Hey all! Glad you all received some value from the video 
This is what my diagram currently looks like these days:
graph TD;
A((Incoming Media))
A-->B[raindrop.io]
A-->C[Research Papers]
A-->D[Podcasts]
A-->E[Videos]
A-->F[Digital Books]
A-->G[Physical Books]
subgraph " "
B-->M1[Read & file items]
end
M1-->L6
subgraph " "
F-->L1
C-->L1[Gather papers <br>in zotero]
L1-->L2[give good meta <br>data tags]
L2-->L3[read & markup]
L3-->L4[extract with <br>zotfile]
L4-->L5[run md note on <br>extracted notes]
end
L5-->L6[put lit notes <br>into obsidian using <br>lit note templates]
subgraph " "
D-->N0{Listening <br>on the go?}
N0--Y-->NN[grab Airr quotes]
NN-->NN0[Caption them <br>with thoughts]
NN0-->NN1[Export <br>to Markdown <br>with transcript]
NN1-->NN2[Airdrop <br>to computer]
NN2-->NN3{only a <br>single quote?}
NN3--Y-->NNN1[use Airr <br>page template]
NN3--N-->NNN2[put quotes and <br>links into podcast <br>template, no embedd]
N0--N-->N1[put podcast player <br>into obsidian note]
N1-->N2[2 copies of note open <br>listen and noteate]
end
NNN1-->L6
NNN2-->L6
N2-->L6
subgraph " "
E-->O1[watch and notate <br>with Yinote]
O1-->O2[get output from <br>google drive]
O2-->O3[clean output]
end
O3-->L6
subgraph " "
G-->P1[read and hand <br>write notes]
P1-->P2{Lengthy <br>or<br> Complex?}
P2--Y-->Q1[Transcribe <br>each chapter]
P2--N-->Q2[Transcribe <br>whole batch]
end
Q1-->L6
Q2-->L6
%% The final obsidian note generation workflow:
L6-->L7[Lit notes into seedbox]
L7-->L8[Review lit notes <br>and generate seedlings]
L8-->L9[Incubate seedlings <br>with thought <br>and linking]
L9-->L10>Plant seedlings <br>into Evergreen forest]
you also may find some of the mermaid.js code in my map of moc interesting for future diagraming/refactoring your workflow diagrams i might need to re-look at my own 
graph RL;
%%==============%%
%% Declarations %%
%%==============%%
A[INDEX]
click A INDEX;
B[Interests]
click B Interests;
C[Statistics]
click C Statistics;
D[Programming]
click D Programming;
E[Vim]
click E Vim;
F[Bash]
click F Bash;
G[Python]
click G Python;
H[R]
click H R;
I[C++]
click I "C++";
J[LaTeX]
click J LaTeX;
K[Groff]
click K Groff;
L[Business]
click L Business;
M[YouTube]
click M YouTube;
N[PKM]
click N PKM;
O[Religion]
click O Religion;
P[Heathenism]
click P Heathenism;
Q[T-SQL]
click Q T-SQL;
R[Markdown]
click R Markdown;
S[Twitch]
click S Twitch;
T[Twitter]
click T Twitter;
U[Zettelkasten]
click U Zettelkasten;
V[Spaced Repetition]
click V "Spaced Repetition";
W[Technology]
click W Technology;
X[GitHub]
click X GitHub;
Y[JavaScript]
click Y JavaScript;
Z[Web Development]
click Z "Web Development";
A1[CSS]
click A1 CSS;
B1[HTML]
click B1 HTML;
C1[Academia]
click C1 Academia;
D1[School]
click D1 School;
class A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z internal-link;
class A1,B1,C1,D1 internal-link;
%%=========%%
%% Linking %%
%%=========%%
%% Index
A --> B & L & N & O & C1 & D1
%% Business
L --> M & S & T
%% Interests
B --> C & D & W
%% Programming
D --> F & G & H & I & J & K & Q & R & Z
%% Web Development
Z --> Y & A1 & B1
%% Technology
W --> E & X
%% PKM
N --> U & V
%% Religion
O --> P
cheers!

