Things I have tried
Searching multiple posts, forums, and github for some help.
What I’m trying to do
I am trying to do what is shown in the first post of this Github ticket.

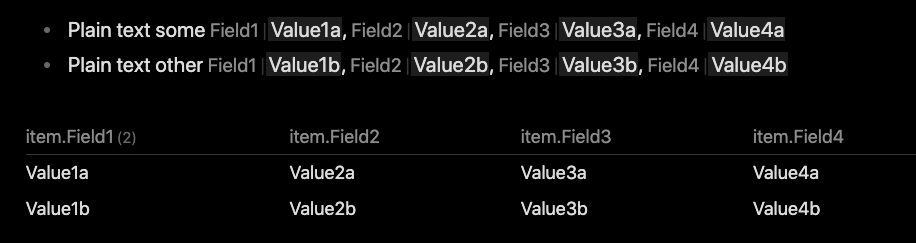
I have a file with multiple inline fields with the same label, but different values. I cannot split these into separate files; They need to remain in a single file. Yet I need to have a Dataview table which can display each one of them on a separate row.
One thing to mention that I am doing different than the github ticket/image above: Each of my inline fields are strung together on a single line, and therefore I want each of these comma separated inline fields to be its own column, with also one column being the non-inline text on that same line (if that’s not possible, I can make it an inline).
Example: (fields named the same, values change per row)
- Plain text some [Field1:: Value1a], [Field2:: Value2a], [Field3:: Value3a], [Field4:: Value4a]
- Plain text other [Field1:: Value1b], [Field2:: Value2b], [Field3:: Value3b], [Field4:: Value4b]
I’ve heard that Dataview itself is not (yet) capable of doing this on its own, so DataviewJS is required instead. I am currently at a loss as to how to start writing a query that performs this described workflow. Can anyone help me out please?