I need a usable OCR function (similar to what I’ve used in Onenote).
Here are some requirements to make this useable:
Automatic - I don’t have to think about it, or run a command. OCR just works in the background
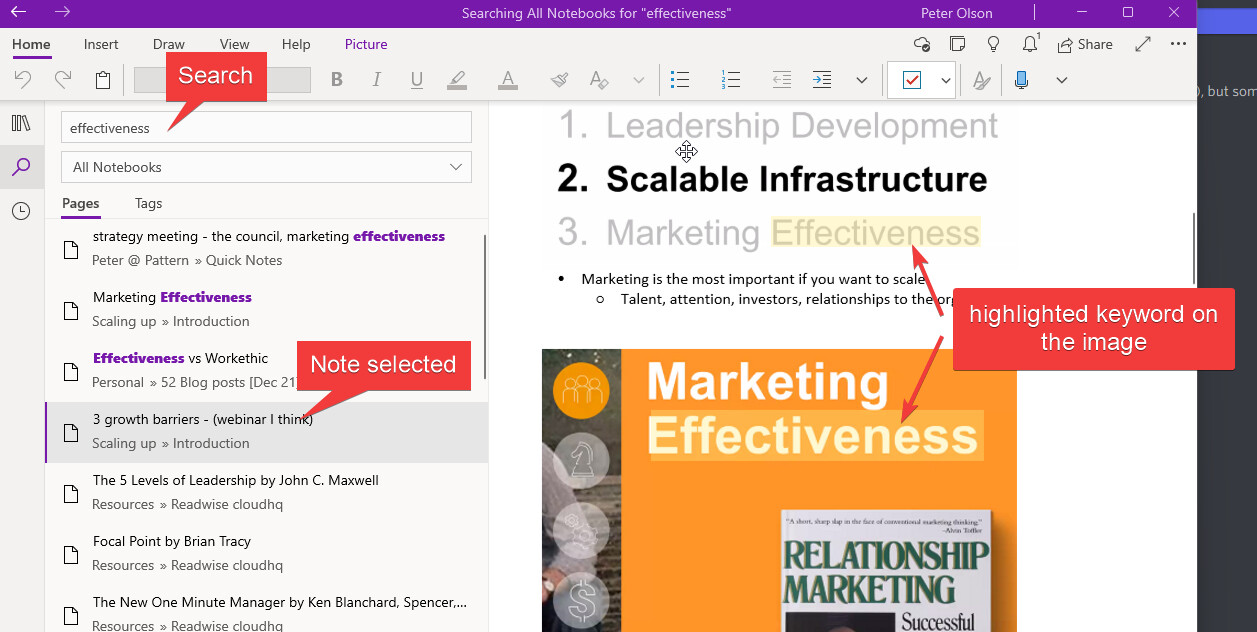
Searchable OCR to the note- The OCR works in obsidians global search and links from search lead to the note the image is ON, not the media file itself. Best use-case would be that it links to the image on the note AND highlights them. I’m not sure if its possible to highlight them, but linking (maybe with ^3agr73) should be.
Here is how onenote highlights the text in the image itself:
(optional) Handwriting OCR - Lower priority, but would help with excelidraw usage for me.
Not store a million text files - I would be nice if the OCRed text was stored somewhere other than a bunch of other vault text files (like maybe in a search index file)… or stored directly below the image like in an image alt (messy when editing), etc…
Why a another OCR thread
I realize there are many other posts and a couple other solutions out there (here and here).
I want to put my specific use case out there, gather interest, raise some funds, and get a plugin created.
If you’re interested in creating this plugin, let me know what it might cost to get created.
Extracting data in image-based PDFs: I.e. doing OCR on those pdfs.
Including PDF-data in global search
For point 1 I don’t think any new files would have to be created, the pdf itself could just be updated to include the data gathered through OCR. This is also covered in the OCR-thread you linked.
For point 2 there is already a separate request. How to best solve this I don’t know, but I agree with you - there shouldn’t be plenty of new files created.
Thanks for the feedback and ideas. I’ll be honest, PDFs to me have their own world. So for the sake of simplicity, I’m going to keep them out of my “specs” above.
Not store a million text files - I would be nice if the OCRed text was stored somewhere other than a bunch of other vault text files (like maybe in a search index file)… or stored directly below the image like in an image alt (messy when editing), etc…
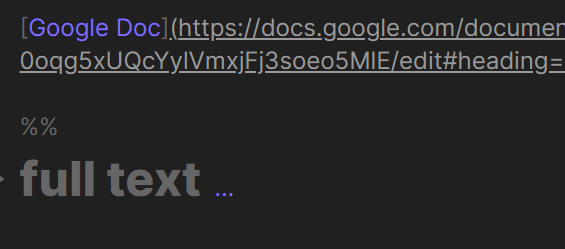
You could store the text in %% comments in the note that embeds the image.
I’m going to play with the %% comments a bit since it could also be useful to copy the contents of embedded google docs or google sheets and exposing them to the search.
Just throwing out an alternative workflow that doesn’t need a plug-in …
I threw that one OCR solution together for fun, but ultimately decided to not store PDFs in Obsidian.
Only content I write goes in Obsidian.
Reference material, PDFs, etc all go in an external tool (DEVONthink) and I just link to it from my markdown notes in Obsidian.
DEVONthink can index obsidian’s vault too so I still have a single place to search, including PDF contents.
For me, I never store PDF’s in obsidian. What I’m talking about our notes that involve screenshots (like when watching a youtube video or zoom conference). I think it would probably be a pain to put all these in an alternate note software… though doable.
You are right; it’s doable, but I don’t find it to be a pain and it’s quite usable keeping digital assets outside obsidian and textual notes and things I create inside obsidian. A plug-in could be nice for this OCR case, but it’s not necessary.
I really want this to be a thing. I take a lot of screenshots of meeting notes/diagrams/conversations and I just want to be able to find them quickly. I’m bent on using Obsidian because of the Excalidraw plugin, but image OCR is one of the things I really miss from OneNote.
I don’t know what the plugin API looks like for Obsidian, but I think embedding OCR text as a hidden comment is the easiest option - if this idea gets more traction, maybe someone could then work out how to highlight the correct part of the image
hi,
same boat as you.
i snapshot MCQs on phone,
and wanna OCR them and edit/study on obsidian.
time flies, there are already plugins like “text extractor” and “taskbone ocr”.
the latter may need paid if heavily used.
text extractor, claim to use tesseract, dont function well
but there is a STANDALONE foss called capture2text, which also use tesseract but somehow they modified and function very very well.
capture2text support CLI command line mode. e.g. capture2text -i input.jpg -o output.jpg (or to clipboard)
the only remaining thing is how to make it work smoothly instead of ocr files 1 by 1. thanks
ps: i saw someone used templater for this /w tesseract, so this may also be possible.
New user, coming over from Evernote. I have thousands and thousands of notes, mostly manuals in PDF format, that I really need to be searchable, so OCR is something I’d love to get working. How does something like this get funded and developed for Obsidian?