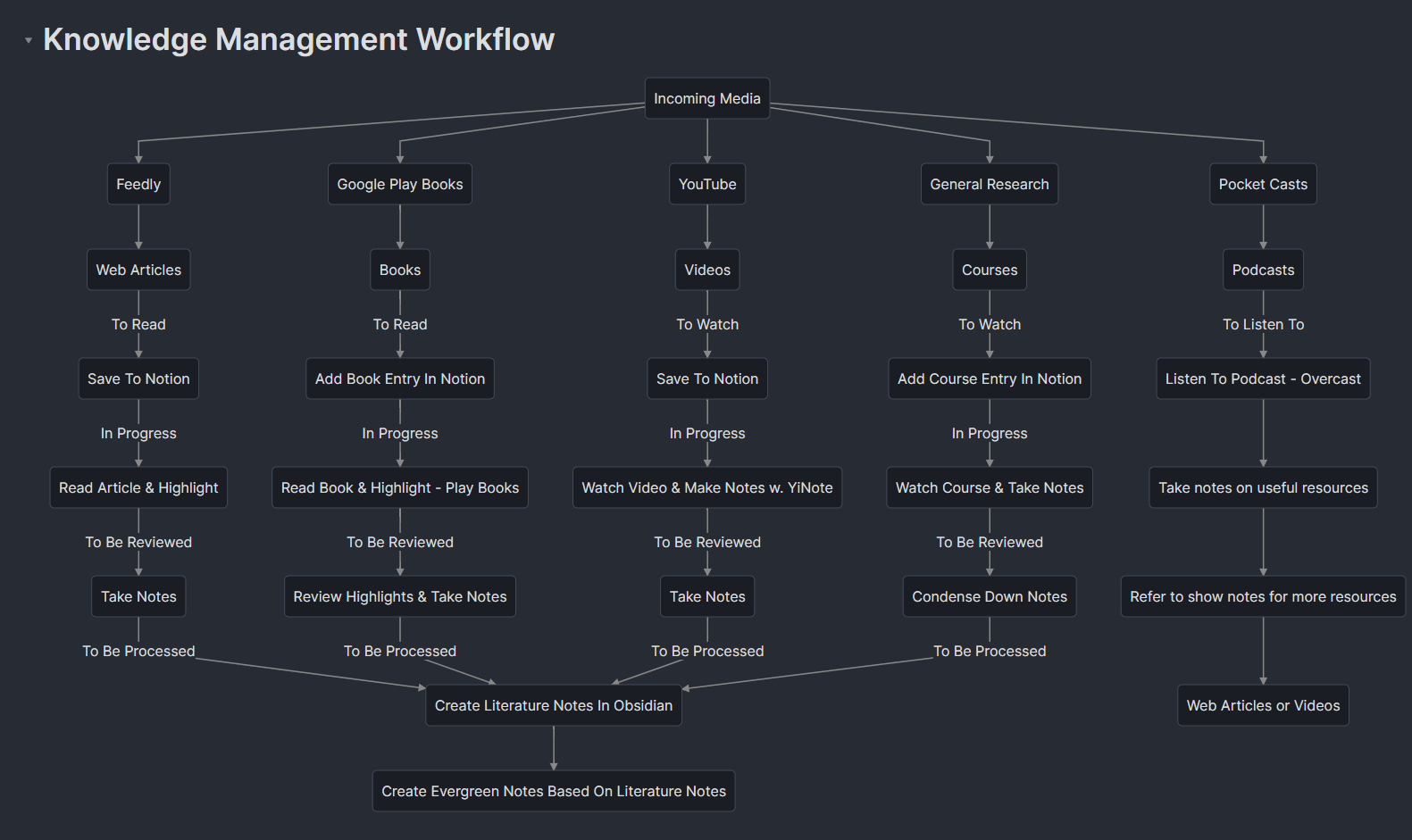
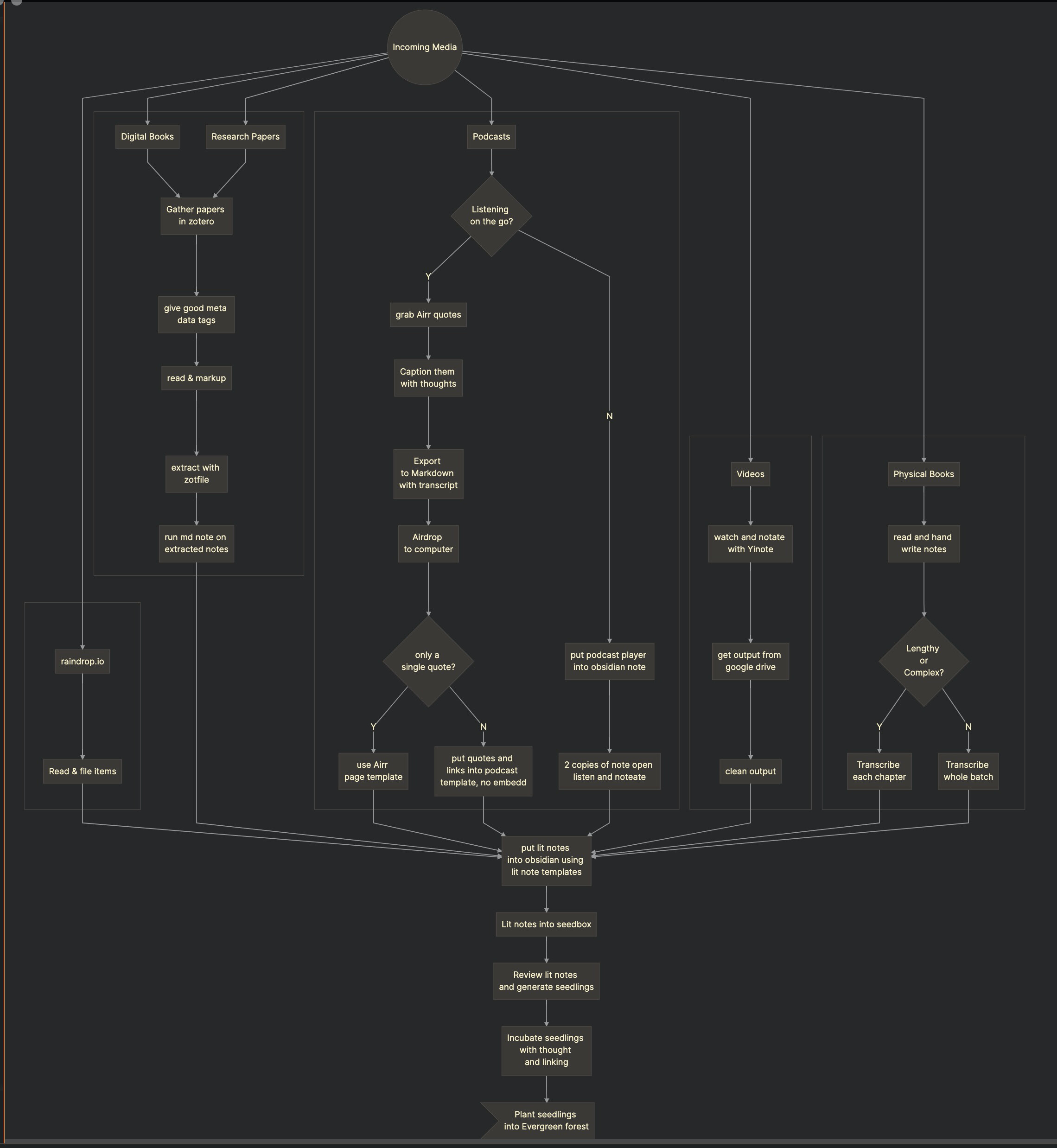
