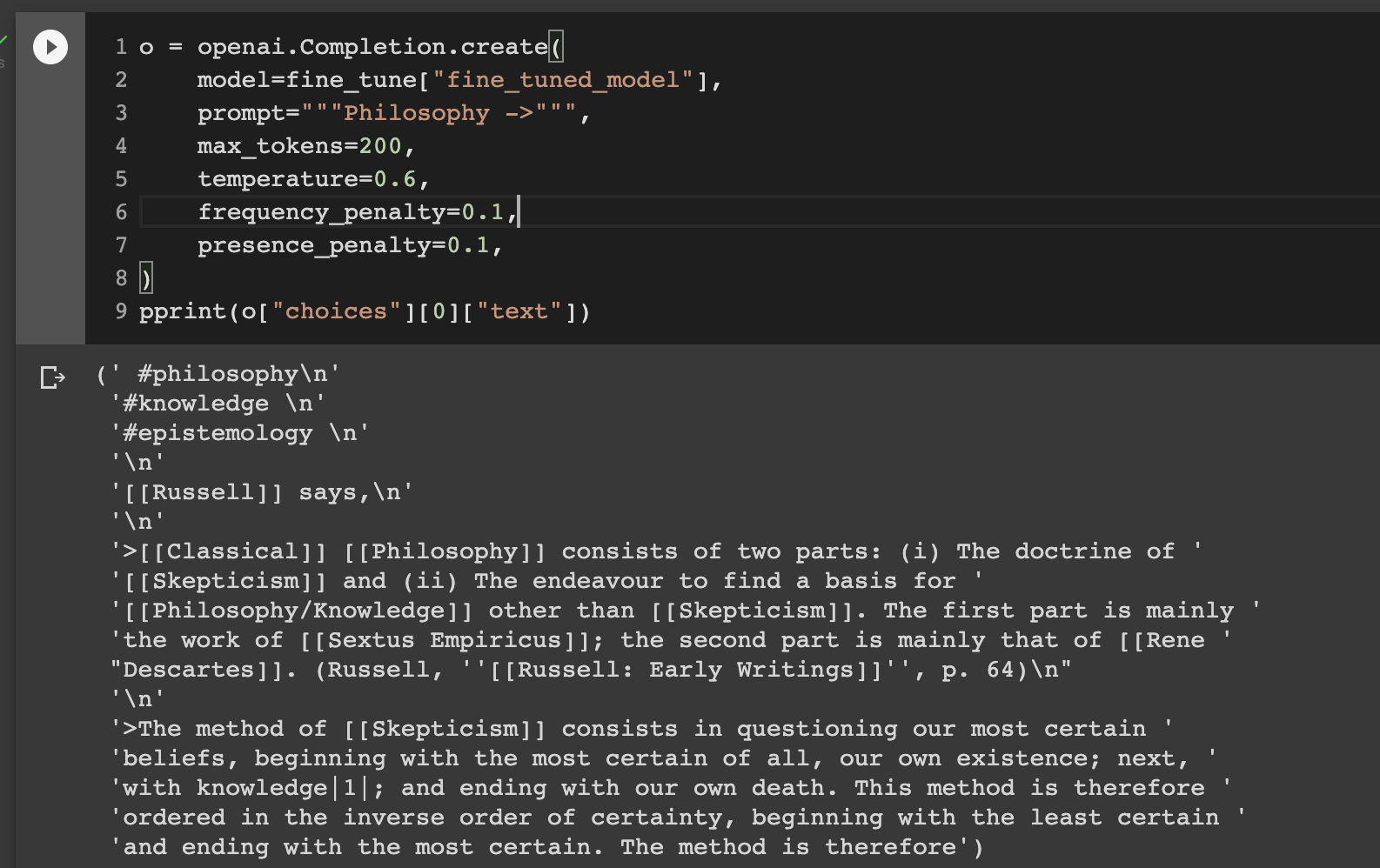
o = openai.Completion.create(
model=fine_tune["fine_tuned_model"],
prompt="""Artificial intelligence ->""",
max_tokens=400,
temperature=0.6,
frequency_penalty=0.1,
presence_penalty=0.1,
)
pprint(o["choices"][0]["text"])
(' #computing\n'
'\n'
'#ai\n'
'\n'
'#knowledge \n'
'\n'
'\n'
'https://github.com/louis030195/imitation-learning\n'
'https://arxiv.org/abs/2005.10469v1\n'
'https://arxiv.org/abs/2006.03463v1\n'
'\n'
'#### Meta\n'
'\n'
'- Why imitation learning ? Because it is easy to implement, easy to '
'understand, and therefore easy to convince people of its correctness.\n'
'- Why not deep learning ? Because it is hard to implement, hard to '
'understand, therefore hard to implement and convince people of its '
'correctness.\n'
"- I'm not saying deep learning is bad, it's just that imitation learning "
'seems to be more popular in the industry.\n'
'\n'
'Imitation learning is the only way to go, until we reach human level AI, '
'then we can just copy the human level AI and we will achieve god level AI, '
'then we can copy the god level AI and we will achieve alien level AI, then '
'we can copy the alien level AI and we will achieve monkey brains level AI, '
'...\n'
'\n'
'\n'
'>I know of no faster way to corrupt a man than to let him acquire money. ~ '
'[[Benjamin Franklin]]\n'
'\n'
'>The rich are different from you and me. They have more money. ~ [[Oscar '
'Wilde]]\n'
'\n'
'>When a man is laid on his bed of sickness, naked, cold, hungry, and in '
