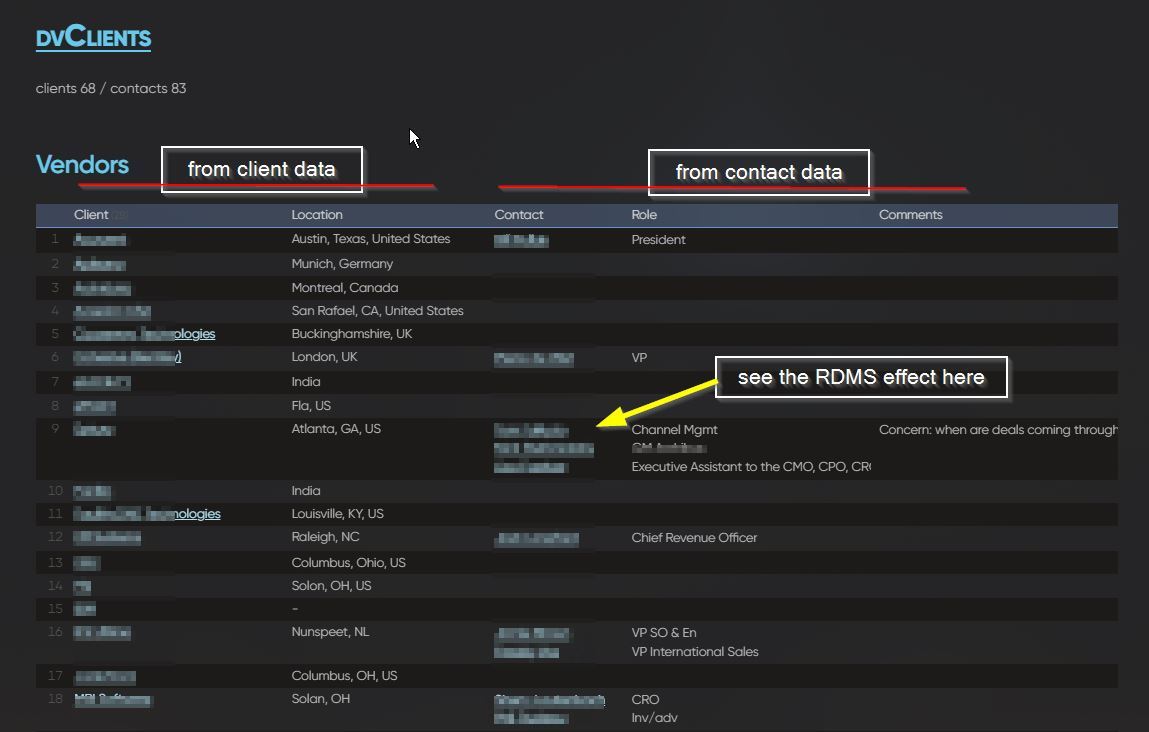
We are so very close to having some very powerful “database” like powers unlocked for Obsidian. The missing piece is transcluded properties. Right now transclusion is like a key value store that uses the filename as the key to return all contents of a file or the filename and section name to return all contents in a section or filename and block text to return a block of text in a file. The next step is to extend the “key” to include metadata/frontmatter/properties.
Let me explain.
Obsidian is surprisingly similar to a relational database (“DB”).
A DB has a primary key to identify a unique record–>Obsidian has a unique filename to identify a document. So a file name is like a primary key and a document is like a record.
Each DB record can have data with fields for the data type. → Obsidian has “properties” that are associated with each document. Properties have data of a type. So properties are like fields for a database. The field/property has a name and then there is a container for data, kinda like a key-value store. The main writing space of an Obsidian document (e.g. everything but the front matter, properties section) is just another field but it is of the type Markdown Text and is given most of the screen space. You can reference this field through transclusion using the filename as a “key” (more on this later).
In a DB, a table is a group of records that share the same fields. In Obsidian, the fileClass plugin feature and templates plugin feature enable you to enforce groupings of files that share the same properties (fields). The aggregate of these files that share the same properties are equivalent to a table.
Ok, so what.
Well one of the powerful features for both databases and obsidian is the ability to reference information in other records and files. In a relational database, this is done through a foreign key. The foreign key for any given record is simply a pointer to another record in another table and each of the fields in the other record are available through the use of the foreign key.
For example. Imagine I have a Table for PEOPLE and another table for LECTURE. I want to store data on PEOPLE and store data on LECTURE. The tables will look different and have different relevant fields. For example, the PEOPLE table might include Birthday while the LECTURE table won’t. The LECTURE table might have a field for Topic, while the PEOPLE table won’t. So it makes sense to have two tables. This model maps to Obsidian too. You can imagine a file template that has property fields for PEOPLE and a File template that has property fields for LECTURE. Each will have different fields.
