In your example you’re using :construction: to get that emoji, that’s a no-go for file name. You need to use the true emoji character, aka 🚧 (and ⛰️), for the filename to be legal.
With that correction, try out the following queries:
## Table of current files "a" tasks
```dataview
TABLE WITHOUT ID text, project, workhours
FLATTEN file.tasks as task
FLATTEN array(split(task.text, " ", 2)) as time
FLATTEN regexreplace(substring(task.text, 18), " *\[\[🚧.*$", "") as text
FLATTEN filter(task.outlinks, (l) => startswith(meta(l).display, "🚧")) as project
FLATTEN (date("2023-06-02T" + time[1]) - date("2023-06-02T" + time[0])) as workhours
WHERE file.path = this.file.path
WHERE task.status = "a"
AND regextest("\d{2}:\d{2}:\d{2}", time[0])
AND regextest("\d{2}:\d{2}:\d{2}", time[1])
```
## As a task query
```dataview
TASK
FLATTEN array(split(text, " ", 2)) as time
FLATTEN regexreplace(substring(text, 18), " *\[\[🚧.*$", "") as text
FLATTEN filter(outlinks, (l) => startswith(meta(l).display, "🚧")) as project
FLATTEN (date("2023-06-02T" + time[1]) - date("2023-06-02T" + time[0])) as workhours
FLATTEN text + " " + project + " " + workhours as visual
WHERE file.path = this.file.path
WHERE status = "a"
AND regextest("\d{2}:\d{2}:\d{2}", time[0])
AND regextest("\d{2}:\d{2}:\d{2}", time[1])
```
Given the usage of proper emojis, this should produce something like the following in your own locale:
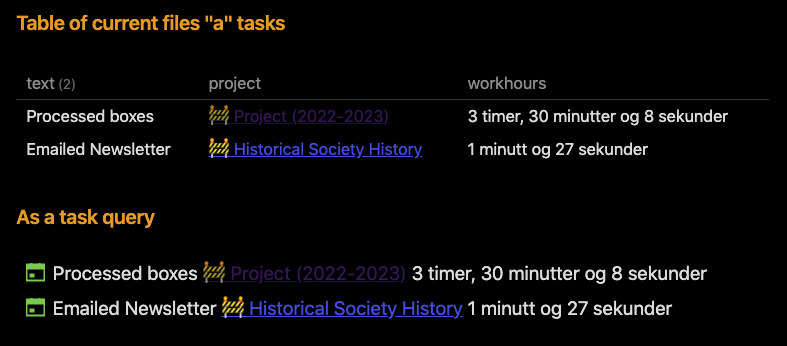
These queries uses a multitude of various tricks to pull out the wanted data, and there is little to none error checking, so if you leave out or misformat the times it’ll fail. If you don’t have the project first, it’ll fail, and so on. It’s more a proof of concept, than anything else.
An attempt at explaining the query
FLATTEN file.tasks as task– Within theTABLEcontext we need to do this access each task as a separate task in thetaskvariableFLATTEN array(split(task.text, " ", 2)) as time– Usingsplit(..., " ", ")the text in question is split on the space character, and we keep the two first entries. However, since we’re in aFLATTENwhich loves to flatten arrays, we need to pack the entire thingy inarray( ... )to preserve these two values into thetimevariable. Nowtime[0]will hold the start time, andtime[1]will hold the end timeFLATTEN regexreplace(substring(task.text, 18), " *\[\[🚧.*$", "") as text– In order to get the information in the task without the times and link, we skip the first 18 characters usingsubstring( ... , 18), and then we useregexreplace()to get rid of the link starting with the project emoji, and until end of line. This could be done with a single regex, but I kind of like this alternative. The result is stored intextFLATTEN filter(task.outlinks, (l) => startswith(meta(l).display, "🚧")) as project– In your example to focused on the project, so lets filter out only the outlinks of the tasks going to a link starting with the project emoji, and store this link asprojectFLATTEN (date("2023-06-02T" + time[1]) - date("2023-06-02T" + time[0])) as workhours– Construct two proper dates and subtract them from each other. I’m using todays date as a “random” date to make the timestamps into dates, and then just subtract the dates from each other. This produces as duration. Note that these can be formatted, and manipulated further using sub-fields, and so on. Like you could do<duration>.hoursto get the<duration>as pure hour output. (Other valid sub-fields are: years, quarters, months, weeks, days, hours, minutes, seconds, milliseconds)WHERE file.path = this.file.path– ThisWHEREclause limits this query to only look in the current file. Can be removed for a query across your entire vault (and/or combined with aFROMclause (before anyFLATTENline) to limit where to look for tasks like these)WHERE task.status = "a" AND regextest("\d{2}:\d{2}:\d{2}", time[0]) AND regextest("\d{2}:\d{2}:\d{2}", time[1])– ThisWHEREclause verifies that we’re only looking at tasks of type[a], and that the two time parts are actually timestampts with hours, minutes and seconds
Even further details when transforming into a TASK query
The query is then repeated as a TASK query, and not just a TABLE query. To transform the query the following needs to be done:
- No need to do the
FLATTEN file.tasks as tasksince in that is implicit in this type of query - Due to the previous, remove all references to
task. - You can’t have multiple columns within a task text, but you can redefine the task test and name it
visual, and still maintain the task link to the original task text! I really like this hidden gem of theTASKqueries!
