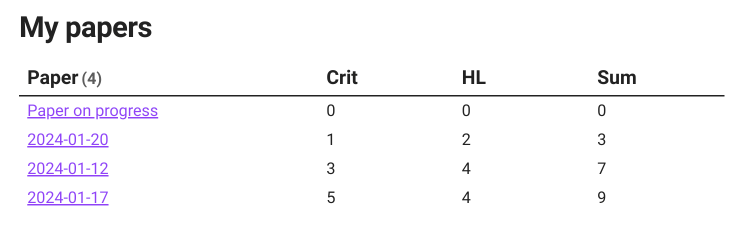
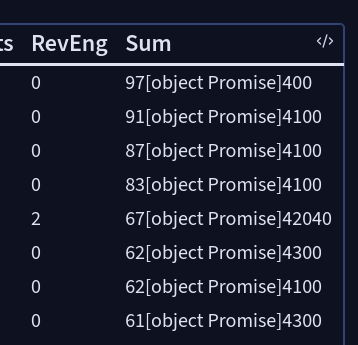
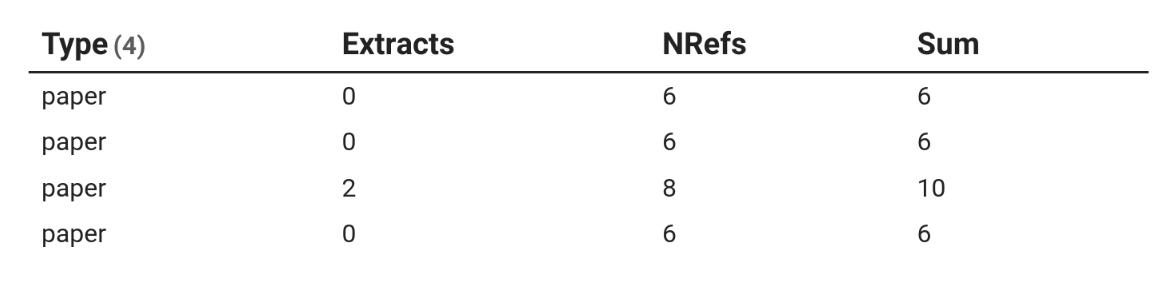
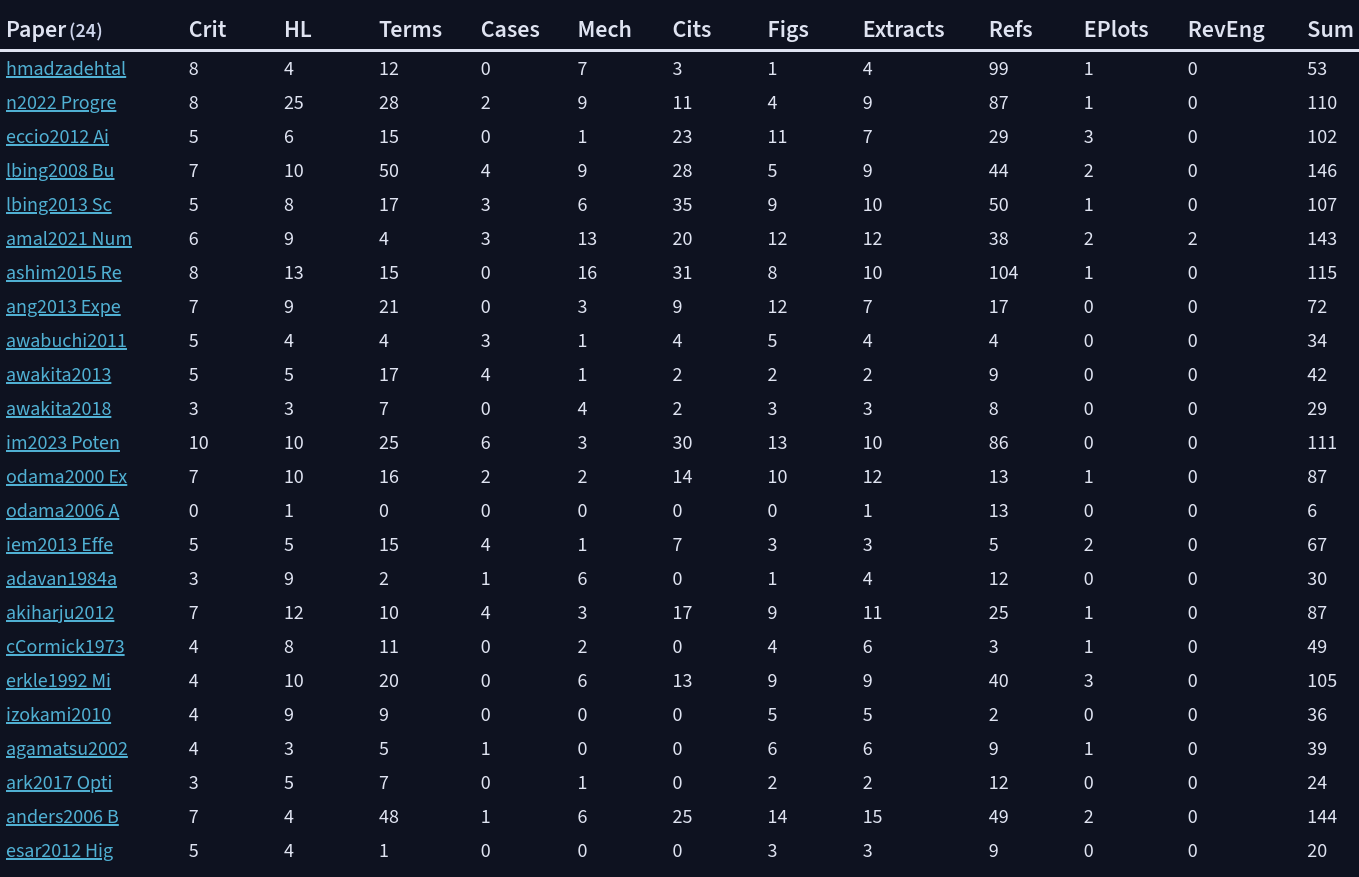
I have a collection of papers that I have summarized by the number of lines (NL) of the critique, highlights; the number of property-pairs for terminology, field cases, physical mechanisms, citations; number of figures attached to the source note of the paper; number of extractions entered as callouts; number of references per paper in their own reference note; number of essential plots; and number of reverse engineering calculations performed on some papers. This all make a summary table like this:
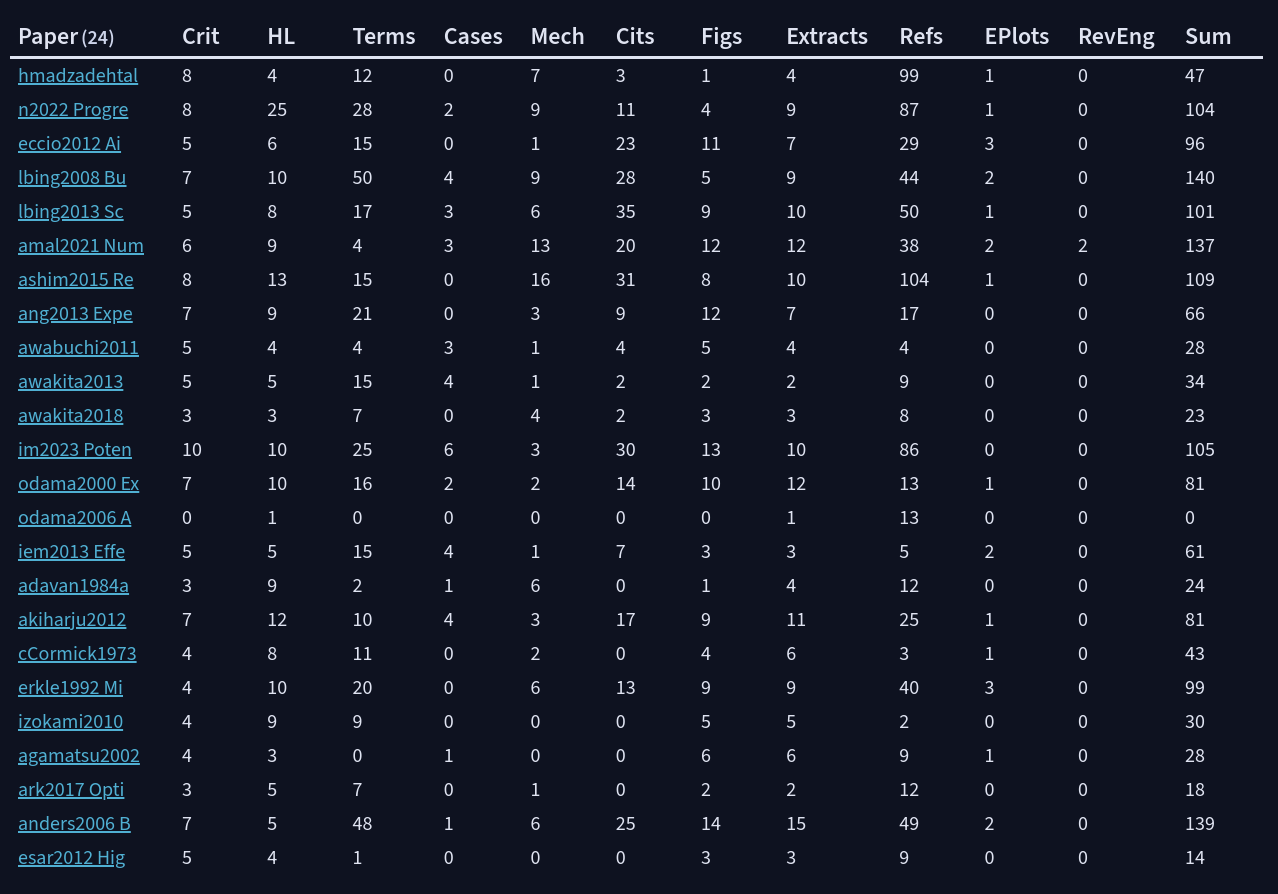
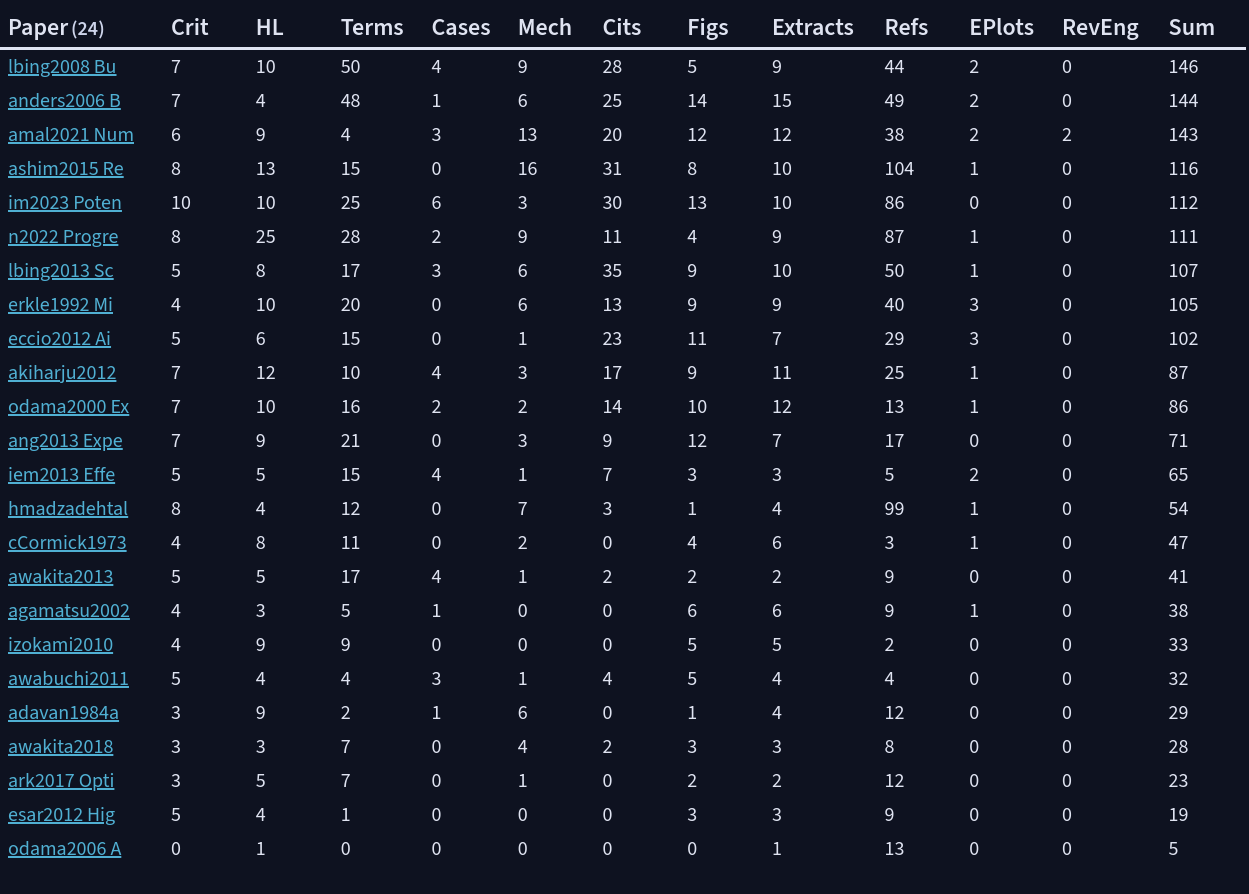
Sort of I could make a ranking by the amount of exploration and extractions on a literature source. A paper rating wouldn’t be as subjective anymore.
