Okay, original text:
...some text is here on and on, yada yada, still going on
Page 149
YADA YADAW - IT'S YADA YADA TIME, BABY
and now we're going to the next page.
Yada yada, on and on...
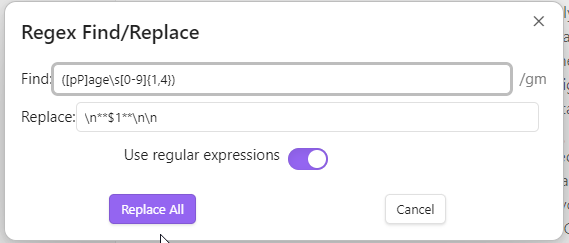
- Capture Page with number with:
([pP]age\s[0-9]{1,4}) (assuming we can have page with a small p as well, but it can be removed from the brackets)
Replace with: \n**$1**\n (here the last \n can be removed if needed)
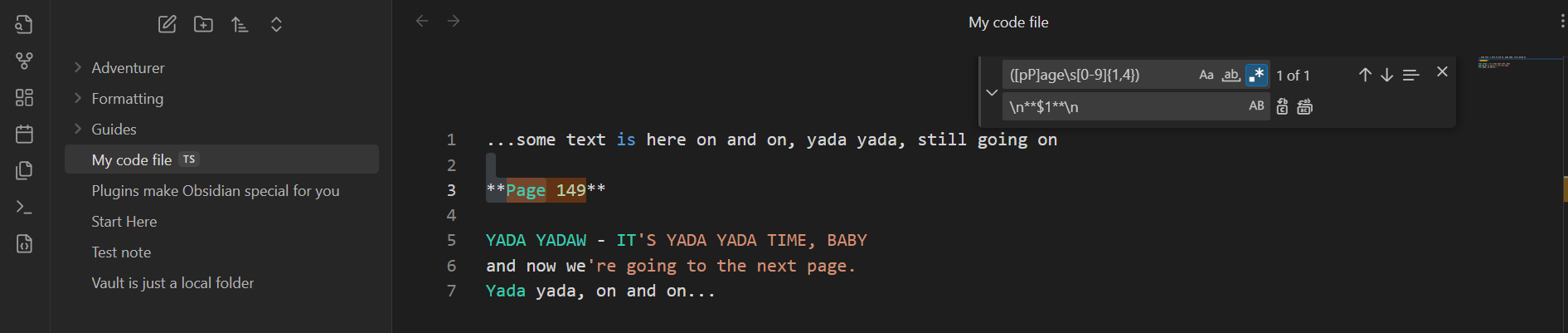
Result:
...some text is here on and on, yada yada, still going on
**Page 149**
YADA YADAW - IT'S YADA YADA TIME, BABY
and now we're going to the next page.
Yada yada, on and on, until the break of dawn...
There have been some tutorials (I find one of them now here) put up here on the forum in the past how to handle text pasted into txt/md files and how to remove line breaks and trailing spaces, and there the Apply Patterns plugin is mentioned. But you can manipulate text outside of Obsidian with a regex-capable text editor of your choice (be it Notepad++, Sublime Text, VS Code, etc.).
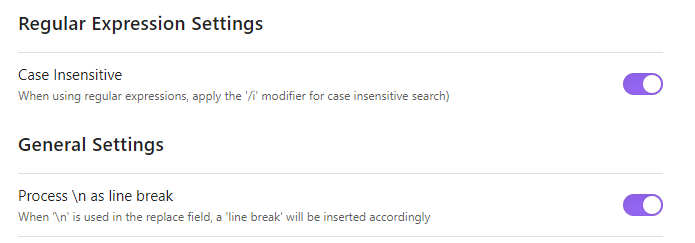
If you condense your texts with the method mentioned in the post, then you’d need to use for replacement \n\n**$1**\n\n as the final step.
Explanation of regular expression:
[pP] - chararcter class within square brackets means we allow only small and large p’s here
\s - whitespace character
[0-9]{1,4} - numbers from 0-9999
\n - new line character
$1 - backreference for what we’ve put in round brackets: the whole of ([pP]age\s[0-9]{1,4})
If there are no Page string in your texts, it’s tricky and well nigh impossible, as we cannot differentiate between any numbers relating to counting, dates (e.g. 234 years ago, 50 cows, etc.). Then some robot can be prompted to clean up text based on language model data. E.g. Copilot plugin can be used with free Google Gemini.