Once again, my book database.
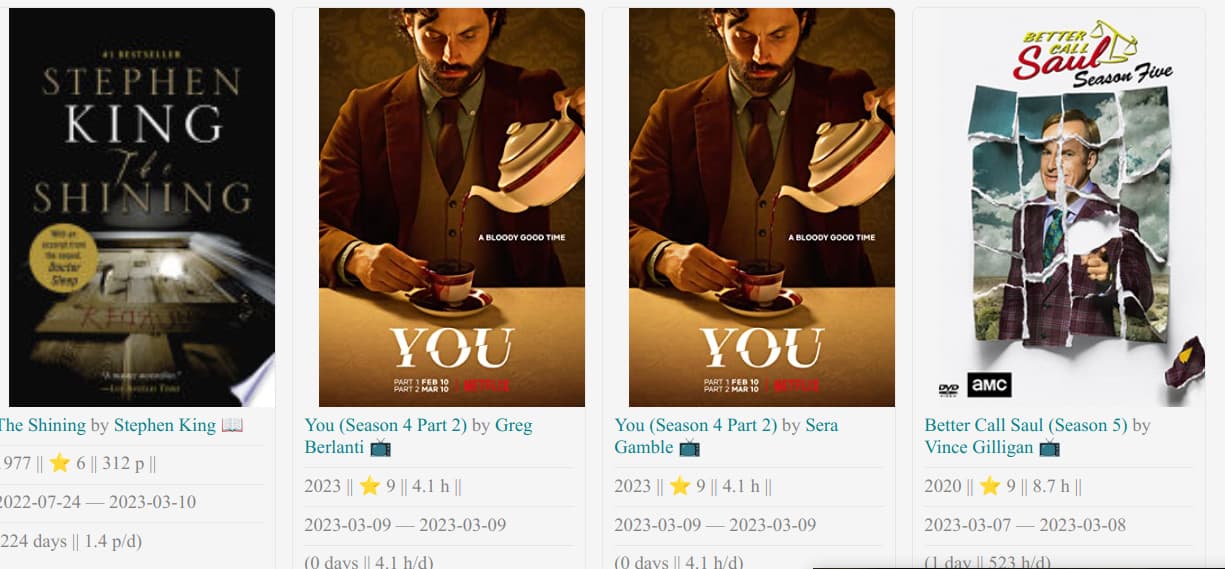
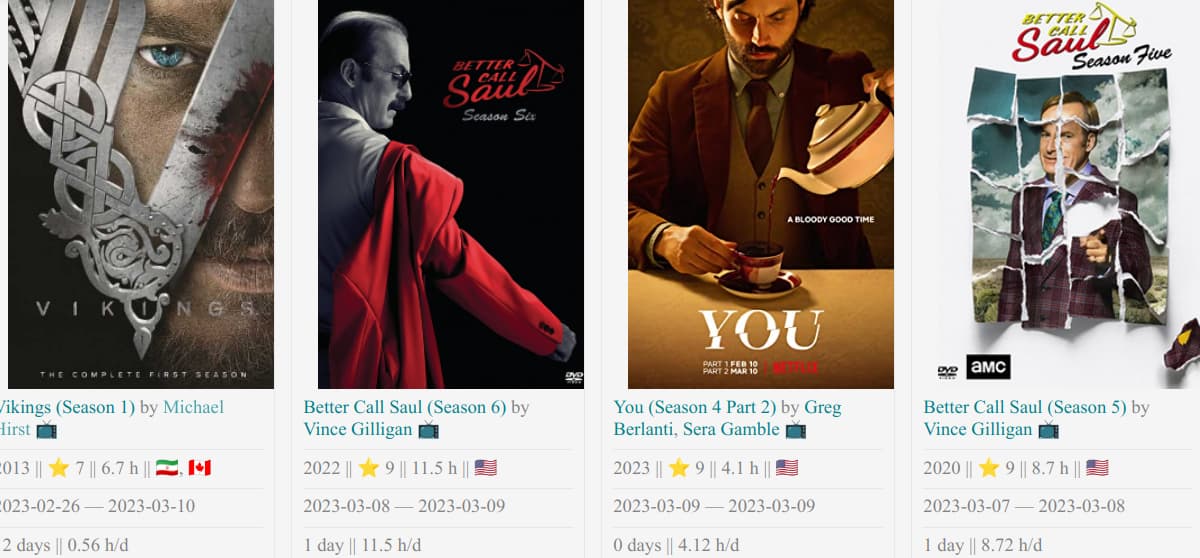
I introduced linking the book/movie notes to a country note, and in that have another Dataview Query to list all the books and movies from that country. The problem is that this seems to only work if that country value is the ONLY one in the note. So, e.g.
