I would like to export my vault data to an Excel file. By doing so, I aim to gain a comprehensive view of my vault, which will facilitate better decision-making, enhance operational efficiency, and enable effective pattern recognition. Excel’s interface, along with its features such as sorting and functions, will aid in achieving these objectives.
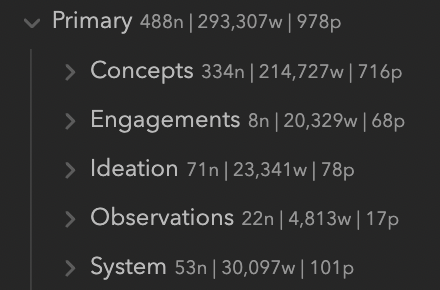
Here’s an outline of my vault. Plugin: Novel Word Count.
(Number of Notes | Word Count | Approximate Page Count From Word Count)
I want this information: Note Name;
Parent Folder;
Note Title Word Count;
Note Title Character Count;
Note Word Count;
Note Character Count;
Page Count From Word Count
I greatly value any assistance provided, as this particular situation is highly specialized and falls outside my expertise as a non-programmer. Any piece of code that you may support me with would be invaluable to me, you’d be essentially supplying the very building blocks that will shape and define my path ahead allowing me efficiency in operation and saving me precious time. Your contribution plays a pivotal role in establishing a strong and sturdy starting point, allowing me to embark on my journey and life path with confidence and clarity converting fully from Notion to Obsidian.
Those marked with are readily available within a normal DQL query. Those marked with can be calculated relatively simply (and precise). All of these are available from the metadata associated with the note.
The last two, however, are not so easy to get at. (At least I don’t think the word count is readily available) The script you refer to are reading through the entire file, and doing some text manipulation to be able produce some numbers.
