormat": "{{schema:@VideoObject:uploadDate|date:\"YYYY-MM-DD\"}} VIDEO {{schema:@VideoObject:author}} - {{schema:@VideoObject:name|safe_name|trim}}",
"path": ""
}
Or if you just want the transcript bit to paste into an existing template:
{{selectorHtml:ytd-engagement-panel-section-list-renderer[target-id=“PAmodern_transcript_view”] span.yt-core-attributed-string|replace:" “:” "|join|markdown}}
Cheers