Sorry for the confusing title! What I’m trying to do is set up some standard files with Dataview queries that I can reuse in various situations by embedding them in other notes. The reason for this is that if I decide to change something about the dataview query, I can do it in one spot and it’s uniformly reflected anytime the “embedding” notes are viewed since they would access the new query. Otherwise, I’d have to go change those dataview blocks in all the notes.
For example, I have a note that compiles information from files that reference that specific note as one of their properties:
File_1
Category:: [[name-of-a-category-note]]
Title:: Text
Author:: [[@author-name]]
File_2
Category:: [[name-of-a-category-note]]
Title:: Text
Author:: [[@author-name]]
And in:
Name-of-a-category-note File
TABLE WITHOUT ID
file.link as Reference, Title, Author
FROM "03. references"
WHERE category = this.file.link
Sort author
This works fine, but I wanted to put the Dataview block in a separate file and simply embed it in every Category-file. But I don’t know how to tell the Dataview block in the embedded file how to use the “embedding” file link.
Obviously new to Obsidian (and markdown) so was trying to figure out a way without also having to learn JS which I think might provide more coding flexibility.
Things I have tried
I’ve searched help files, web , discord, and the forum looking for ways for an embedded file to access variables from a ‘calling’ or ‘embedding’ note. Can’t find any. Some indication javascript may be more helpful but don’t know anything about JS. Also started to look into Backlinks, but only seem to find options to see them in a side panel or embed them in the current note. Even if I could access the list of backlinks, I don’t know how to tell which one would be the ‘calliing’ link for a particular instance.
This is but one example of what I’m trying to do. I have a number of different use cases I can see for this if there is a straightforward implementation.
After a very quick read through I believe you should look into dv.view(). They can give you the opportunity to have a general query, which can adapt to local settings, or parameters passed in to the call of the dv.view().
I’m using this approach to build a header section to most of the files in my personal vault. This allows me to change the header globally by changing the script.
And even though some coding needs to be done, it’s rather easy to make a boilerplate allowing you to run ordinary queries.
Come to think of it, you might possibly also run a boilerplate dataviewjs script doing dv.execute() after reading its query from a file. This was done in a forum post not too long ago.
Thanks @holroy, this will probably work but will require some learning about Javascript for the scripts I’d need to create. Unless there is another way to do what I’ve described, I’ll have to look into javascript implementation of the called scripts when I have more time - I’m still learning a lot about Obsidian that I think I need to get a handle on first and was hoping there was something within Obsidian allowing an embedded file to know which file (“Page?”) called it and could access Properties of that original file.
To keep it as simple as possible I’d put the query, and just the query alone into a file. In my test example I put this text into a file called “t75298”:
TABLE length(file.tasks)
WHERE length(file.tasks) > this.taskLimit
LIMIT 10
Here you see I’m referencing a local field this.taskLimit, so in my test note I had the following:
---
Tags: f75298
taskLimit: 10
---
questionUrl:: http://forum.obsidian.md/t//75298
## Within this file
```dataview
TABLE length(file.tasks)
WHERE length(file.tasks) > this.taskLimit
LIMIT 10
```
## From another file
```dataviewjs
const query = await dv.io.load(dv.page("t75298").file.path)
const result = await dv.query(query)
dv.table(result.value.headers, result.value.values)
```
Both queries produced the same result. I think the latter query is the easiest way for you to have your query in another file. And you could just copy this section into whatever file you’d want, and change the file holding the query. In the example you could now change the taskLimit and the query will reflect that new value.
The only time you’d want to change it up a little is if you’re doing a LIST or TASK query, where you’d respectively would exchange just the last line with either of the following:
Actually, spoke too soon. I’m having a bit of trouble getting what I expected with the file calling the query. The first test with the single file and query by itself works fine.
t75298
Tags: f75298
taskLimit: 10
TABLE length(file.tasks)
WHERE length(file.tasks) > this.taskLimit
LIMIT 10
Evaluation Error: TypeError: Cannot read properties of undefined (reading ‘headers’)
at eval (eval at (plugin:dataview), :3:23)
at async DataviewJSRenderer.render (plugin:dataview:18670:13)
I don’t really know enough JS to solve further though I tried to find a clue elsewhere. I did verify that the first two lines don’t throw an error if I leave out the third line, but apparently they aren’t giving a good result const back for dv.table. Maybe something wrong with my setup but not sure. Both files are in the root folder of my vault.
The part you quoted is supposed to go in the file where you wanted to do the embed, and the query should go in the file I named “t72598” but which you can name whatever you want.
What is your query, and what’s the file names of the various files in question?
Yes the file “embed-t75293” is meant to be the file calling the query file t75293 containing the query. I used the query you had in your example as I wanted to replicate exactly what you had done in your testing before trying anything else.
