BIG EDIT: I discovered an improvement to this method that overcomes most of the cons of the previous strategy. Look at the post history if you’d like to see the original.
This is a way to order rows in a DQL query in a pseudorandom order. To do this, we generate a pseudorandom value for each file and then sort by that value.
To generate a pseudorandom value for each file, we start with building a hash for the file, using fields that change often as inputs, for example the file modification time, file size, and the time the query was executed. Then we employ a simple generator to create a pseudorandom value between 0 and 1. We can then sort by this value to put the list in an apparently random order.
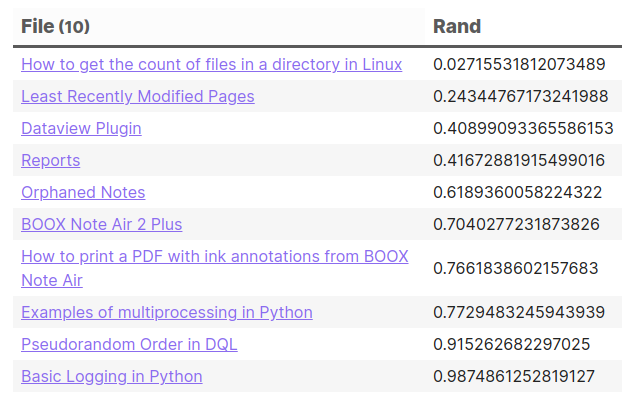
Example Query
This query shows the 10 most recently updated files in random order.
Rows sorted by this field will appear in an apparently random order. There’s no obvious relation between the random value and any one of the file’s fields.
The rows should not spontaneously re-order unless one of the files has changed.
The order of rows can be re-shuffled by reloading the page, since the time the query executed will have changed.
Cons of this method
Calculating the random value for each file could possibly be expensive if you have a lot of rows in the query.
Playing around with it a bit, I find that the order of the randomized search is profoundly biased by the variable selected in the initial SORT command. For instance if sorting by file.mtime DESC, results are heavily biased towards recently modified files; if sorting by file.size ASC, results are heavily biased towards smaller files, etc.
This can be circumvented by doing the initial sort on a less meaningful variable, like file.mtime.second.
However, I also find that when I deliberately refresh the search results, they are quite static. Refreshing from second to second does induce some changes in the results, but they are still highly constrained. For instance in a search over thousands of items in my vault, I find many if not most of the previous search results popping up again in the refreshed results, albeit in a different order each time.
Is there a way to modify the query so that when refreshing from second to second, each time is like a truly fresh uniform shuffling of the items in the search range defined by FROM and WHERE, so that the probability an item shows up in one search is roughly independent of the probability it will show up in a refreshed search seconds later?
I imagine there are ways to do that by making the hash algorithm more sensitive to values of Now.second. However I don’t understand how the algorithm works well enough to work out how to do that.
I think what you’re seeing is a consequence of the following two lines of the DQL:
SORT file.mtime DESC
LIMIT 10
Those two lines are purely to constrain the results before randomizing them, in this case they select the 10 most recently modified files in my vault. I think that’s why the results are so similar from run to run.
If you would like to see a fully randomized list with all results, remove those two lines. For example, this query will give you a table of every page in your vault in random order:
If you would like to see 10 randomly selected items from the whole list, remove those two lines and add the LIMIT 10 to the end of the query. For example, this will select 10 randomly-selected files from your whole vault:
Finally, you don’t need to include the Rand variable in the query, that is just to help see what the query is doing. Here’s a list (not a table) of 10 random pages from your vault:
```dataview
LIST
FLATTEN date(now) as Now
FLATTEN (file.mtime.year + file.mtime.hour + file.mtime.day +
file.mtime.hour + file.mtime.minute + file.mtime.second +
file.size + Now.hour + Now.minute + Now.second) * 15485863
as Hash
FLATTEN ((Hash * Hash * Hash) % 2038074743) / 2038074743 as Rand
SORT Rand
LIMIT 10
```