This is the script for the output:
function countPropertyValue1LD(page, propText) {
return page.file.inlinks.values
.filter(f => dv.func.contains(dv.page(f.path).related,
dv.func.link(propText))).length
}
function referenceLink(page, str) {
let values = page.file.inlinks.values
let filtered = values
.filter(p => p.path.contains(str))
return filtered
}
function numOfRefs(page, str) {
let filtered = referenceLink(page, str)
return filtered[0]?.path ?
dv.page(filtered[0]?.path).file.lists.length : 0
}
function numOf(property) {
return !property ? 0 : typeof(property) == "string"
? 1 : property.length
}
function numFigures(page) {
const embeds = page.file.outlinks
.where(p => p.embed)
.where(p => p.path.substr(p.path.length-3) == "png" )
return (embeds.length)
}
function numListElem(page, section) {
let values = page.file.lists.section.subpath.values
return values ?
values.filter((w) => w === section).length : 0
}
async function numCallouts(page) {
const regex = />\s\[\!(\w+)\]\s(.+?)((\n>\s.*?)*)\n/
const file = app.vault.getAbstractFileByPath(page.file.path)
const contents = await app.vault.read(file)
let count = 0
for (const co of contents.match(new RegExp(regex, 'sg'))) {
count = count + 1
}
return count
}
let pages = dv.pages('"Sources"')
dv.table(
["Paper", "Crit", "HL", "Terms", "Cases", "Mech", "Cits", "Figs",
"Extracts", "Refs", "EPlots", "RevEng", "Sum"],
await Promise.all(
pages
.where(page => page.type == "paper")
// .sort(page => page.file.name, 'asc')
// .sort(page => page.z_rating, 'desc')
.map(async page => [
dv.fileLink(page.file.name, false, dv.func.substring(page.file.name, 1, 13)),
numListElem(page, "Critique"), // section, list
numListElem(page, "Highlights"), // section, list
numOf(page.term), // properties
numOf(page.case), // properties
numOf(page.mechanism), // properties
numOf(page.paper), // properties
numFigures(page), // outlinks, embed
await numCallouts(page), // regex
numOfRefs(page, "References"), // inlinks, 1LD, filename, list
countPropertyValue1LD(page, "essential plots"), // inlinks, 1LD, property
countPropertyValue1LD(page, "reverse engineering"), // inlinks, 1LD, property
numListElem(page, "Critique") + numListElem(page, "Highlights")
+ numOf(page.term) + numOf(page.case) + numOf(page.mechanism) + numOf(page.paper)
+ numFigures(page) + await numCallouts(page)
+ Math.round(Math.log(numOfRefs(page)+0.1)+0.5, 0)
+ countPropertyValue1LD(page, "essential plots") * 10
+ countPropertyValue1LD(page, "reverse engineering") * 20
]
)
)
)
My question is: how would I be able to sort the papers by the column Sum, if Sum is the weighted total of the rest of the columns which is made of a bunch of formulas?