---
Director: "[[Gilligan, Vince|Vince Gilligan]]"
Alias: Better Call Saul (Season 4)
Actors: Bob Odenkirk, Rhea Seehorn, Jonathan Banks
Year: 2018
Medium: TV
Cover: https://upload.wikimedia.org/wikipedia/en/c/c0/Better_Call_Saul_season_4.jpg
Country: "[[United States of America|US]]"
---
works because there US is the only country.
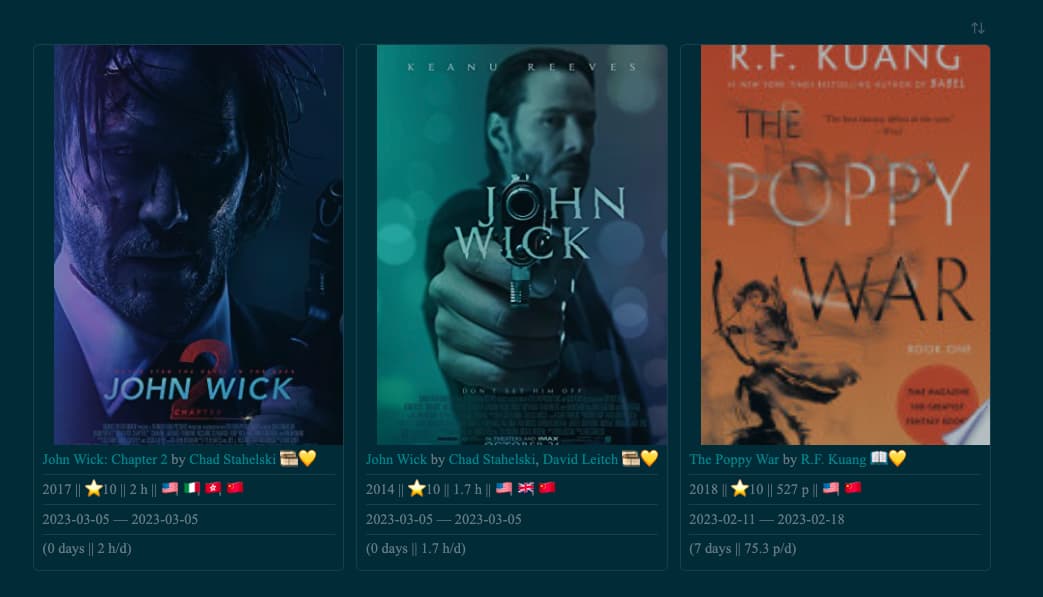
For this one it does NOT work:
---
Director:
- "[[Stahelski, Chad|Chad Stahelski]]"
- "[[Leitch, David|David Leitch]]"
Screenplay: Derek Kolstad
Alias: John Wick
Actors: Keanu Reeves, Michael Nyqvist, Alfie Allen
Year: 2014
Medium: Movie
Cover: https://m.media-amazon.com/images/M/MV5BMTU2NjA1ODgzMF5BMl5BanBnXkFtZTgwMTM2MTI4MjE@._V1_SX300.jpg
Country:
- "[[United States of America|US]]"
- "[[United Kingdom|GB]]"
- "[[China|CN]]"
---
And this is the query in the country note, e.g. in one called `United States of America:
---
Alias: US
cssClasses: cards, cards-cover, cards-2-3, table-max, max
obsidianUIMode: preview
banner: "https://upload.wikimedia.org/wikipedia/en/thumb/a/a4/Flag_of_the_United_States.svg/1200px-Flag_of_the_United_States.svg.png?20151118161041"
banner_y: 0.51205
---
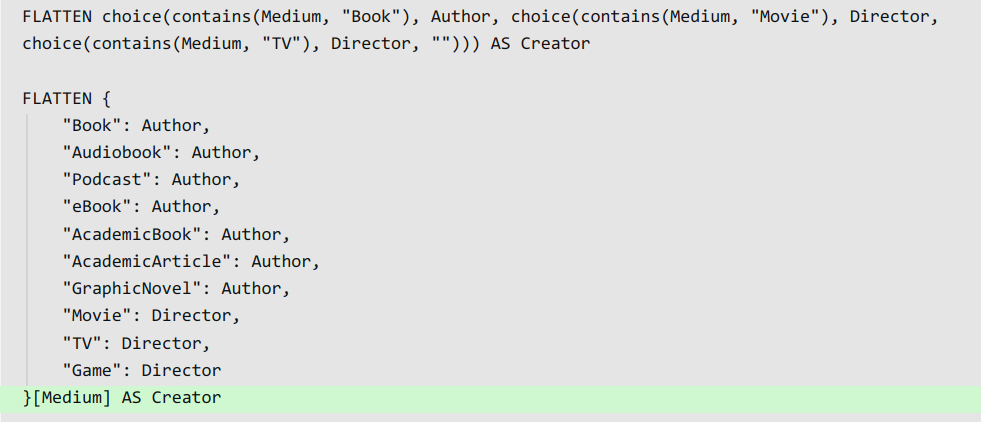
```dataview
TABLE without id
("") AS "Cover",
P_BookByAuthor + P_MediumIcon + P_FavoriteIcon AS "Title",
Q_YearRating + Q_PagesHours + " || " + Q_FLAG AS "Time and Place",
R_Dates AS "Dates",
"(" + S_ReadingTime + " || " + S_ReadingSpeed + ")" AS "Reading Time"
FROM "Book Log" OR "Y Movies and Games" OR "0 Currently Reading" OR "Set Aside"
FLATTEN {
"Book": Author,
"Audiobook": Author,
"Podcast": Author,
"eBook": Author,
"AcademicBook": Author,
"AcademicArticle": Author,
"GraphicNovel": Author,
"Movie": Director,
"TV": Director,
"Game": Director
}[Medium] AS OneAuthor
WHERE contains(meta(Country).path, this.file.path)
SORT DateFinished desc
FLATTEN link(file.link, Alias) + " by " + OneAuthor AS P_BookByAuthor
