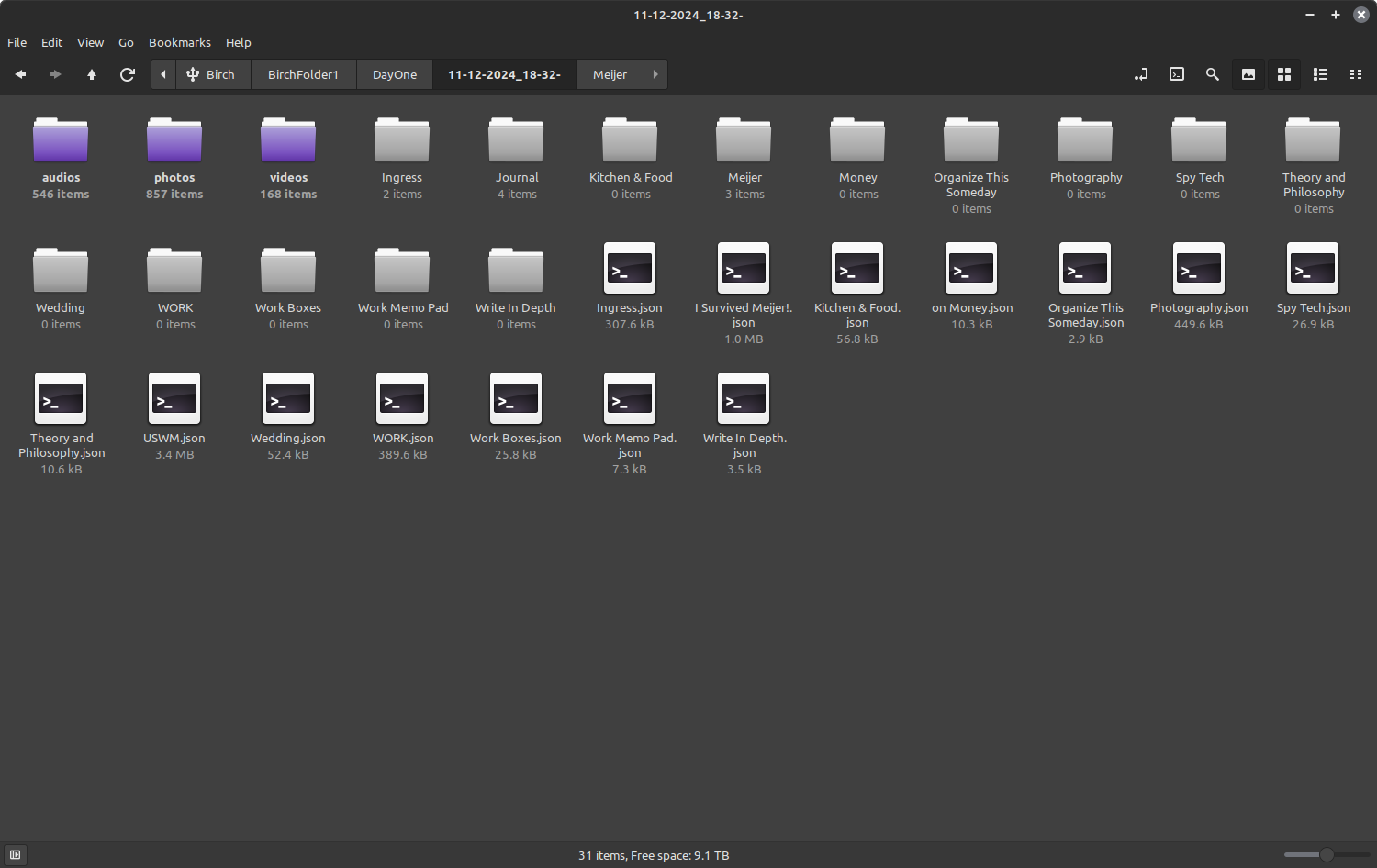
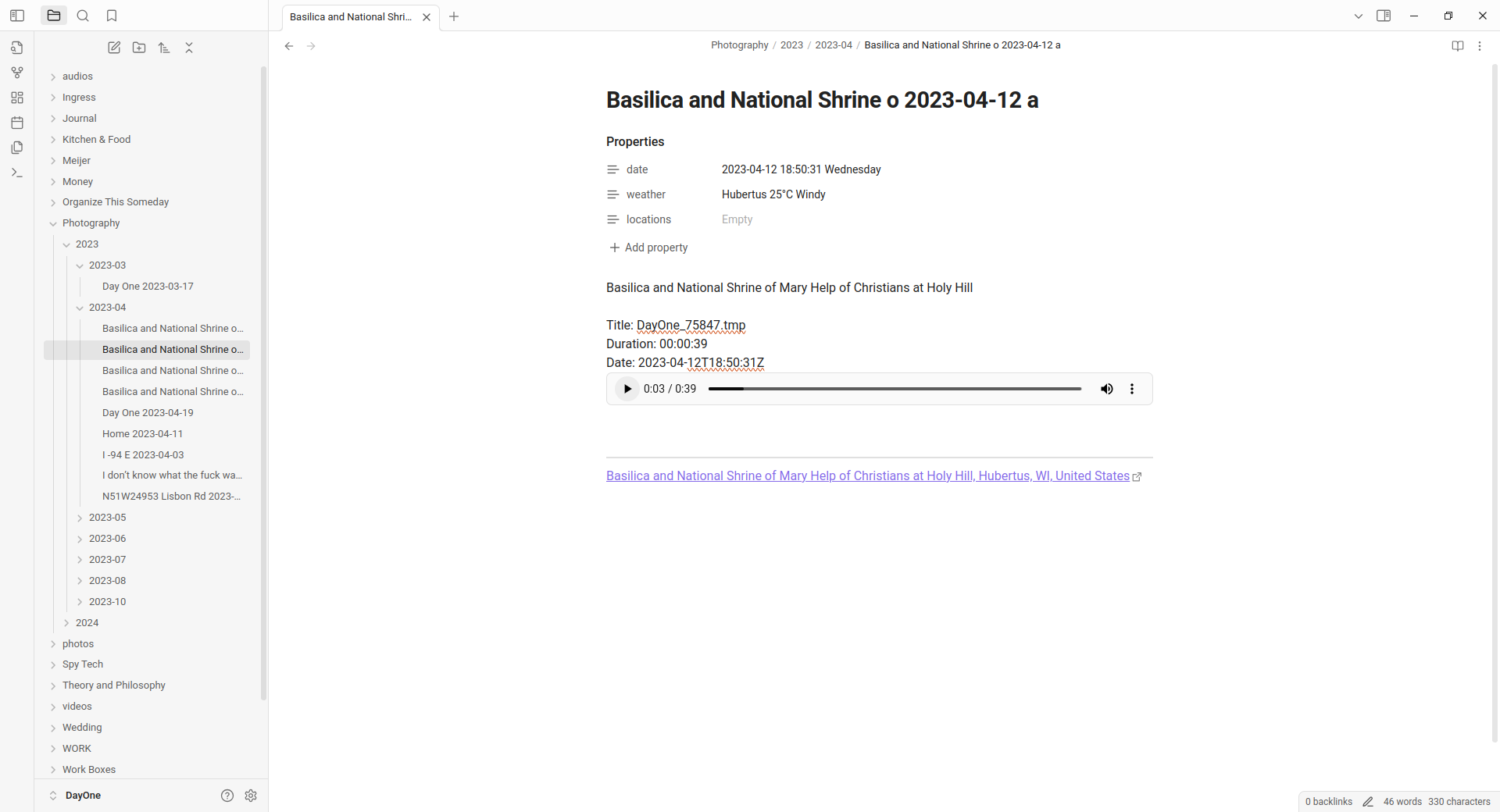
I used to be a heavy user of Day One…until I discovered Obsidian.
Based on this post from quantum gardener (DayOne to Obsidian script), I have modified the code to make it more user-friendly and added many new features. Since I have a large number of entries, I made changes to the code and file structure to handle all photos, videos, PDFs, and audios.
Changing settings in the config.yaml file is super easy.
I believe most of us are familiar with YAML because that’s what frontmatter uses
Export a few entries first to see the results before attempting to export the entire Day One. If you are comfortable with coding, you can modify the Python files to match your preferred export style.
For safety reasons, it’s best to perform the migration in a new folder rather than directly in your Obsidian vault.
If you have multiple journals like me, you can export each journal separately. This is because exporting all entries together doesn’t differentiate between journals (as there is no related attribute in the JSON).
If you have a lot of entries, the export and migration process may take a while…just grab a cup of tea and do other things.
Keep the exported JSON file. If you wish to modify the export format in the future, you can effortlessly adjust the settings and re-execute the migration process.
I love day one. But now I think Obsidian is much better.