Query file: t75293
Tags: t75298
taskLimit: 10
TABLE length(file.tasks)
WHERE length(file.tasks) > this.taskLimit
LIMIT 10
Hmmm… it’s kind of hard to understand what’s happening at your end here, but you could try this extended version of the query, and report back what error messages it gives:
If there was an execution error in the script this should report it back. You could afterwards, also try to uncomment (aka remove the //) to check that you actually get the query you’re supposed to get.
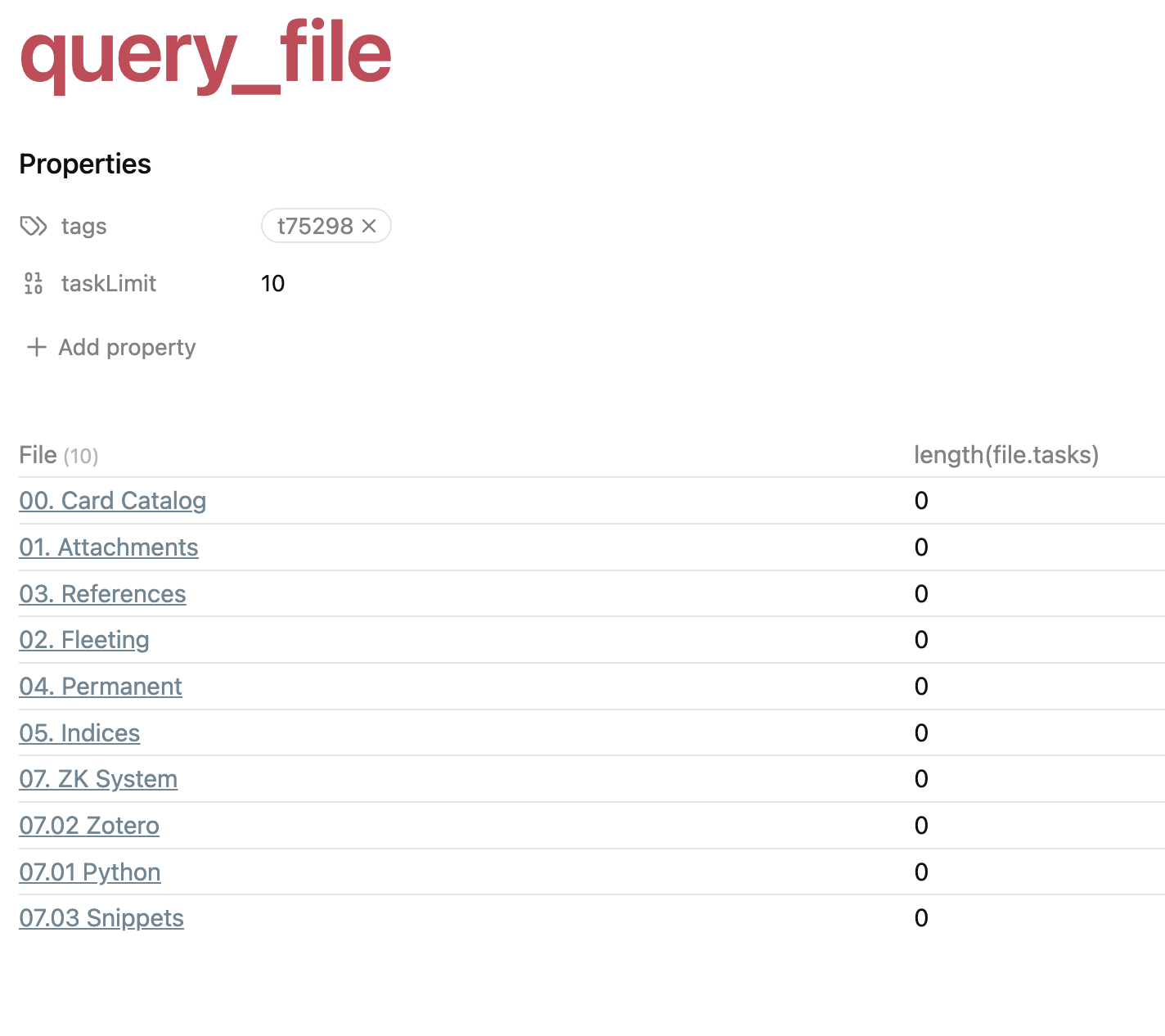
yes it was a typo here. Still decided to change the names of the files to “query_file.md” and “call_query_file.md” to make it clearer (and of course changed the query filename in the code block). Same result.
And the result of the query_file by itself (so you can see it worked without the call). Note this directory has only files with no tasks which is why they are all zero.
You original request was to be able to set the query parameters from the file doing the embedding, which translates to the “calling query” file. Isn’t that the entire point of this exercise?