Hello, everyone!
What I’m trying to do
I’m trying to make an OCR’d image to be foundable on Omnisearch.
Things I have tried
I’ve installed both Omnisearch and Text Extractor, activated it, waited a few minutes and searched for a string inside an image. I know it was cached because the cached filed exists:
cat 6c57a53b8882e009d012144bab0dd1bc.json
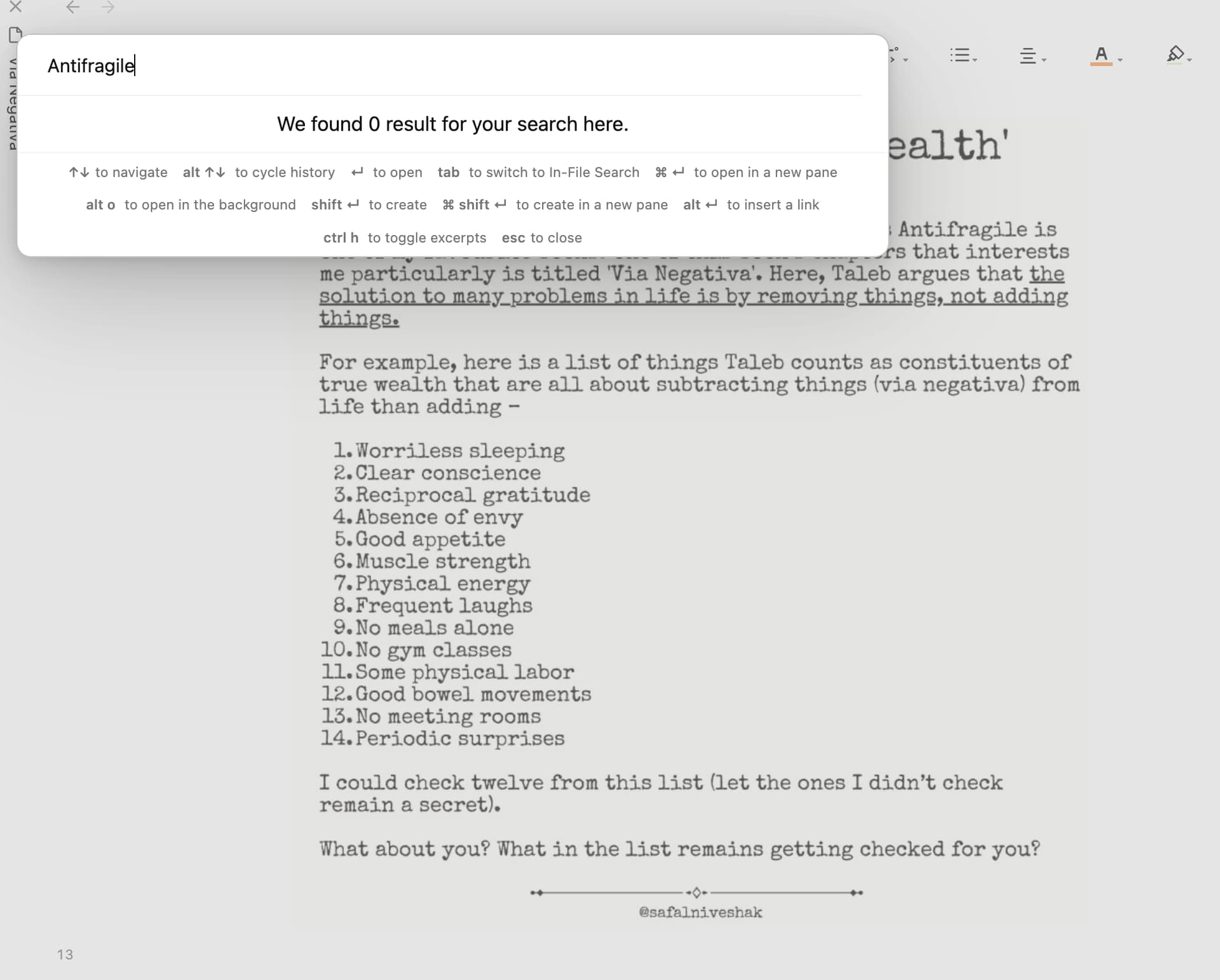
{"path":"03. Resources/Quotes/attachments/Pasted image 20240320071655.png","text":"* U ' Nassim Taleb on 'True Wealth Vishal Khandelwal. safalniveshak.com u-% . Nassim Taleb is one of my favourite authors, and his Antifragile is one of my favourite books. One of this book’s chapters that interests me particularly is titled Via Negativa'. Here, Taleb argues that the solution to many problems in life is by removing things, not adding things. For example, here is a list of things Taleb counts as constituents of true wealth that are all about subtracting things (via negativa) from life than adding - leWorriless sleeping 2.Clear conscience 3.Reciprocal gratitude 4.Absence of envy 5.Good appetite 6.Muscle strength 7.Physical energy 8.Frequent laughs 9.No meals alone 10.No gym classes 11.Some physical labor 12.Good bowel movements 13.No meeting rooms 14.Periodic surprises I could check twelve from this list (let the ones I didn’t check remain a secret). What about you? What in the list remains getting checked for you? %s @safalniveshak","libVersion":"0.3.1","langs":"eng+fra+por"}
This is the image:

But when I searched for a string that exists in the cache file, it results in nothing. Do you happen to know what could be the reason for this?
Thanks!