My question and/or suggestion is related to how precise do you need these number to be? I’m thinking that if you are satisfied with some ballpark numbers, it’ll be a lot easier to just use the file length/size, and divided by the average number of characters to get an approx word count, and then divide that number again by an average of how many words per page for the page count. (These numbers you’d need to find for your native language)
In either case (both with a script sing the “accurate” guesstimate, and calculations on file size) the word and page count will likely be incorrect due to factors as the words being present in the frontmatter, code examples, queries and/or other markup not directly being the visual content of your notes.
Holroy, thank you so much for your help. I am grateful that you took a bit of your time to help my cause.
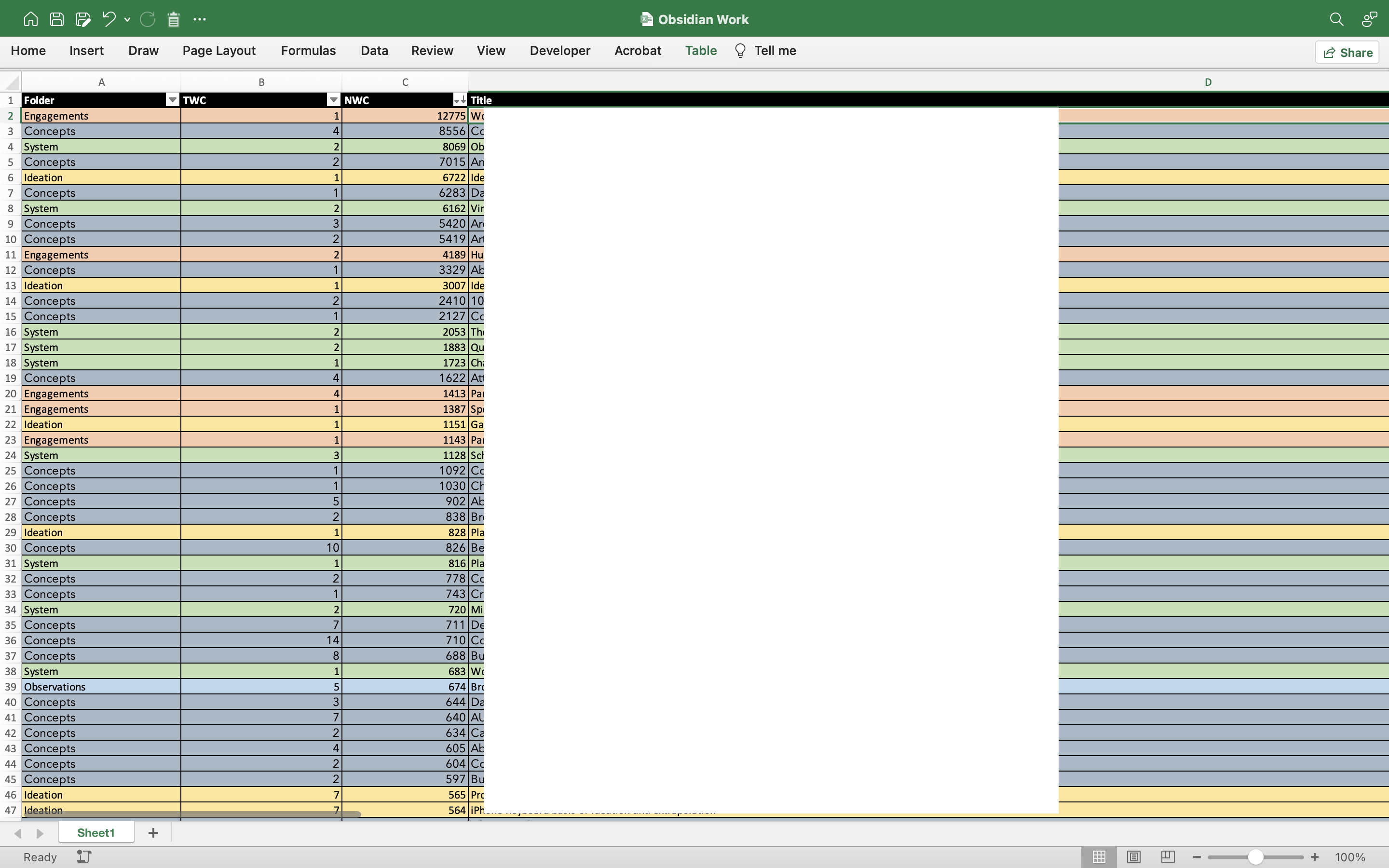
I have employed a manual solution.
Sort files in Finder descending by size then use the app “Renamer” to automatically enumerate all files. The goal is to change their order also in the Obsidian pane.
Select all, copy, then hit Shift+Option+Command+V to paste only the file names in an rtf or txt file. Since Obsidian is built on top of a local directory, in mac you can do this. This is to batch paste onto Excel.
Then It was manual copy paste from there, batch working where I could. But that initial sorting made things easier.
As for the Title word number I used this excel function
=LEN(TRIM(D2))-LEN(SUBSTITUTE(D2," “,”"))+1
The results when processed and ordered look something like this.
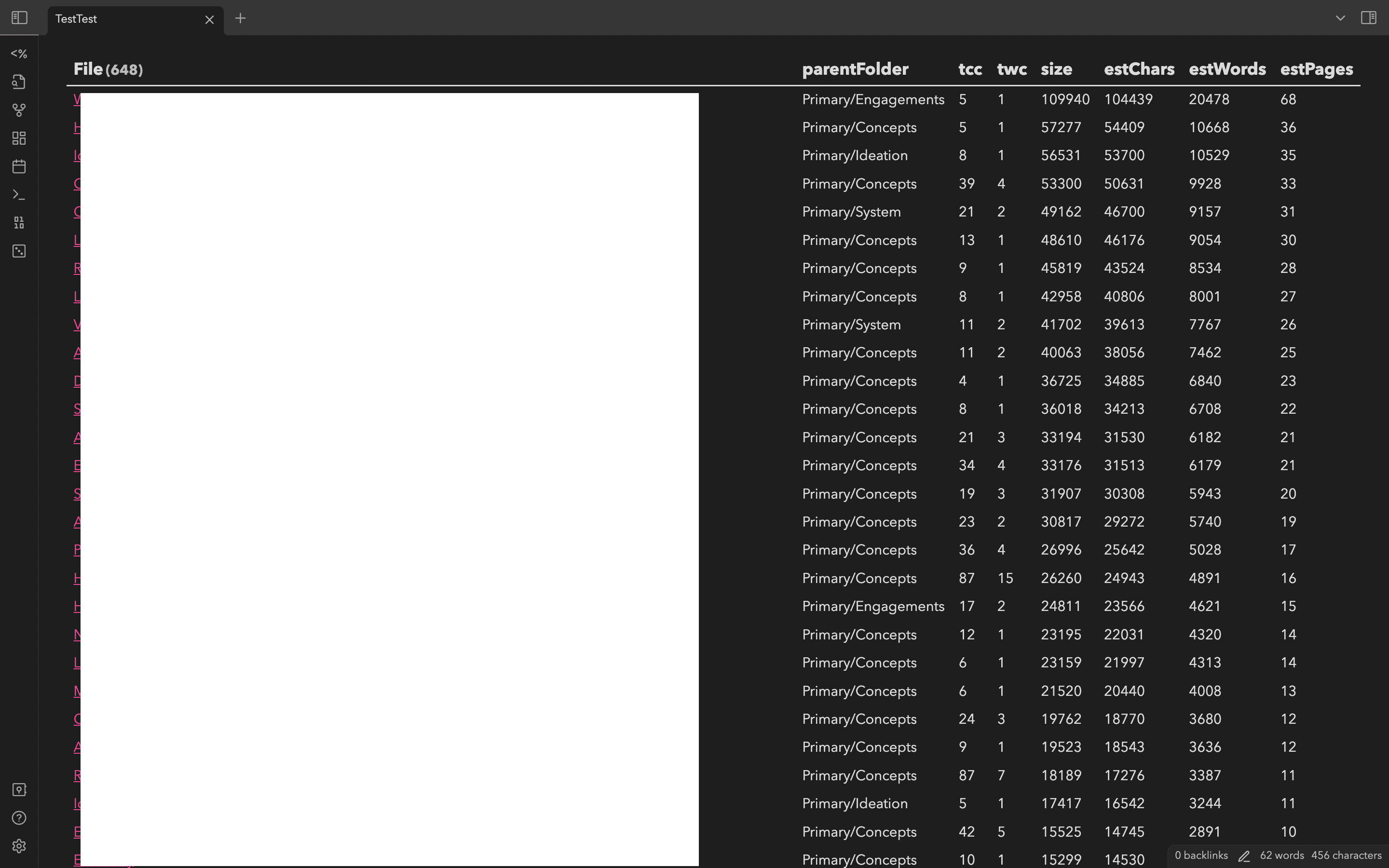
Just for the fun of it, I wrote out the estimation query to be fully contained within Obsidian, and it looks like this:
```dataview
TABLE
parentFolder,
tcc,
twc,
file.size as size,
estChars,
estWords,
estPages
FLATTEN regexreplace(file.path, "/?[^\/]+$", "") as parentFolder
FLATTEN length(file.name) as tcc
FLATTEN length(split(file.name, "[ _\.]")) as twc
FLATTEN round(0.95 * file.size - length(string(file.frontmatter))) as estChars
FLATTEN round(estChars / 5.1) as estWords
