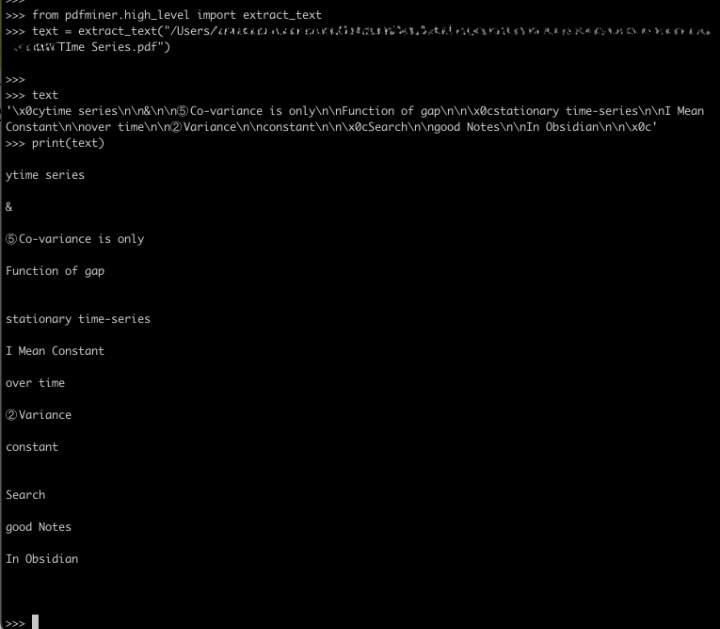
I tried pdfminer and the result is encouraging. As all the text is embedded in the PDF it was able to extract the text with quite a good accuracy. @scambier maybe text-extractor was not extracting these embedded texts but it was using tesseract to ORC the pdf, which is not very accurate. Is it possible to use these or any better API, I am ready to spend some time and contribute back.