FLATTEN choice(contains(tags, "Favorite"), "💛", "") AS P_FavoriteIcon
FLATTEN {
"Book": " 📖 ",
"Audiobook": " 🎧 ",
"Podcast": " 📻 ",
"eBook": " 📃 ",
"AcademicBook": " 📚🎓 ",
"AcademicArticle": " 📰 ",
"GraphicNovel": " 💬 ",
"Movie": " 🎞️ ",
"TV": " 📺 ",
"Game": " 🎮 "
}[Medium] AS P_MediumIcon
FLATTEN DateStarted + " — " + DateFinished AS R_Dates
FLATTEN choice(((DateFinished - DateStarted).days = 1), "1 day", choice((DateFinished != DateStarted), (DateFinished - DateStarted).days + " days", "0 days" )) AS S_ReadingTime
FLATTEN DateStarted + " — " + DateFinished AS R_Dates
FLATTEN {
"Book": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"Audiobook": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 2) + " h/d",
"Podcast": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 2)+ " h/d",
"eBook": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"GraphicNovel": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"AcademicBook": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"AcademicArticle": round(choice((DateFinished = DateStarted), Length, (Length / (DateFinished - DateStarted).days)), 1) + " p/d",
"Movie": round(choice((DateFinished = DateStarted), (Length/60), ((Length/60) / (DateFinished - DateStarted).days)), 2)+ " h/d",
"TV": round(choice((DateFinished = DateStarted), (Length/60), ((Length/60) / (DateFinished - DateStarted).days)), 2)+ " h/d"
}[Medium] AS S_ReadingSpeed
FLATTEN Year + " || " + " ⭐ " + Rating + " || " AS Q_YearRating
FLATTEN {
"Book": Length + " p",
"Audiobook": Length + " h",
"Podcast": Length + " h",
"eBook": Length + " p",
"GraphicNovel": Length + " p",
"AcademicBook": Length + " p",
"AcademicArticle": Length + " p",
"Movie": round((Length/60), 1) + " h",
"TV": round((Length/60), 1) + " h",
"Game": round((Length/60), 1) + " h"
}[Medium] AS Q_PagesHours
How do I change this so that John Wick would show up in the US note even though it has multiple countries?
Thanks ![]()