This solution was developed with the indispensable help of @holroy . Thank you! I’ll buy you a coffee.
What I wanted to do
I use Obsidian to assemble documents, each with its own folder full of chapters. The documents may be work-related or personal, and I prefer to keep all my notes in one vault, so they can share information.
Each document needs a table of Abbreviations, Terms (the phrase referred to) and Definitions (the actual meanings). Rather than keep separate lists of abbreviations, I have a set of notes tagged with abbreviation, and I use Dataview to display a list of the relevant items in each document.
Example abbreviation: BM (Abbreviation) = Business Manager (Term) = Person who manages business. (Definition)
The problem was that the same Abbreviation may have multiple meanings depending on the context, and I only wanted to display the items with the relevant context. For example, BM may mean Business Manager or Bowel Movement depending on the context, and it may not be appropriate to show all meanings in one document.
Here’s how it works.
Context Notes
These can be anything: documents, organisations, projects. The abbreviation links to them as the context for a specific definition.
Term Notes
These can be any note that defines the meaning. The filename is the Term, and the field summary contains a short summary of the definition. This can then be returned by Dataview. A more complete description can be in the note body.
Abbreviation notes
Abbreviation notes have the title as the abbreviation, and are tagged with abbreviation.
(Optional) The plugin Auto Note Mover organises these into a folder.
(Optional) The plugin Metadata Menu has a “file class” which is linked to the tag, so that all the Abbreviations have the relevant fields added. This also makes it easier to add and edit the metadata.
They also have the following frontmatter (example from BM):
---
tags:
- abbreviation
contexts:
- term: "[[Terminology/Breakfast Monitor]]"
fileContexts:
- "[[Organisations/International Union of Railways]]"
- term: "[[Terminology/Bowel Movement]]"
fileContexts:
- "[[Projects/Podcasts/Coiled Spring/Podcast]]"
- "[[Abbreviations/Puerile Jokes]]"
- term: "[[Terminology/Business Manager]]"
fileContexts:
- "[[Projects/Another Project]]"
- "[[Documentation Publishing Plan]]"
---
The frontmatter consists of one or more contexts, each with a single term, and one or more fileContexts. This allows you to say: “This Abbreviation means Term X in these contexts, and Term Y in these other contexts”.
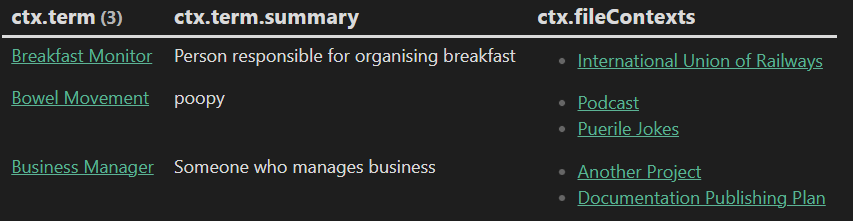
In the body of the abbreviation note you can include the following query, which displays all the terms related to this abbreviation.
```dataview
TABLE WITHOUT ID ctx.term, ctx.term.summary, ctx.fileContexts
WHERE file = this.file
FLATTEN contexts as ctx
Displays this:
I really like the idea of separating the abbreviation from the definition, because there are many cases where an abbreviation has multiple meanings. It feels more elegant and (insert the Obsidian equivalent of “pythonic” here).
In use in a document
In each document I have a note called “Terms and Abbreviations” containing a dataview query like this example for the context “Podcast”:
TABLE WITHOUT ID file.name as "Abbreviation", ctx.term as "Term", ctx.term.summary as "Summary", ctx.fileContexts as "Context"
FROM #abbreviation
FLATTEN contexts AS ctx
WHERE contains(ctx.fileContexts, [[Podcast]])
(note that “[[Podcast]]” is not in quotes in the WHERE expression)
This would show the following abbreviations in use in the context of “[[Podcast]]”:

I could even skip the column showing contexts, because we know the abbreviation is relevant to the current context, and we may not care what other contexts it’s relevant in.
Now when I create a new document requiring a Terms and Abbreviations table, I just go through and link the relevant Abbreviation notes (or create them) to the new document context.
I’m working on easier ways to add the relevant frontmatter to multiple abbreviation notes, but in the meantime this works really well.