The project query variants
When going to the project queries, you need to keep the basic structure of the queries with all the FLATTEN calculations, but you might want to add extra information like file.link to get the originating note (at least in the table variant). And you need to limit to only the current project. So one variant for the table query would then be:
```dataview
TABLE WITHOUT ID file.link as note, text, workhours
FLATTEN file.tasks as task
FLATTEN array(split(task.text, " ", 2)) as time
FLATTEN regexreplace(substring(task.text, 18), " *\[\[🚧.*$", "") as text
FLATTEN filter(task.outlinks, (l) => startswith(meta(l).display, "🚧")) as project
FLATTEN (date("2023-06-02T" + time[1]) - date("2023-06-02T" + time[0])) as workhours
WHERE task.status = "a"
AND regextest("\d{2}:\d{2}:\d{2}", time[0])
AND regextest("\d{2}:\d{2}:\d{2}", time[1])
WHERE project = this.file.link
```
Note the changes on the top line, with the removal of project and addition of file.link as Note, and the change of the limiting WHERE clause to limit to this project. The query above, and the TASK variant below needs to be in the “home page” of that project to properly work.
As a TASK query
```dataview
TASK
FLATTEN array(split(text, " ", 2)) as time
FLATTEN regexreplace(substring(text, 18), " *\[\[🚧.*$", "") as text
FLATTEN filter(outlinks, (l) => startswith(meta(l).display, "🚧")) as project
FLATTEN (date("2023-06-02T" + time[1]) - date("2023-06-02T" + time[0])) as workhours
FLATTEN text + ": " + workhours + " (" + file.link + ")" as visual
WHERE status = "a"
AND regextest("\d{2}:\d{2}:\d{2}", time[0])
AND regextest("\d{2}:\d{2}:\d{2}", time[1])
WHERE project = this.file.link
```
Same kind of changes, and here I’ve added the file.link to the end of the task text. Could’ve used GROUP BY file.name or similar, but my preference is this variant.
Calculation of project totals
If you in addition to the previous queries like to calculate the sum of how much time has been spent on the various projects, you could add the usage of sum() function in some combination of either GROUP BY true when dealing with a single project, or GROUP BY project if you want to list all the totals. Here is the variant for all sums:
```dataview
TABLE sum(rows.workhours) as total
FLATTEN file.tasks as task
FLATTEN array(split(task.text, " ", 2)) as time
FLATTEN regexreplace(substring(task.text, 18), " *\[\[🚧.*$", "") as text
FLATTEN filter(task.outlinks, (l) => startswith(meta(l).display, "🚧")) as project
FLATTEN (date("2023-06-02T" + time[1]) - date("2023-06-02T" + time[0])) as workhours
WHERE task.status = "a"
AND regextest("\d{2}:\d{2}:\d{2}", time[0])
AND regextest("\d{2}:\d{2}:\d{2}", time[1])
GROUP BY project
```
Weekly/monthly variants
These queries, which I leave up to you to generate, are basically variant over the same template as given in the queries above. What you need to vary is the WHERE clauses to pick out a suitable data set, so that instead of a WHERE file.path = this.file.path you need to concoct something to limit your file set to the week/month of choice.
Summation and/or listing of the various tasks will be the same as before.
For details on how to create CSS to decorate the task like I’ve done see: