Vault Intelligence: Transform your Obsidian vault into an active research partner
I am excited to share Vault Intelligence, a plugin that turns your static note collection into a dynamic knowledge base you can converse with. I built this not just to “add AI” to Obsidian, but to solve the specific problem of synthesis: finding the hidden connections between your ideas and developing them further.
What is Vault Intelligence?
Vault Intelligence turns your Obsidian vault from a passive archive into an active partner. It connects the dots between your ideas, finding relationships and insights that you might have missed. Unlike generic chatbots, the **Researcher** agent lives inside your notes, citing your specific files and helping you build on your own groundwork.
![]()
Key Features
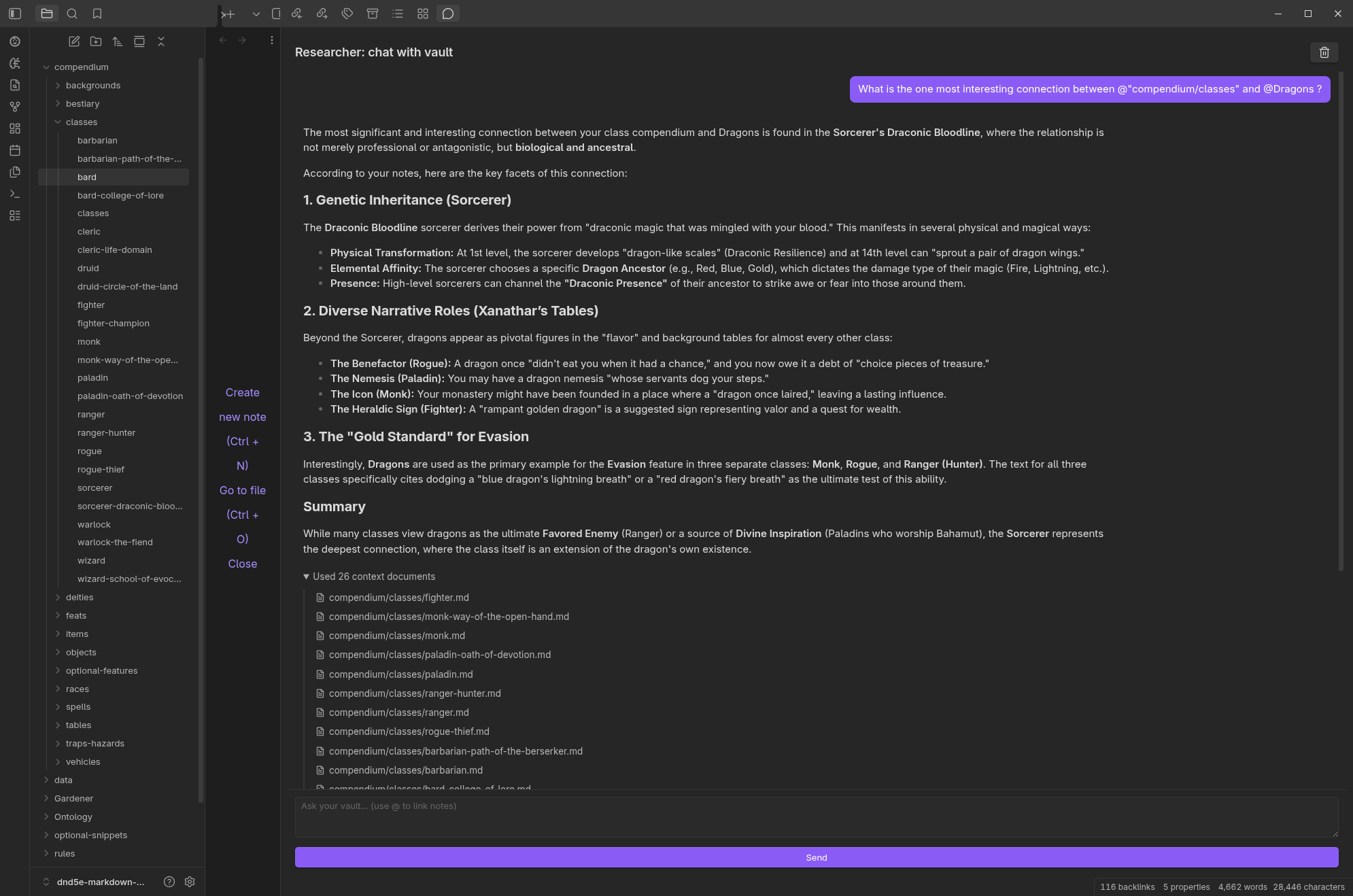
1. The Researcher: Your Reasoning Engine
The core of the plugin is the Researcher. You can ask it questions like:
“What do I know about [Topic]?”
Or complex questions like:
“What are the conflicting arguments about [Topic] in my notes?”
It reads your relevant notes, synthesizes an answer, and provides citations. Every claim is backed by a link to your source file.
