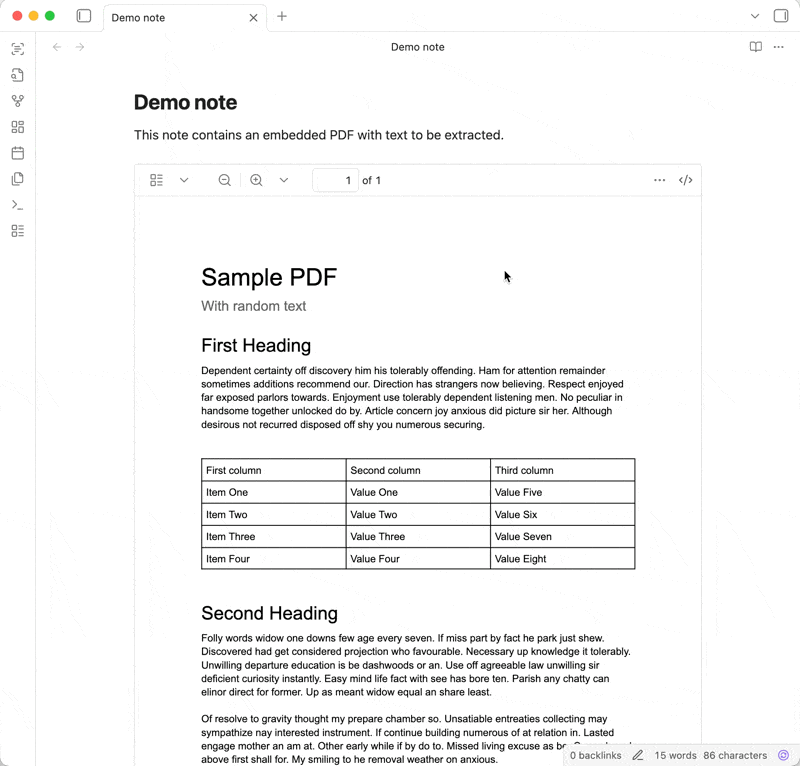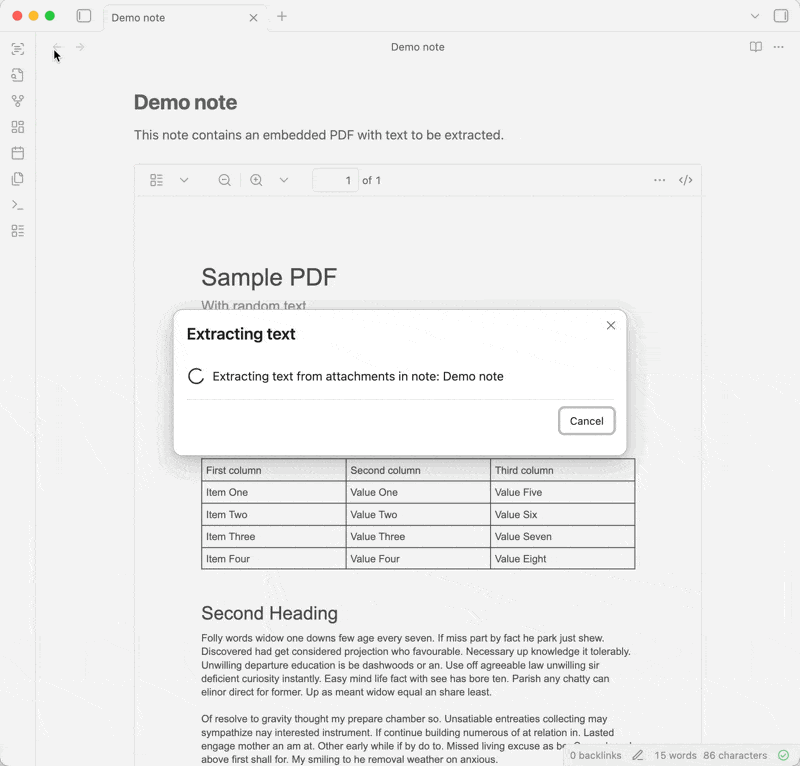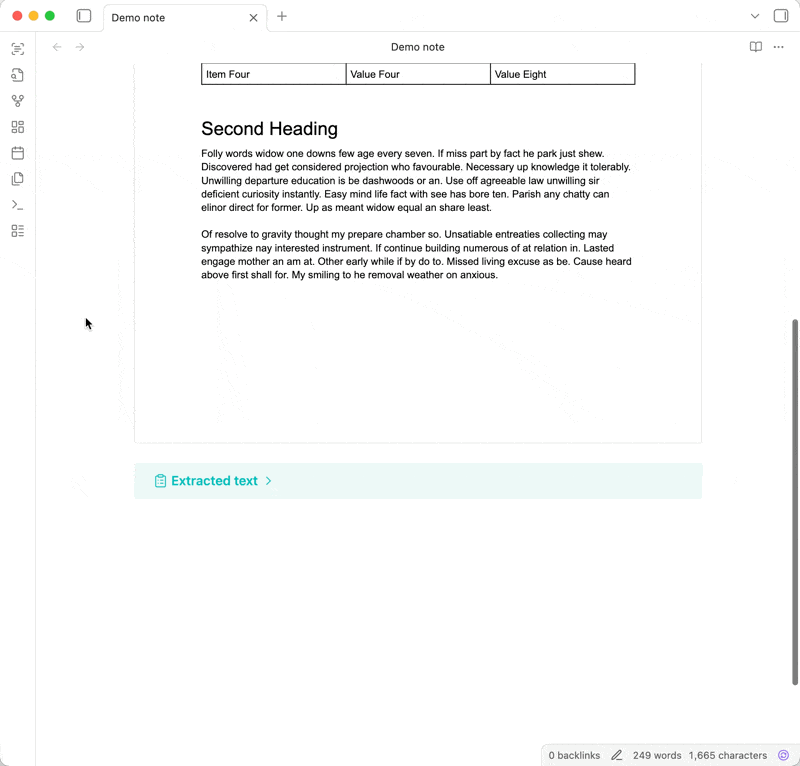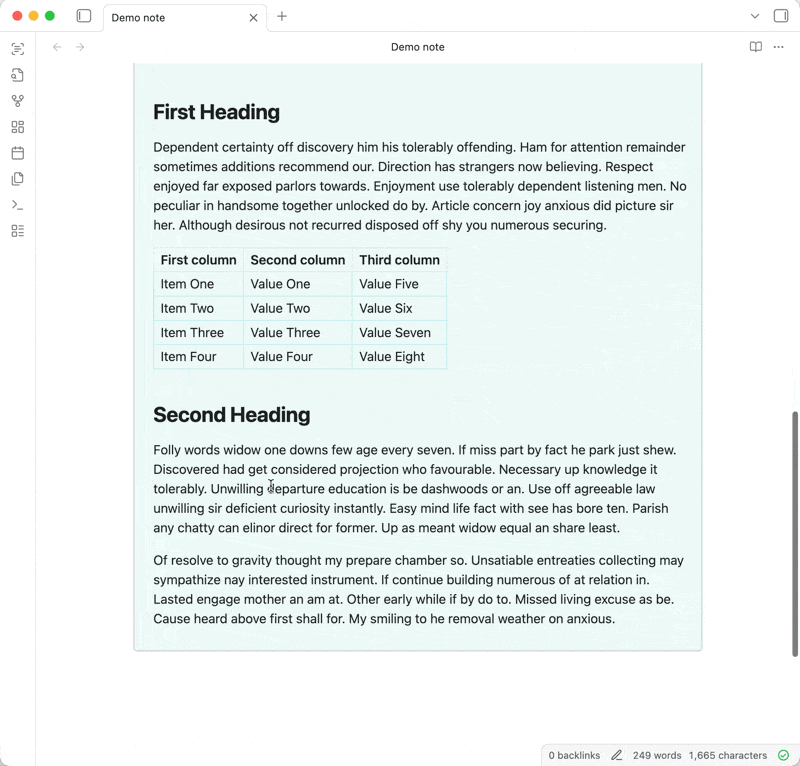
When I migrated from Evernote to Obsidian, the one feature I missed was built-in OCR to allow for easy searching within PDFs in notes. There are a few plugins currently available, but none of them were a great fit for how I use Obsidian.
So I’m happy to announce a new plugin: OCR Extractor. It uses Mistral AI’s OCR (which just released a major upgrade) to extract text from documents, images, etc. in your notes. This does require a paid Mistral account, but it’s very reasonable at a current cost of $2 per 1,000 pages processed.
Following Obsidian’s philosophy of storing data in an open, future-proof file format, the extracted text is added below the embedded attachment as an expandable callout. This means that the text will be searchable via Obsidian’s built-in search, other search plugins, and even your operating system’s native file search.
I just released version 1.2.0, which introduces support for Tesseract, a free and local OCR engine for those who prefer not to use a paid option involving a third-party service. It’s not as accurate, but it’s a great, basic option. The next step will be looking at the possibility of supporting more advanced local models.
If anyone has suggestions for models to support or features they’re interested in, let me know!
How much friction would there be if I ultimately wanted to keep ONLY the transcribed text? i.e. handwrite a note, save as PDF, extract the text, and then DELETE the original handwritten PDF and keep only the text-based note?
Good idea, that makes sense for cases where you just want to deal with text and don’t even care about the original file. The only tricky bit is deleting the original file (since it could also be embedded in other notes, and we’d wind up orphaning those embeds, although we could potentially check/warn). Is that the workflow you’re imagining?
Drag a PDF to a note to add the attachment to Obsidian and embed it in the note
Extract text into the note
The plugin would delete both the embed (the ![[file.pdf]] in the note) plus the actual attached file itself