TABLE WITHOUT ID Tasks.from AS "from", Tasks.to AS "to", regexreplace(Tasks.text, "\[.*$", "") AS Milestone, Tasks.link AS "date Milestone created"
FROM #milestone
WHERE file.tasks FLATTEN file.tasks AS Tasks
WHERE !Tasks.completed
GROUP BY file.name
What I’m trying to do
I’d like create a dataview table as an overview of all my milestones of all projects.
As mean which appeared to me most usable for that goal, I use dataview-query on task-level, because I note my milestones as Tasks during telefon-calls within my different project-protokol-notes.
The syntax of my noted milestones look like this:
[ ] my milestone, I noted during my call [from:: 2022-06-28] [to:: 2022-06-30] #milestone
I’d like to have my table to look like this:
column: Beginning of milestone
column: End of milestone
column: title of milestone
column: link to the section of the note, where I noted that milestone
The table works fine, without the “group by” line in my code above. But I’d like to have my milestones grouped by the projecte-name, which is equal to the filename, in which I’ve noted my milestone…
I hope that was not too confusing, english is not my mother-tongue.
Hi SiliasOS,
Thanks for sharing what you tried. When you use a GROUP BY, the names of the fields in your first line change to have rows. in front of their names. I have added some extra spaces and line-breaks below to make it easier to read in the forum, those are all optional.
TABLE WITHOUT ID
rows.Tasks.from AS "from",
rows.Tasks.to AS "to",
regexreplace(rows.Tasks.text, "\[.*$", "") AS Milestone,
rows.Tasks.link AS "date Milestone created"
FROM #milestone
WHERE file.tasks
FLATTEN file.tasks AS Tasks
WHERE !Tasks.completed
GROUP BY file.name
Does this work for you? If not, what happens? Do you get an error message? A blank table? Or something else?
In the version with the Group By but minus WITHOUT ID, is the first column still called “file” and does it have the same “dot” in front of each cell as the other columns in the Group By results?
TABLE
Tasks.from AS "from",
Tasks.to AS "to",
regexreplace(Tasks.text, "\[.*$", "") AS Milestone,
Tasks.link AS "date milestone created",
file.name
FROM #ms
WHERE file.tasks FLATTEN file.tasks AS Tasks
WHERE !Tasks.completed
SORT Tasks.due ASC
TABLE WITHOUT ID
rows.Tasks.from AS "from",
rows.Tasks.to AS "to",
regexreplace(rows.Tasks.text, "\[.*$", "") AS Milestone,
rows.Tasks.link AS "date milestone created"
FROM #ms
WHERE file.tasks FLATTEN file.tasks AS Tasks
WHERE !Tasks.completed
GROUP BY task.file.name
SORT Tasks.due ASC
TABLE
rows.Tasks.from AS "from",
rows.Tasks.to AS "to",
regexreplace(rows.Tasks.text, "\[.*$", "") AS Milestone,
rows.Tasks.link AS "date milestone created"
FROM #ms
WHERE file.tasks FLATTEN file.tasks AS Tasks
WHERE !Tasks.completed
GROUP BY task.file.name
SORT Tasks.due ASC
TABLE WITHOUT ID
rows.Tasks.from AS "from",
rows.Tasks.to AS "to",
regexreplace(rows.Tasks.text, "\[.*$", "") AS Milestone,
rows.Tasks.link AS "date milestone created"
FROM #ms
WHERE file.tasks FLATTEN file.tasks AS Tasks
WHERE !Tasks.completed
SORT Tasks.due ASC
For all of these you almost certainly want to put your SORT before your GROUP BY. Or if you put a SORT after a GROUP BY, it needs to sort by rows. whatever!
Aha! The - in the Group column means that it is not finding the file name to group by! Does GROUP BY file.name instead of task.file.name produce a different result in that first column?
FYI: Your fourth table image is showing all blanks because you forgot to remove the rows. from the beginning of the query.
The dots come from how dataview handles GROUP and lists. If you have multiple rows in the same GROUP after your GROUP BY, then dataview is going to display their contents as a list, and it puts dots in front of list items. This helps keep clear which items go together. If you don’t like that behavior, you could experiment with combining the list into a string using the join function e.g. join(rows.Tasks.from, ' \n') AS "from" but I am not sure how that will affect dataview’s ability to display the rows.