It has search grounding, so it can verify your information with Google Search. For example:
“What do I know about [Topic] and is it still relevant and up to date?”
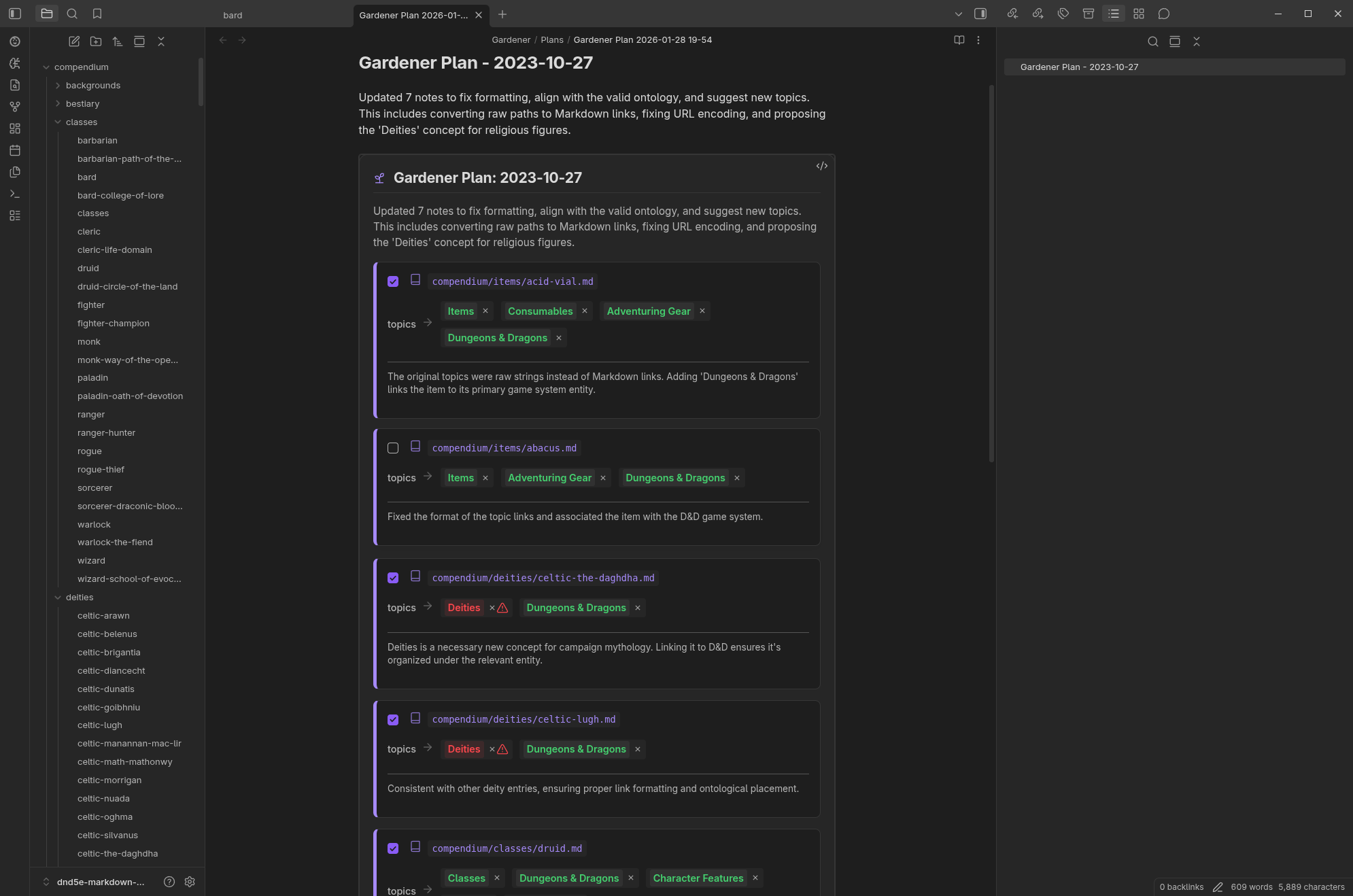
2. The Gardener: Scalable Structure
The Gardener agent helps keep your vault tidy. It uses advanced reasoning to suggest the best ontology for your notes, ensuring your structure scales as your knowledge grows, while keeping you firmly in control.