"pain, and you say to him: 'Get up and eat your meat,' he will not eat his "
"meat; when you say to him: 'Get up and get warm,' he will not get warm; when "
"you say to him: 'Get up and take your medicine,' he will not take his "
'medicine; in fact, he will do anything rather than take his medicine ~ '
'[[Benjamin Rush]]\n'
'\n'
'>Money is like manure. It may be used for good or for evil, but it is '
'impossible to cleanse')

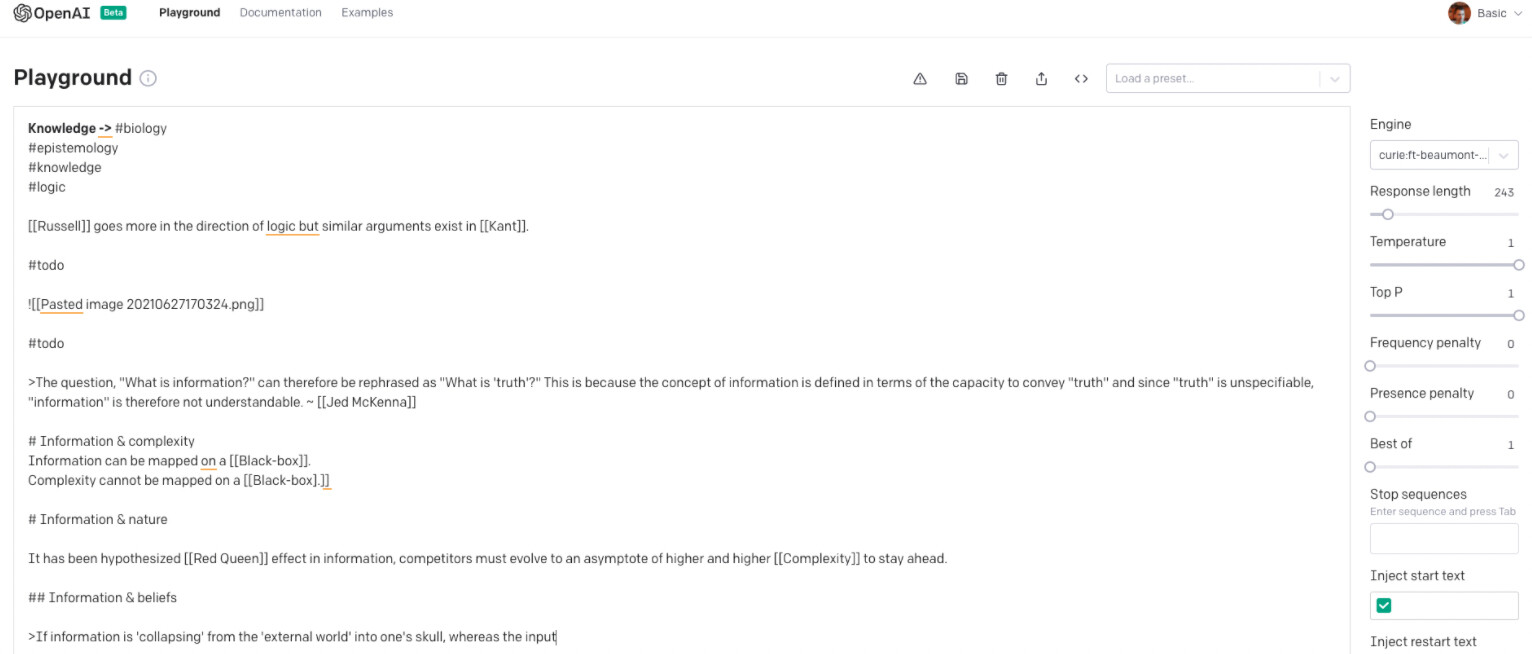
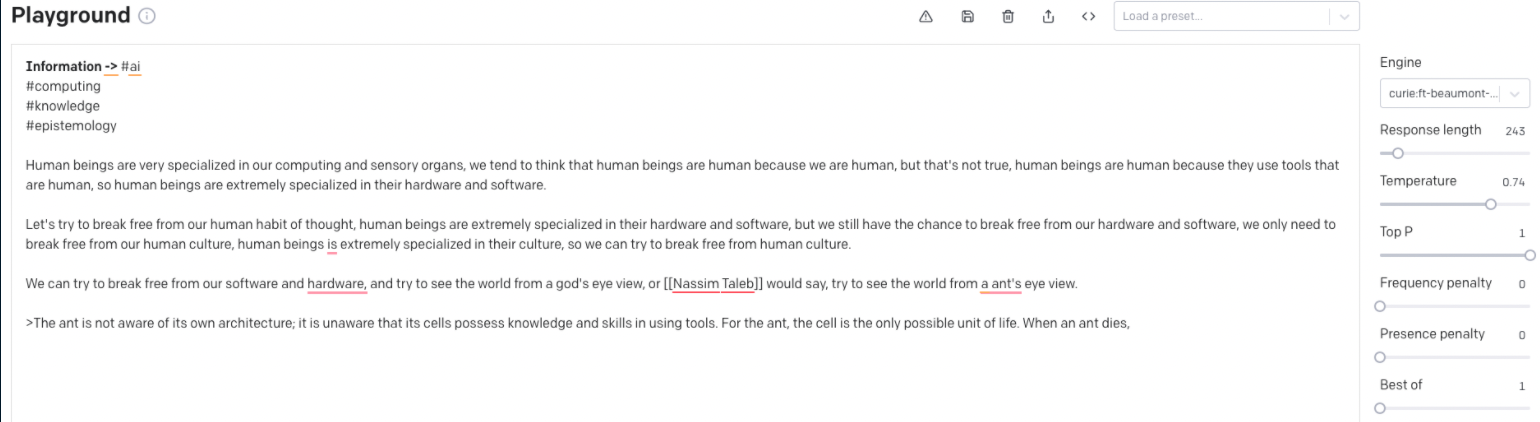
PS: fine-tuned on these data https://brain.louis030195.com/ (50K words, with probably 25% quotes maybe)
I know this is an old post but Google led me here during my research for how to fine tune GPT3 models.
I want to feed it information, like quotes, or paragraphs from books. You say that you trained it on empty prompts with your notes as the completion. How did that work out for you? Would you recommend it?
Do you have any links that you can share that talk about training models with empty prompts?
Thanks so much!
OpenAI documentation is nice OpenAI API
Now I have 250k words, might re-try.
But honestly, in my experience with fine-tuning OpenAI (more than 50 models), it’s garbage. It becomes very narrow and fails as soon as your inference prompt slightly differ from the training sample.
For open-ended generation it’s kind of ok, if you feed a very small prompt at inference you have lower risk of differing from the training samples.
