Hey all ![]()
A lot of you have insanely polished Obsidian + reading setups. Mine… isn’t (yet). I’m building a plugin to reduce the friction and would love to learn from your battle-tested habits before I lock in the storage layer.
I’ve embedded the Zotero reader (PDF / EPUB / HTML snapshot) directly inside Obsidian—no Zotero DB/API calls. Everything (reader + highlights) lives in the vault and syncs like normal. Basic highlighting & annotations already work:
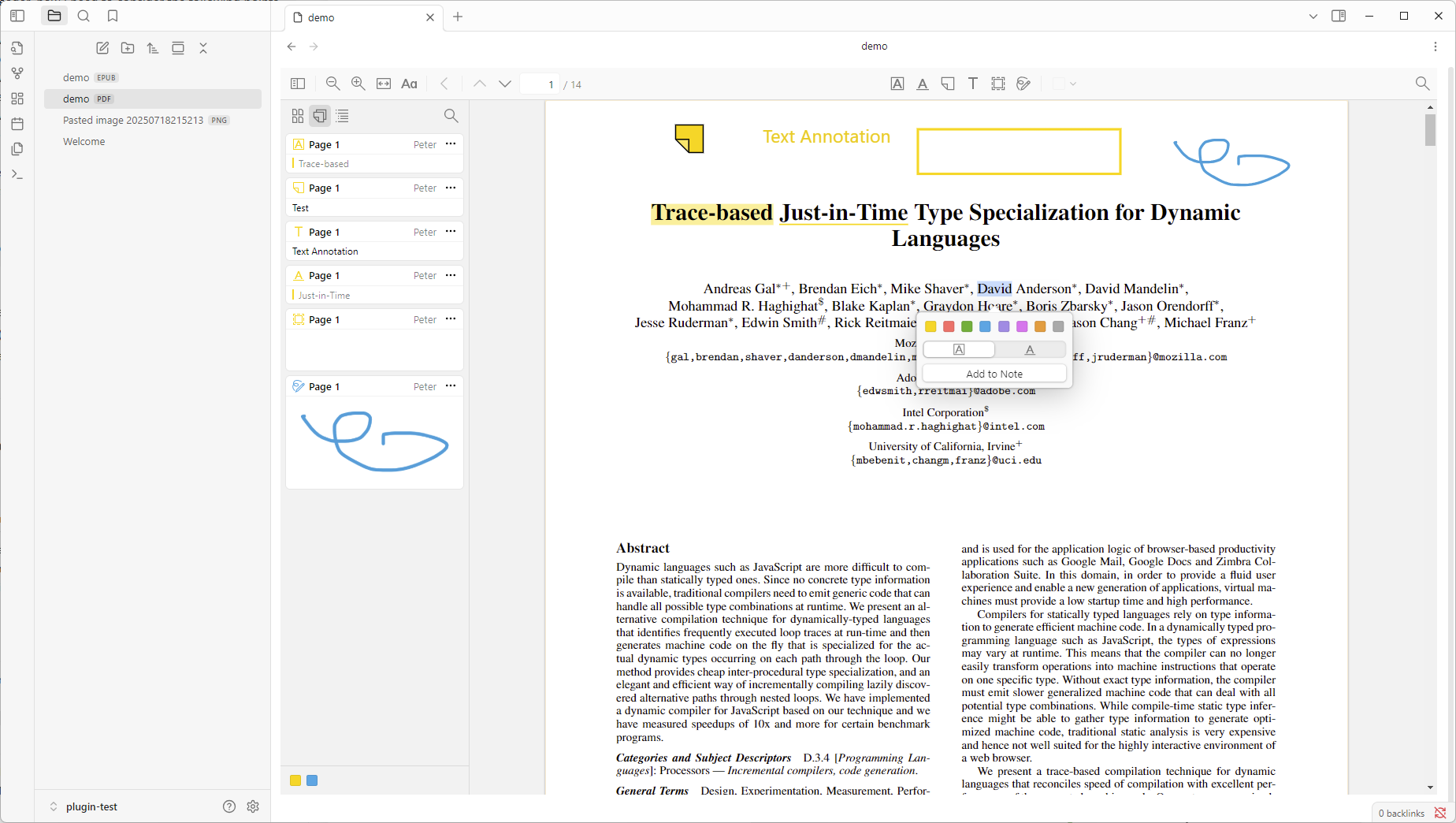
What I need from you: How are you currently managing PDF highlights + Markdown notes? What’s working / painful?
Models I’m Considering
-
Single markdown file per source – every highlight as a block.
-
Hybrid “promote on interaction” – raw highlights (geometry + exact text) stay in a JSON file; a Markdown block (with block ref) is created only when you comment / tag / edit it.
-
One markdown file per annotation – maximal granularity, lots of tiny files.
-
All in JSON – plugin UI renders everything; minimal native Markdown surface.
Quick Questions (reply to any subset)
-
Your current setup (plugins, exports, scripts, manual glue)?
-
Biggest pain: giant notes, file explosion, merge conflicts, noisy search, performance, something else?
-
How often do you revisit raw, uncommented highlights?
-
Hidden JSON layer + selective Markdown: feels clean or confusing / opaque?
-
Linking preference: block refs inside one note vs separate tiny notes per annotation?
-
Any horror stories (5k+ line annotation notes or thousands of micro-files)?
-
Which model (1–4) best matches how you actually work—and why?
Huge thanks—I’m leaning heavily on the community’s deeper experience. Even a few bullet points or a rant helps shape the default I ship. ![]()