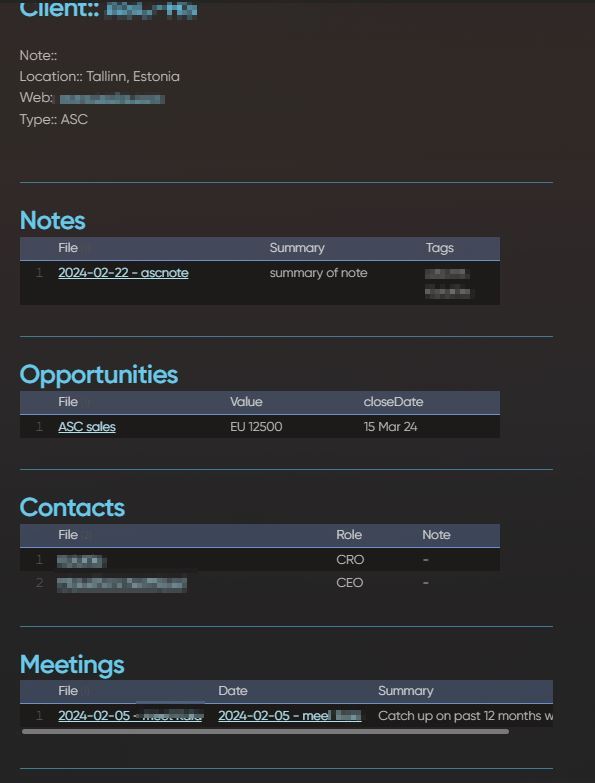
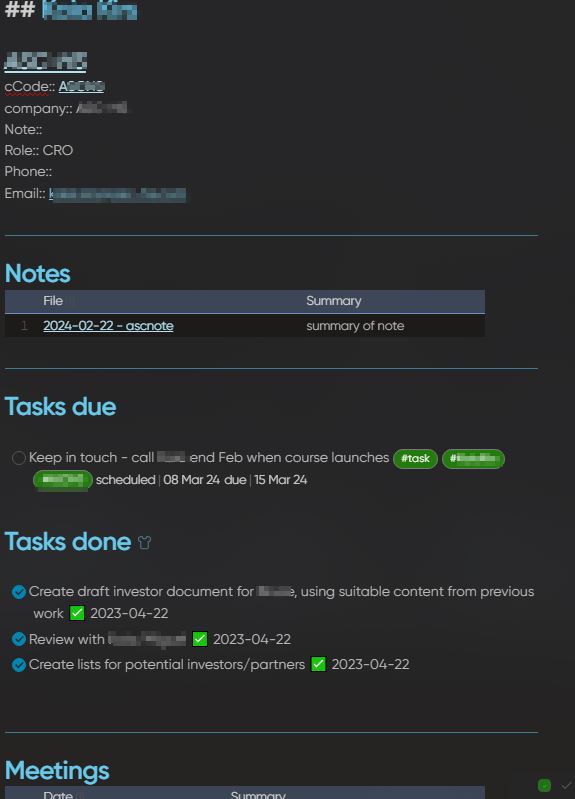
Now you might want to have a junction table that pulls fields from each table. The new table will have two foreign keys that enable you to get field data from each of the other tables. Likewise, the obsidian file of type People-Lecture will have a property field that links to people files and a property field that links to Lecture files and then the People-Lecture file can pull data from the linked files. This means if you change meta data in a people file, it propagates to the People-Lecture file. Same for Lecture data. Managing a schema in this way will avoid data duplication and outdated data.
Obsidian has a linking abilities we see in relational databases through Transclusion. Transclusion uses the filename as a “foreign key” that enables you to reach into another document to get data you bring into your existing document. However, transclusion currently only works of the main markdown rich text field that is the focal point of the document.
FEATURE REQUEST.
The feature request is to enable transclusion of a property in another file.
Right now there are three types of transclusion:
- Whole file. ![[filename]]
- Section of a file. ![[filename]#heading_name]]
- Text block of a file. ![[filename^text_block]]
My feature request is for there to be a property type called “link.” This will enable property type “lookup” and property type “rollup”
-
Property field link. ![[filename_link]]. This could be a link to a single record (File) or to multiple records (files).
-
Property field lookup. [[‘reference to properties link’, ‘select property field from referenced file’]]–>output is the data from the property field of the linked file referenced and selected.
-
Property field rollup. [[‘reference to properties link except now it is a multiselect field’, ‘apply a function to the data from the field across the referenced files’]]–>Output is the sum, or product, or concatenation of the data in the fields referenced across the various files.
For an example of an implementation, see Airtable. Airtable enables a field of type link that links to 1 or more records in another table. Then there a field for “lookup” which references the linked record (in our case file) and enables you to select a field (in our case property) from the other record and then it automagically pulls in the data for that field into the existing record (file).