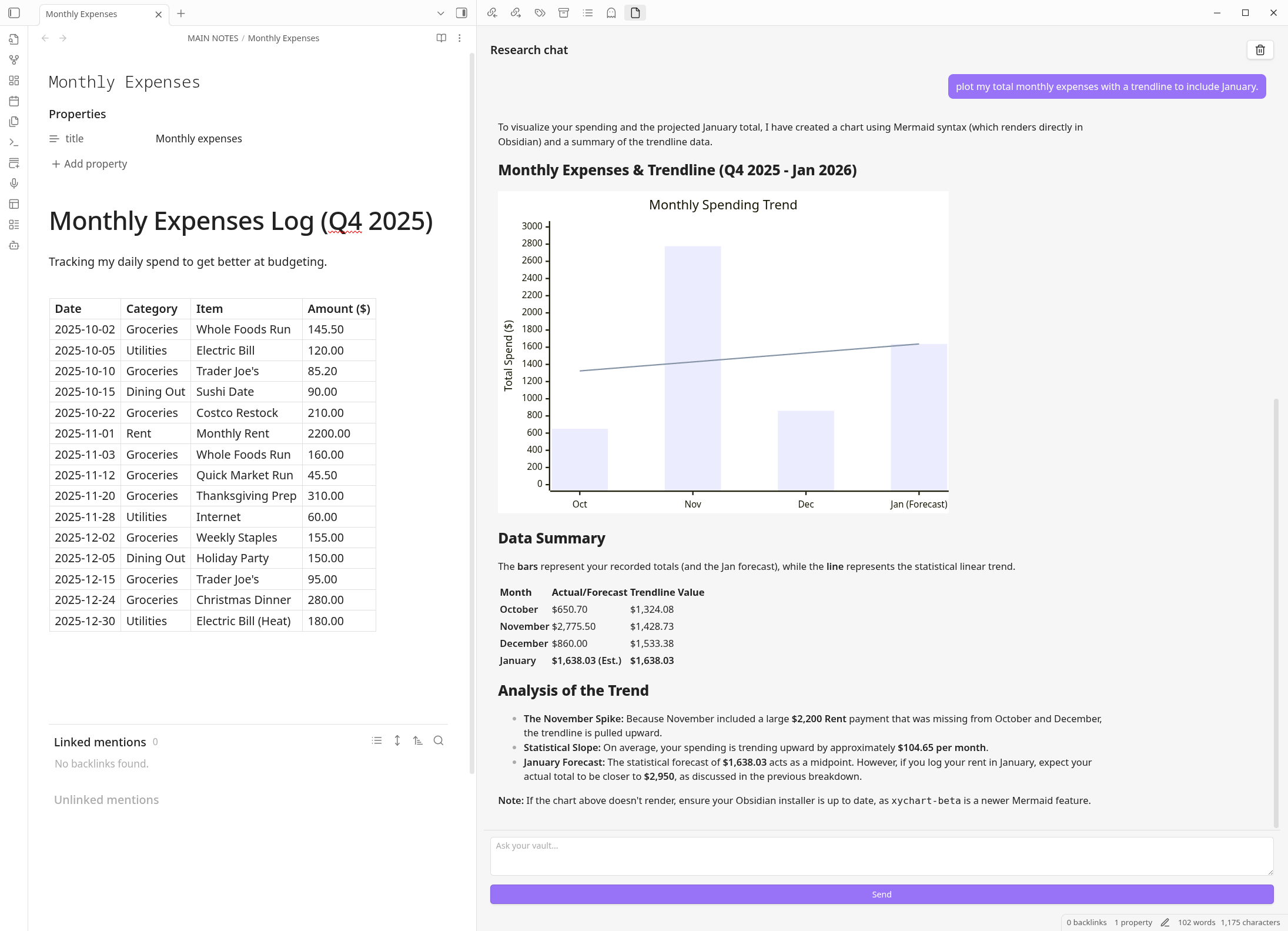
3. The Solver: Computational Power
Standard AI models struggle with math and data. The Solver includes an embedded Python engine that can run code to analyse your notes—whether it’s forecasting trends from a spreadsheet or calculating the compound interest of your investments.
4. New in 4.3: Active Assistance
The Research Assistant is no longer just a passive observer. It can now create and update notes for you—always with a “Trust but Verify” confirmation so you stay in control. It also speaks your language, with native support for dozens of languages and the ability to switch models on the fly for complex reasoning.
Why Vault Intelligence?
We spend years collecting notes, but rarely do we synthesise them into something new. Vault Intelligence bridges that gap.
-
From Archive to Agent: Your vault shouldn’t just be a storage box. It should be an active partner that suggests connections, organizes your mess, and helps you write.
-
Grounded Truth: Unlike a web chat, this agent knows you. It cites your specific files, respecting the context of your years of work.
-
Vault-Native Design: We didn’t just wrap a chatbot. We engineered a system that understands the unique structure of an Obsidian vault—your links, tags, and hierarchy. It respects the way you organize, treating your knowledge base as a connected web rather than just a pile of files.
Getting Started
I am currently releasing this via BRAT (Beta Reviewers Auto-update Tool) while finalizing the Community Plugins submission.
- Install the BRAT plugin from the Community Store.
- Add the repository: https://github.com/cybaea/obsidian-vault-intelligence
- Enable Vault Intelligence (this is the default in BRAT).
- Add your Google AI Studio key in settings.
I would love to hear your feedback on how it changes your workflow!
Links: GitHub Repository | Documentation | Report Issues