When I use “file.name” instead of “task.file.name” it starts to look pretty!
Now that’s my code:
TABLE
rows.Tasks.from AS "from",
rows.Tasks.to AS "to",
regexreplace(rows.Tasks.text, "\[.*$", "") AS Milestone,
rows.Tasks.link AS "date milestone created"
FROM #ms
WHERE file.tasks FLATTEN file.tasks AS Tasks
WHERE !Tasks.completed
SORT Tasks.to DESC
GROUP BY file.name
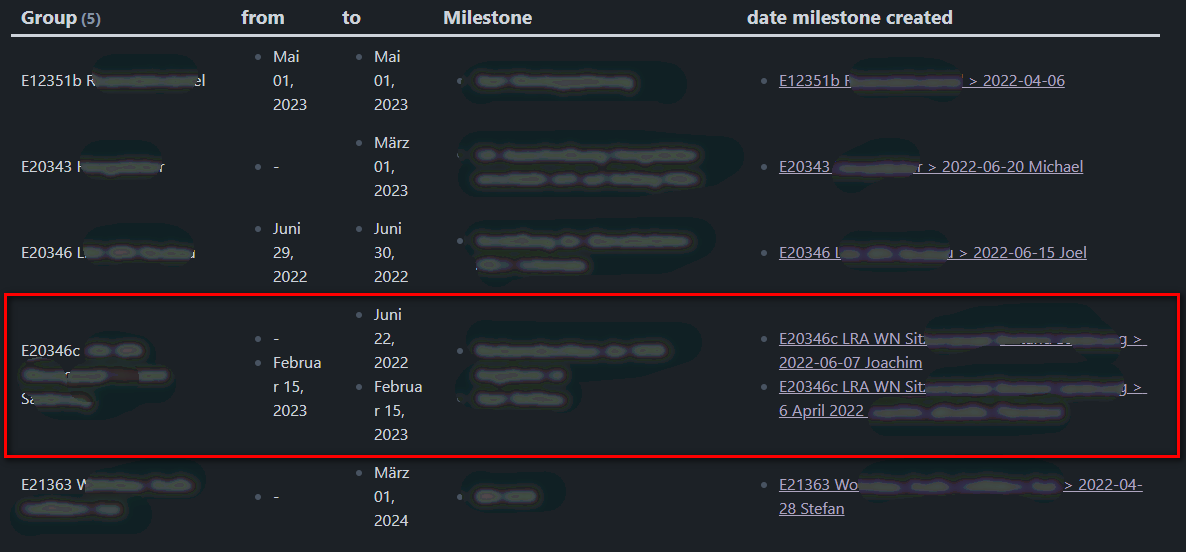
In total, now I have 6 milestones in my notes, out of 5 projects. => The grouping works, because in the first column, there are only 5 entries (my 5 projects). The only thing which is not so nice yet, is what you can see inside the red square:
These are the two milestones, which belong to the same project - so far so (very) good! What I’d still like to adjust is, that the entries of the first milestone (the first dot in column 2-5 inside the red square) are all on the same level/heigth, across the rest of the columns…
Do you have also a solution for that?
Thanks so much so far!!! You already helped me a lot!
also a change in date-format would help to have a clearer layout of the table.
So, instead of the date-format “Februar 15, 2023” the date-format “2022-02-15” would help to make the table look more structured.
Is it possible to change that format?
First, check your Dataview settings for the default date format and see if it is how you would most frequently like dates to be displayed. I have mine set to display dates as “2022-02-15” for the default, which is a string of “yyyy-MM-dd” in the settings. (Note the caplitalization matters and is different from what you might set elsewhere in obsidian.)
Second, if you want the items in this table different from your default date format: There is an undocumented Dataview function dateformat(date, luxon-date-format-string).
Example: dateformat(rows.Tasks.from, "yyyy-MM-dd") AS "from"
In general, no, I have no idea. You can experiment with making the name of your columns different lengths, which may change things a little. e.g. if add a couple letters to the name of the column currently named “to” that might help a little. But that is not very precise, and I don’t know how to do better.