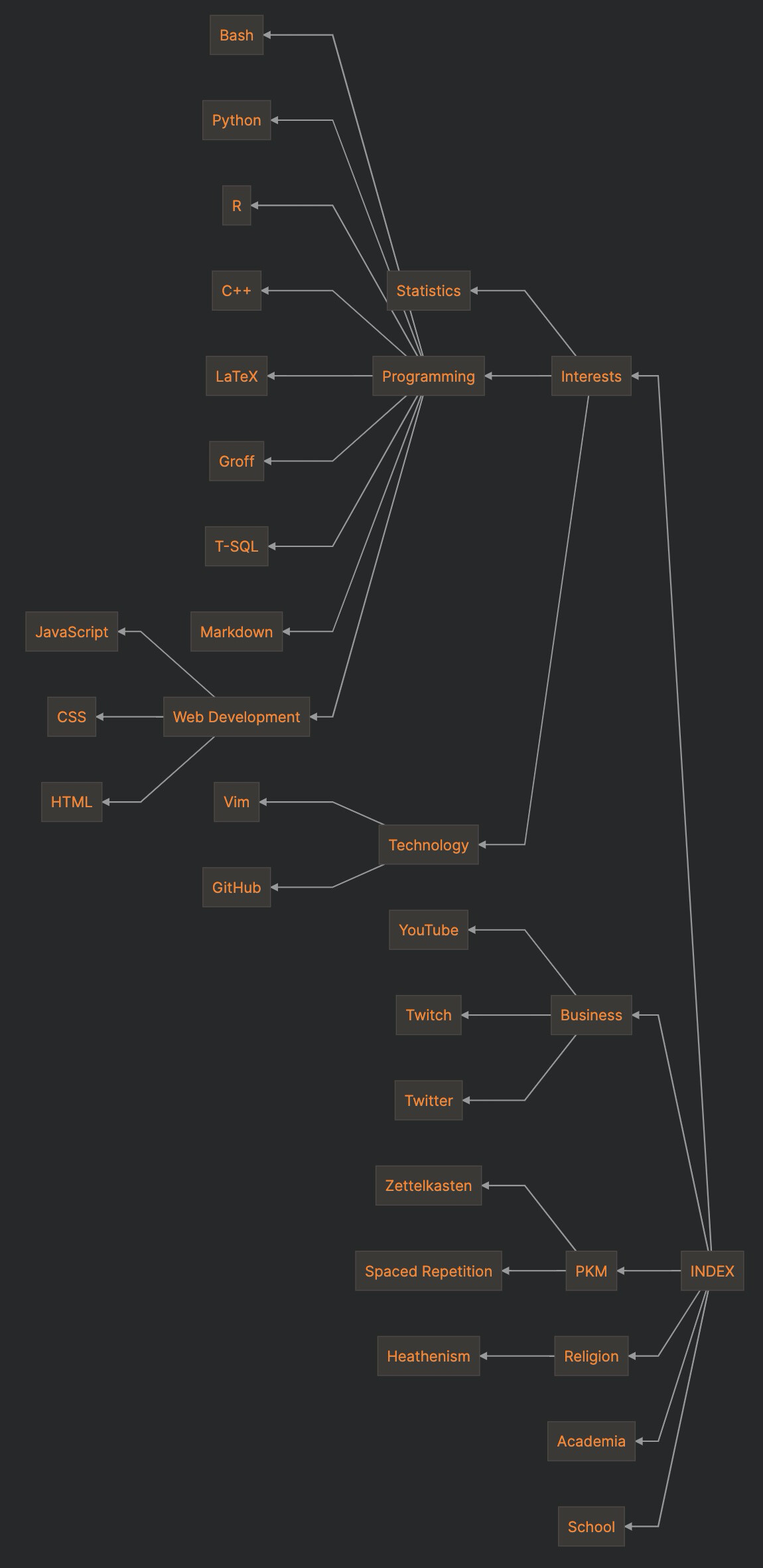


 subgraphs seem quite useful too.
subgraphs seem quite useful too.