Hello,
I wasted a fair bit of time during the year creating & maintaining a glossary for my first year of study in my degree. Towards the later part of the year I came to learn that I could link directly to the macOS dictionary app via [term](dict://term). I also managed to successfully install a medical terms dictionary into the app.
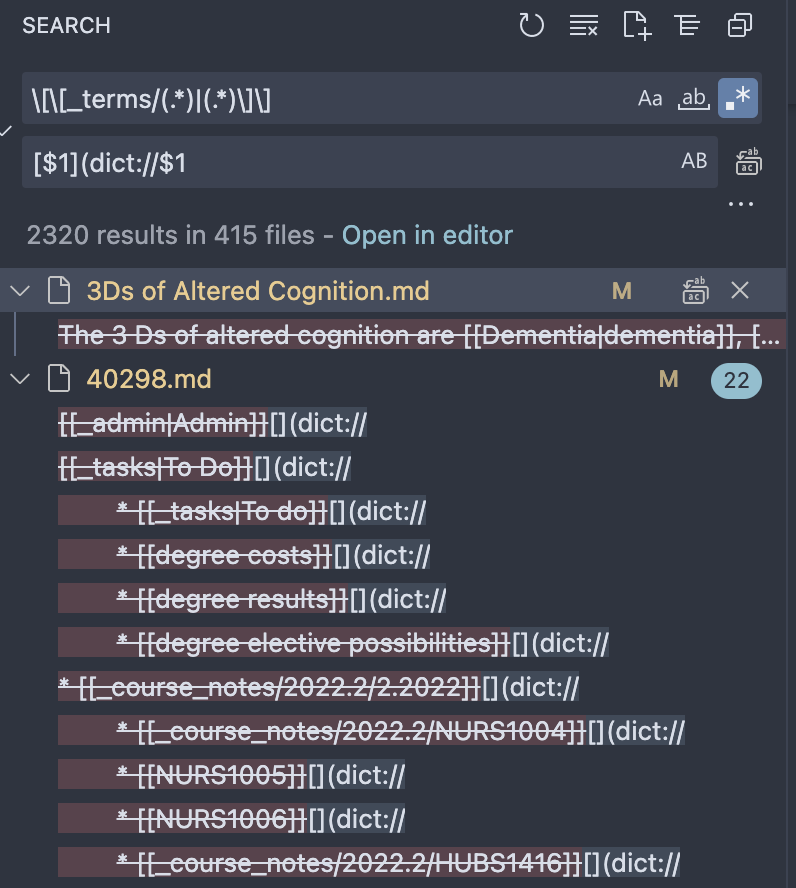
My study vault now contains a mixture of links to my own glossary & those to the dictionary app. I’d like to standardise them all to the dictionary app. This will require refactoring links from [[_terms/Term|term]] to [term](dict://term).
Without the pipe & alias I could probably achieve this with search & replace that changes [[_terms/Term]] to [term](dict://term) but the pipe & alias complicates things. If I could replace |term]] with nothing using regex I could do that but I would need to restrict it to only links to the _terms subfolder, otherwise it’ll ruin other normal inter-note links.
Could you elaborate on what platform and which editors you’ve got? It shouldn’t be that hard to write a regex todo this for you given some proper tools.
If you in addition give some actual examples of terms to be replaced and their replacement I reckon someone will be able to assist you.
Hi, I’m just reading up on capture groups in VS Code. I’m on macOS and usually use VS Code for search & replace.
Some examples are (they’re all words, no special characters or symbols or numbers): [[_terms/Pyrexia]] [[_terms/Thrombophilias|thrombophilias]] [[_terms/Miasma|miasmas]]
I’m very much a beginner at regex, just reading through @I-d-as linked post above.
Dictionary links are case-insensitive. All entries in the dictionary for non-proper-nouns are lower case. Both the below work;
I’m thinking this could be accomplished in 2 steps. First, to go through and replace the |term part of all links that start with [[_terms/ with nothing. But it is important that all your links are properly closed with ]], otherwise it could be destructive. Then the second step would be doing the regex search and replace using capture groups. I want to double check that it works before I post what I’m thinking.
It shouldn’t be a problem to do this in just one step. If the regex is specific enough, and you don’t necessarily do replace all, it should be safe to do.
I have a backup
But I don’t understand, if you do it in two steps as you describe, how to determine |term' in my glossary from |aliasin my normal links. The path_terms/` is the differentiator.
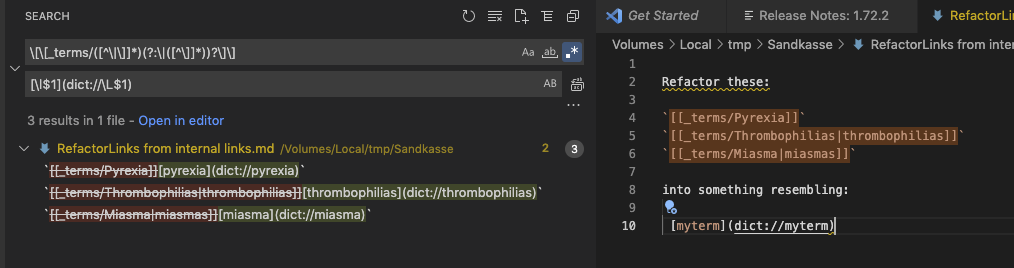
Maybe search \[\[terms\/(.*)\|.*\]\] and replace with [$1](dict://$1) the first time around thus taking care of those with pipes. Then the second round search \[\[terms\/(.*)\]\] and replace [$1](dict://$1) but this is just a guess. On my phone and can’t really test.
What this aims to do is search for something which in order is:
\[\[_terms/ – Always starts with this text
([^\|\]]*) – a capture group of anything up until either a | or a ] bracket character, properly escaped (which makes the regex read a lot harder… )
(?:\|[^\]]*)? - an optional non-capturing group with the lead-in character of | followed by anything until the next ] character
\]\] – always ending with a double bracket
When it comes to the replacement part it’s simpler:
[\l$1] – Place the first capture group within the brackets as the name of the link, with the first character lowercase, \l
(dict://\L$1) – And then the actual link also with the first capture group, with the entire group lowercased, \L
Feel free to interchange or use whatever to lowercase, either both or none of them. Just wanted to place them there to show some options.
Preserving the case of your original term would be a little harder, as one one need to change the capture group to be the latter part of the regexp. It is possible but harder. The proposed solution might arise a few issues when your search term is at the start of a sentence, and you do want it to have an uppercase character at front.
A final note on the usage of character classes, i.e. [^\|\]]* and [^\]]*, instead of the ordinary wild card, .: I tend to use this more specific approach to limit my regex so they don’t get overly greedy, and expand into other cases which could occur on the same lines and so on. Just a matter of precautions, which I’ve gotten accustomed to.