I hope this post can be helpful to you if you also need to migrate your entries. I did manually migrate about a hundred entries. I genuinely think this is impossible. Automating the process through programming is definitely the way to go.
In your testing, how long does it take for a large number of entries? My terminal appears to be frozen while renaming image files. All the entries made it, and the terminal looks like it’s still trying to do stuff, but there’s no indication of progress.
For reference, I have somewhere around 3,800 journal entries in Day One, and about 400 photos still haven’t been renamed.
I forgot to mention my thanks for putting this together! I didn’t want you to think I was ungrateful, or that the script wasn’t useful. It performed admirably in my limited tests before I gave it the full Day One export.
I’ve included below the error I got in Terminal when I tried it a second time, obscuring the location of my home folder directory for privacy purposes:
ERROR:root:Exception: '0ADB3636474A462AA1F908ECE9174140'
ERROR:root:Traceback (most recent call last):
File "~/Obsidian/Vaults with a Purpose/2023-08-14 Day One Export Test/dayone-to-obsidian/splitfile.py", line 131, in <module>
newText = re.sub(r"(\!\[\]\(dayone-moment:\/\/)([A-F0-9]+)(\))",
File "~/opt/anaconda3/lib/python3.9/re.py", line 210, in sub
return _compile(pattern, flags).sub(repl, string, count)
File "~/Obsidian/Vaults with a Purpose/2023-08-14 Day One Export Test/dayone-to-obsidian/processor/EntryProcessor.py", line 28, in replace_entry_id_with_info
return self.get_entry_info(self.entry_dict[term.group(2)])
KeyError: '0ADB3636474A462AA1F908ECE9174140'
Hey I’m happy to help!
This line 131 aims to convert day one embedded images to markdown embedded ones.
The error message you received indicates that the key ‘0AD…’ does not exist.
Could you please check if an image with this name exists in your folder?
This issue could be due to Day One embedding an image that was not included in the export.
Another easy way to fix this is to remove this specific entry from the exported file, and see if my code works.
Please let me know if this error occurs with other entries. If so, there may be other reasons that require further investigation.
Thanks for taking a look at it this with me! I couldn’t find an image file with “0AD” in the line, so I thought I’d open the JSON in VSCode to see if I could find it there, and I got an interesting message I thought I’d share with you before I proceed:
Detected unusual line terminators
The file ‘Journal.json’ contains one or more unusual line terminator characters, like Line Separator (LS) or Paragraph Separator (PS).
It is recommended to remove them from the file. This can be configured via editor.unusualLineTerminators.
I don’t know enough about any of this stuff to know what that means, but I have safe copies of everything so I’m down to experiment. Think it could be related?
When exporting from Day One, special characters may sometimes be included in the exported data. This is already taken care of in the code, so you don’t need to worry about it.
If you cannot find an image with the name ‘0AD’, then that is likely the reason for the error. The entry requires that image, but it’s not included in the exported media. To avoid this problem, you can modify the JSON file as I mentioned in my previous post.
By the way, first make sure that the renaming process is completed as expected. The entire process could be slow if you have many entries. The process is essentially as follows: for each entry, rename its media and then convert the entry to a .md file.
Thanks again for your help. The process still gets hung up, but my Terminal doesn’t report any more errors, so I’ll continue troubleshooting on my own. It’s still a very useful script!
There seem to be some strange error? If it helps, some entries might’ve been written in UTC+3, and all the recent ones are in UTC+4. I think I could try my hand at debugging it, but it’d be nice if some known solution exists.
I also haven’t checked the exact dependencies (which I should’ve done), so I may be running on a newer pytz without knowing it. My Day One version is 2024.13 (486).
Well, weekend came and I got to fixing it. Turns out some of my older entries from 2018 didn’t have “timeZone” key for some reason! I added basically a variable for default timezone in such cases. @Luck do you accept PRs?
Thanks for sharing this. It works great except all the images and videos that were rendered inline in my Day One entries have not migrated inline in Obsidian. The files are there but not within the notes. Any idea how to fix this? Thanks
Just wanted to say that I followed the directions as listed on GitHub and everything worked very well for 14 exported Journals, clocking in at just under 3,000 entries across those journals. As mentioned the images and whatnot were exactly as the last posted user said but that did not seem to be an issue for me when I loaded the new folders directly into a new Obsidian vault.
Everything is just as it should be. Thank you very much for this great work!
Absolutely brilliant. Thank you so much for doing this. I brought over 146 entries that I had forgotten about, and truly moved everything over to one repository. Thank you!