I still think you’ve been given enough information so that you should be able to sort this out yourself, but I’m going to try to explain is just once more.
With your files QTest and QTest2 try the following queries in a note of their own:
## Base data
```dataview
TABLE WITHOUT ID descripcion, R.fecha, R.horas
FROM #actividad
FLATTEN registros as R
```
## GROUP BY descripcion
```dataview
TABLE WITHOUT ID descripcion, R.fecha, R.horas, rows.R.fecha, rows.R.horas
FROM #actividad
FLATTEN registros as R
GROUP BY descripcion
```
### Limited to a given date
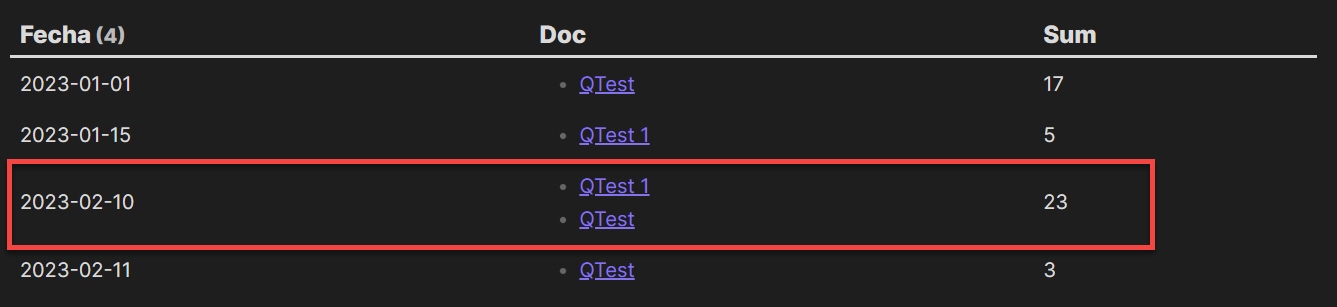
```dataview
TABLE WITHOUT ID descripcion, rows.file.link, sum(rows.R.horas)
FROM #actividad
FLATTEN registros as R
WHERE R.fecha = date("2023-02-10")
GROUP BY descripcion
```
For me this produces this output:
Notice how I start with a query to ensure I’m seeing the data I would like to see, with one line per registration. Achieved by the FLATTEN registros as R line.
Next I group on what I want to group on, e.g. descripcion, and notice that my R.fecha has moved into a list of rows.R.fecha and so on. But you also said you wanted to check for a given date, and that needs to be done before the sum (and grouping), so the third version does that, ands back in the link of the file where the description was.
Do however note the following. Making the query like this kind of limits you to only showing one date, and you’re also limiting each file to only have one description.
So I still think the format I suggested earlier on, using something like:
---
registros:
- tarea: Healthcheck
fecha: 2022-02-10
horas: 3
- tarea: Healtcheck 1
fecha: 2022-02-11
horas: 10
---
Is a superior format, as it’ll give the option to have different tasks in the same file, whilst keeping a connection to the description, and it’ll make the queries slightly easier, as you’ll not need to group/flatten/re-group/re-flatten to do some of the queries which you indicate you want to do.
Given a format like the last example, you could get a query and result like the following:
```dataview
TABLE length(rows.R.fecha) as "Recuento de tareas", sum(rows.R.horas) as Sum
FLATTEN registros as R
WHERE registros
GROUP BY R.tarea
```
With the result:
Do however, note that since this is grouping on descriptions potentially across multiple files, there is no easy way to link to the origin file of any given registration. But that is most often the case when you opt to group results together potentially from multiple files.
You can still add something like rows.file.link to this query, and get the list of the files. However, that might again list multiple registration from any given file multiple times, so I would have most likely switched to a dataviewjs query to loose those duplicate listings.