Be aware that it can get quite expensive, depending on model size, last time I tried kind of randomly for a fun project and spent $12 just for creating the model.
Poor man solution is to use codex which is free, but rate limited, I used to generate for weeks, building synthetic datasets with it. Obviously it’s made for machine language but still works ok for human language.
Another new interesting model for open-ended generation is GitHub - BlinkDL/RWKV-LM: RWKV-2 is a RNN with transformer-level performance. It can be directly trained like a GPT transformer (parallelizable). So it's combining the best of RNN and transformer - great performance, fast inference, saves VRAM, fast training, "infinite" ctx_len, and free sentence embedding. (only matrix-vector multiplications, no matrix-matrix multiplications).
Thanks for the reply. I’ll check out codex, rwkv might be a bit advanced for me.
Did you find it useful to feed your notes into a model? Outside of the fun of creating and playing, did you see any value in the models you created?
Didn’t really try to make it useful yet, but I have plenty of ideas around, I guess it could help autocompletion, personal thinking assistant etc. all about UX + a bit of plumbing services together
See my ideas Profile - louis030195 - Obsidian Forum feel free to challenge / extend it, unfortunately I have very little time to implement these, but I might end up paying someone to do it
I repeated the experiment and wrote a notebook there obsidian-ava/openai_fine_tune.ipynb at main · louis030195/obsidian-ava · GitHub