FLATTEN round(estWords / 300) as estPages
SORT file.size DESC
```
There are some parameters to be tweaked in this query:
I’m guessing that 95% of the characters are actual content, so this is used to reduce the file.size along with subtracting the size of the file.frontmatter into the estChars (aka actual content characters, not including markup). This might wary depending on how much metadata you add or not into your files. This also used as the base for the other estimates, so the “fault” will carry through
In the english language it seems like the average word length is 5.1, so that is used to get the estWords
Finally, the average word on a page varies depending on line spacing, and what not, so I used 300 (the same as in the Novel word count plugin by default). This gives us the estPages variable
You could compare the output of this table versus some of the files reported using Novel word count, and try to adjust them somewhat. However, this is and will be guesswork as long as we’re not reading every file of the vault. I still think it could have some value since it kind of visualises the size of the various notes.
Thank you immensely! The estimation you provided is amazing, and the usability of this tool is fantastic.
This solution demonstrates the efficiency and added value of having real-time updates. It made me realize the benefits of not solely relying on an externalized spreadsheet,
which makes me reconsider my approach being exposed to the advantages of integrating real-time data into my workflow.
Following your advice, I have compared the output with the manual work I performed, and I must say it is closely accurate. I will definitely follow your suggestion to experiment with different numbers.
I just want to iterate how incredibly grateful I am. I truly appreciate the time and effort you put into assisting me. I can’t thank you enough for going the extra mile with me.