What I’m trying to do
As a newcomer within the Obsidian universe I am currently struggling to get my imported Journaling notes sorted chronologically. To be more specific, I have imported about 1k notes from my former journaling app (Journey). Each note has a date description as title (which I would like to use to list chronologically). However, I do not know how I could manipulate the title in such way to have them chronologically sorted in a dataview list.
Things I have tried
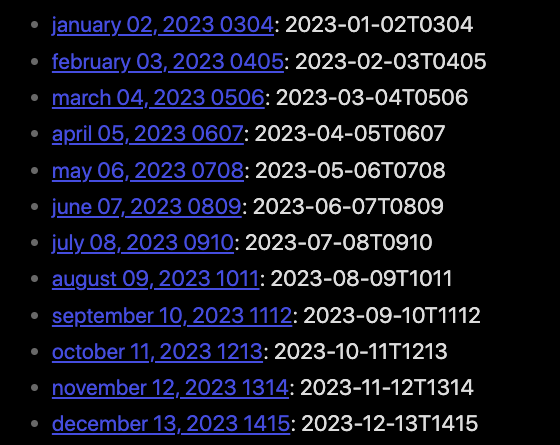
All the data was imported as one note. So far, I managed to split each journal entry by making use of Refactor plugin (on H1 title). Now I have approx. 1000 separate notes which all have a title explaining a date in the following syntax “mmmm dd, yyyy hhmm”, as an example: april 01, 2022 0746.
When I make a list in dataview, I generate the whole list but sorted alphabetically on the first letter of the month (so notes from different years get grouped). I have no clue so far how (or if) I can change automatically all titles, or use the title content in such way that they will list chronologically. As there is no metadata, alphabetically would be the way to go, but therefore I would need to change automatically all the note titles to a new synthax, for example: yyyy mm dd hhmm: 2022 04 01 0746
Your help is much appreciated!