Things I have tried
The problem that I meet is, when using Chinese, the unicodes on the left column look almost the same to the ones in the right column. And the ones on the right, which start with \u2f, are seldom used.
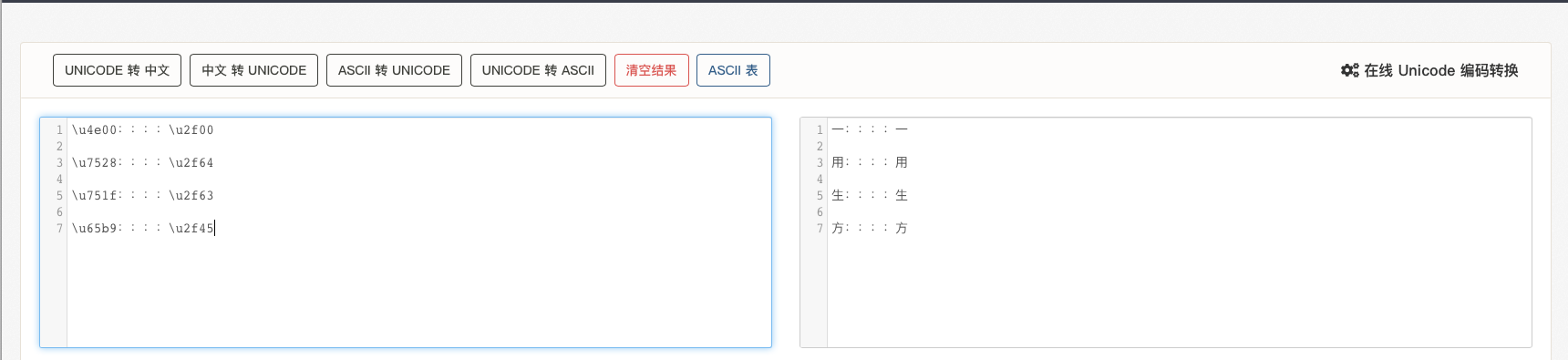
\u4e00::::\u2f00
\u7528::::\u2f64
\u751f::::\u2f63
\u65b9::::\u2f45
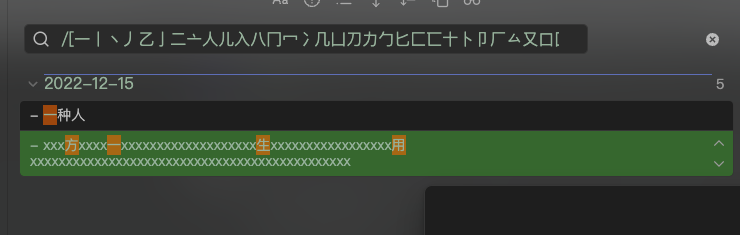
(the screenshot of the result of the unicode-to-Chinese conversion)
However, due to some reasons, OCR, I guess, some of the Chinese characters in my notes are actually wrong(i.e. they should be the characters whose unicode does not start with \u2f). It is not possible to identify them in the note, as when you reading the note, they just looks the same. However, when you do the search, that will be a huge problem, i.e. the one you searched and the one that you read in the note will never be matched.
And since there are a lot of characters, I cannot search and replace them base on the codebook.
What I’m trying to do
I think one possible way to fix this problem is to identify the appearance of the unicode start with \u2f in my vault in the first step. I think, optimistically, the total number of the appearance will not be large. And then, a manual fix can be applied to each of the appearances by delete the wrong character and re-input the correct character and probably in Obsidian to get rid of breaking the links.
My question is how can I accomplish the first step? i.e. to find all the appearance of the unicode starting with \u2f in the range of a folder including sub-folders(such as the vault).