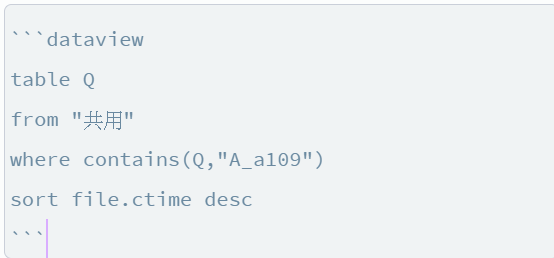
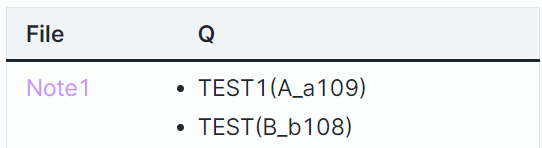
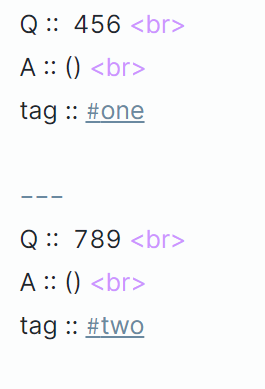
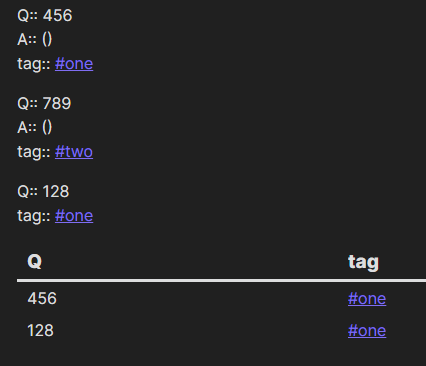
So you have several Q:: and tags:: in several files? Can each file contain this data repeated several times?
I prepared two files, one called “Test1” and the other called “Test2” containing the following:
# This is test1
Q:: 1111
A:: ()
tag:: #one
Q:: 1112
A:: ()
tag:: #two
Q:: 1113
tag:: #one
# This is test2
Q:: 2221
tag:: #three
Q:: 2222
tag:: #one
Q:: 2223
tag:: #two
Q:: 2224
tag:: #one
And prepared in a third file the following dataviewjs:
tag_to_filter:: one
```dataviewjs
// utility function
let transpose = m => m[0].map((x,i) => m.map(x => x[i]));
// Variable for storing results to show
let all_results = []
// Get all notes from all files (change "" to a folder if required)
// and group the data by file, keeping only those which have a Q property
let files = dv.pages('""').groupBy(p=>p.file).filter(g => g.rows.Q.length);
// For each file, process the found data
for (let group of files) {
let p = group.rows;
// Get all Qs and all tags, paired by index,
// and keep only those with tag "one"
let Qs = p.Q
let tags = p.tag
// Temporally assign empty string to filename
let filenames = new Array(Qs.length).fill("");
// Build a sub-table for this file
let result = transpose([filenames, Qs, tags])
// Keep only the rows for which the tag contains "one"
result = result.filter(x=>x[2] && x[2].contains(dv.current().tag_to_filter))
// Now assign the filename to the first row of the subtable
result[0][0] = group.key.link;
// And store the subtable in the global variable
all_results.push(...result)
}
// Show all the sutables in a sigle table
dv.table(["File", "Q", "tag"], all_results)
```
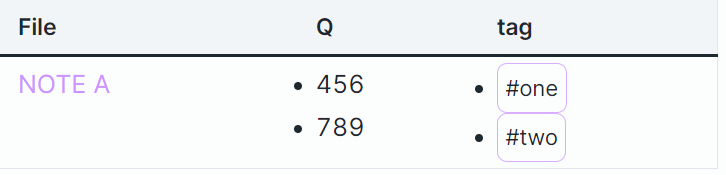
When run, it produces the following table:
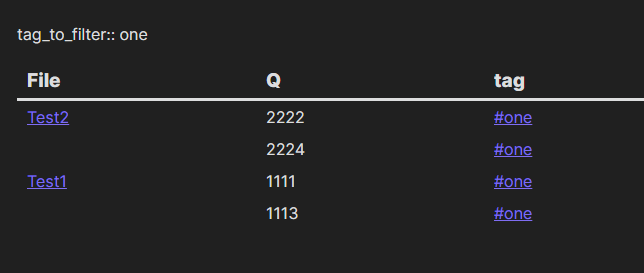
is this what you wanted? The table shows the file names (to avoid repetition, only the first row for each file shows the name and link, rows below those refer to the same file), the values of Q and the tag being filtered. You can change which tag is filtered by editing the field tag_to_filter::.
Still, I think the approach is brittle, and I’m not very proud of the code… Comments are welcome.